Программные средства организации пользовательского интерфейса в Интернете
Аккаунт (от англ. account – счет (в банке)) – в российской компьютерной традиции переводится как "учетная запись пользователя". Пользователь получает ее после регистрации в определенной информационной системе (или в каком-либо программном приложении) через введение в регистрационные формы программы своего сетевого имени, или логина (англ. login) и пароля доступа (англ. password) к своей учетной записи (своему аккаунту).
Наличие персональной учетной записи (аккаунта) позволяет получить индивидуализированный доступ к сервисам системы, который обычно гарантирует выделение ему специальной директории для хранения файлов и других материалов, связанных с его работой в программе. Эти информационные ресурсы являются личной информацией пользователя, т.е. недоступны для других пользователей (кроме системного администратора), однако пользователь может открывать к ним доступ третьим лицам по своему усмотрению. Часто учетная запись пользователя включает в себя также такую информацию о личности ее владельца, которую он хочет сделать открытой для всех (так называемый профиль пользователя – англ. user profile). Для входа в свой персональный аккаунт пользователь должен ввести в ноля соответствующей формы программы свои зарегистрированные имя (логин) и пароль в соответствии с созданной учетной записью.
Помимо индивидуальных аккаунтов (предоставляющих возможность работы с программой только одному данному пользователю), существуют также специальные виды учетной записи, которые позволяют получить доступ к сервисам системы любому желающему, – так называемые анонимные (англ. anonymous) или гостевые (англ. guest account) аккаунты.
Веб-браузер (англ. web-browser) – специализированная компьютерная программа, разработанная для осуществления доступа к файлам Глобальной сети Интернет. Эта программа запрашивает и получает данные из хранилища файлов на серверном компьютере (компьютерах-серверах), которые затем предъявляются пользователю в виде веб-страницы на экране его компьютера или любого другого устройства (гаджета), подключенного к Интернету. В настоящее время существует довольно много программ – веб-браузеров, из которых наиболее популярными являются Google Chrome, Internet Explorer, Mozilla Firefox, Safari и Opera.
Электронная почта (англ. electronic mail, или e-mail) – электронное сообщение, пересылаемое с одного компьютера на другой. Электронное почтовое послание (электронная почта) обычно бывает в текстовой форме, по может также содержать в виде приложения (англ. attachment) файлы любого формата, например форматированный текст (подготовленный в текстовом редакторе Word, OpenOfficeWriter и др.), графический файл, компьютерную презентацию, электронные таблицы и т.п. Единственный тип файлов, который не рекомендуется пересылать по электронной почте, – это архивированные файлы и файлы, которые содержат исполняемые программы (такие файлы часто имеют расширение EXE). Это правило для электронной почты установлено для борьбы с пересылкой по этому коммуникационному каналу вредоносных программ – компьютерных вирусов.
Система кодирования символов в Интернете
Кодировка, или набор кодовых символов (англ. encoding, character set), – таблица, в которой даны специальные компьютерные обозначения для конечного числа символов алфавита языка (обычно элементов текста – букв, цифр, знаков препинания). В такой таблице каждому символу языкового алфавита соответствует определенная последовательность нулей и единиц (битов) в компьютере. Благодаря такой таблице на экран компьютера выводится текст на каком-либо языке в привычной для носителей этого языка форме.
Первоначально в каждой операционной системе использовался свой особый набор символов, обозначающих знаки языка, что, естественно, создