Проверка гипотез о различиях между долями и между средними значениями
Проверка гипотез о различиях между долями респондентов. Часто исследователю приходится решать следующую проблему. Предположим, все опрошенные подразделяются на две подгруппы. (Это могут быть представители двух независимо построенных выборок, например выборка из жителей Москвы и выборка из жителей Санкт-Петербурга, а могут - лица, различия между которыми выявились в ходе анкетирования представителей одной и той же выборки респондентов, например те, у кого есть, и те, у кого нет высшего образования.) Исследователь должен выяснить, одинаково или по-разному распределились ответы представителей этих двух подгрупп на какой-либо определенный вопрос анкеты.
Пример 12.6
Исследование предпочтений в одежде (данные условны)
Пусть, например, нас интересует, различаются ли доли тех, кто носит джинсы, в Москве и Санкт-Петербурге. Пусть в каждом из этих городов были построены репрезентативные выборки и проведены опросы. Предположим, были получены следующие результаты (табл. 12.21).
Таблица 12.21. Респонденты, которые носят и не носят джинсы, по данным опросов лиц в возрасте до 35 лет в Москве и Санкт-Петербурге, человек
|
Пользование джинсами |
Город |
Всего |
|
|
Москва |
Санкт-Петербург |
||
|
Носят |
160 |
120 |
280 |
|
Не носят |
40 |
80 |
120 |
|
Всего |
200 |
200 |
400 |
Мы видим, что в Москве носят джинсы 80% опрошенных, а в Санкт-Петербурге - лишь 60%. Но достаточно ли разницы в 20%, чтобы утверждать, что это не случайность, что вообще москвичи чаще склонны носить джинсы, чем петербуржцы?
Для ответа на этот вопрос воспользуемся знакомой нам статистикой z, имеющей стандартизованное нормальное распределение, которая помогла нам установить, что определенная в ходе другого опроса доля респондентов, осведомленных о новом продукте, значимо отличается от намеченного исследователем фиксированного значения.
Статистика для данного случая имеет следующий вид:
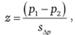 (12.16)
(12.16)
где p1 и р2 - доли носящих джинсы от числа опрошенных в Москве и Санкт-Петербурге (0,8 и 0,6 соответственно); - оценка стандартного отклонения разности долей р1 и р2.
Оценка стандартного отклонения разности долей рассчитывается по формуле
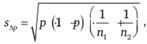 (12.17)
(12.17)
где р - доля пользующихся джинсами среди всех опрошенных в двух выборках; n1 и n2 - число опрошенных в Москве и Санкт-Петербурге соответственно.
Величина р рассчитывается по формуле
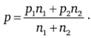 (12.18)
(12.18)
В нашем примере имеем:
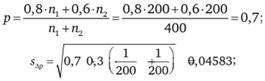
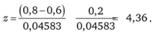
Поскольку нас интересует сам факт различия долей носящих джинсы в этих городах, а не превышения доли носящих джинсы в Москве по сравнению с такой долей в Санкт-Петербурге, нулевая и альтернативная гипотезы имеют вид:
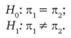
Поэтому при прежней доверительной вероятности 0,95 пороговое значение на кривой нормального распределения равно 1,96.
А поскольку 4,36 > 1,96, нулевая гипотеза отвергается, т.е. данные опросов не противоречат утверждению, что доли носящих джинсы в Москве и Санкт-Петербурге различны.
Проверка гипотез о различиях между средними значениями. Часто требуется определить, являются ли случайными различия между средними значениями некоторой величины, рассчитанными по ответам представителей двух разных подвыборок респондентов. Например, исследователя может интересовать, действительно ли жители Москвы оценивают некоторый товар выше, чем жители Санкт-Петербурга, если средняя оценка этого товара по пятибалльной шкале респондентами-москвичами выше, чем респондентами-петербуржцами.
Для проверки такого рода гипотез используется статистика Стьюдента с числом степеней свободы (n1 + n0 - 1), где п1 и n2 - число объектов (в данном случае - респондентов) в каждой из двух выборок:
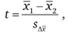 (12.19)
(12.19)
где 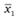 и
и 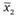 - средние значения оценок товара по данным опросов в Москве и в Санкт-Петербурге; - оценка стандартного отклонения разности интересующих нас средних значений между этими городами.
- средние значения оценок товара по данным опросов в Москве и в Санкт-Петербурге; - оценка стандартного отклонения разности интересующих нас средних значений между этими городами.
Последняя величина рассчитывается по формуле
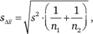 (12.20)
(12.20)
где s - средневзвешенное среднеквадратическое отклонение оценок от соответствующих средних значений в каждой из выборок.
В свою очередь, величина s рассчитывается по формуле
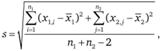 (12.21)
(12.21)
где x1,i и x2,j - оценки, полученные на i-м объекте из первой выборки и j-м объекте из второй выборки.
Такие проверки проводятся с помощью программного пакета SPSS (меню Analyze - Compare Means - Independent Samples T-test).
Зависимые выборки
Обсуждавшаяся выше проблема касалась случая, когда сравниваются доли или средние значения определенным образом ответивших на интересующий нас вопрос в двух разных группах респондентов. Нередко, однако, нужно сравнить между собой не реакции разных респондентов (например, живущих в разных городах), а две реакции у одних и тех же респондентов. Так бывает, когда информация собирается дважды на одной и той же выборке из n объектов. Например, дважды опрашиваются одни и те же респонденты и нужно проверить гипотезу, что за время, прошедшее между опросами, их оценки изменились. Скажем, надо узнать, действительно ли повысилась после рекламной кампании доля участников панели, знающих о существовании некоторого товара. Или узнать, действительно ли о существовании товара А знают больше респондентов, чем о товаре В, или наблюдаемое по данным опроса различие - просто случайность.
В случае зависимых выборок для проверки гипотезы об отсутствии различий в средних значениях применяется Вперед тестовая статистика с (n - 1) степенями свободы:
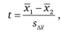
где 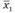 и
и 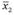 - средние значения оценок в первом и втором замерах соответственно;
- средние значения оценок в первом и втором замерах соответственно;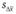 - стандартное отклонение определения различий в средних значениях оценок в двух замерах, рассчитываемое по формуле
- стандартное отклонение определения различий в средних значениях оценок в двух замерах, рассчитываемое по формуле
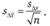 (12.23)
(12.23)
Здесь 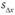 - стандартное отклонение различий между оценками в двух замерах, которое, в свою очередь, рассчитывается по формуле
- стандартное отклонение различий между оценками в двух замерах, которое, в свою очередь, рассчитывается по формуле
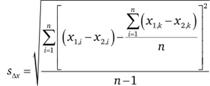 (12.24)
(12.24)
где 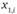 и
и 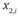
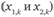 - оценки на
- оценки на 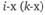 объектах в первом и втором замерах соответственно.
объектах в первом и втором замерах соответственно.
Отметим, что эти проверки можно провести с помощью программного пакета SPSS (меню Analyze - Compare Means - Pared Samples T-test).
Обзор других задач анализа данных
Перед нами не было цели обсудить методы решения всего круга проблем, которые приходится время от времени решать при базовом анализе маркетинговых данных. Мы рассмотрели лишь те из них, которые используются чаще других.
В заключение раздела подчеркнем следующее. Как уже отмечалось, основной материал для отчета о маркетинговом исследовании дают таблицы частотных распределений и кросстабуляции. Структура этих таблиц может быть намечена заранее в той мере, в которой она связана с задачами исследования и выбранными подходами к их решению, т.е. исследователь сам назначает интересующие его группы респондентов и располагает их в столбцах таблиц сопряженности.
Однако нередко форма некоторых отчетных таблиц может быть окончательно установлена лишь на стадии углубленного анализа данных. Так, лишь на этой стадии можно провести сегментирование исследуемой совокупности и найти сегменты, наиболее резко отличающиеся друг от друга по реакции их представителей на маркетинговые действия фирмы. Построив затем соответствующие таблицы кросс-табуляции, можно детально изучить особенности каждого из сегментов, что позволит разработать набор эффективных маркетинговых комплексов.
Есть много методов углубленного анализа данных. Основное назначение большинства из них - подсказать исследователю, какой принцип сегментирования окажется наиболее удачным в том смысле, что построенные затем таблицы кросс-табуляции продемонстрируют наиболее яркие контрасты. Интересно, что многие исследователи, стремясь добиться краткости и ясности изложения материалов, а также не спеша раскрывать секреты своего мастерства, оставляют за рамками отчета примененный ими способ отыскания этой наиболее удачной формы таблиц. Мы рассмотрим два метода, дающих такие "подсказки", - методы кластерного и факторного анализов. Эти методы приспособлены для работы с часто встречающимися в маркетинговых исследованиях бинарными и метрическими шкалами.
Категориальный метод главных компонент из арсенала методов многомерного шкалирования позволяет строить факторы на данных, измеренных в номинальных и порядковых шкалах.
Есть в арсенале исследователей и методы, позволяющие выяснить, как отнесутся потребители к тому или иному сочетанию свойств товара, насколько они ценят то или иное свойство товара. Это дает менеджерам рынка богатую пищу для размышлений при разработке маркетингового комплекса. Один из таких методов - совместный анализ (conjoint analysis) - тоже будет рассмотрен нами в дальнейшем.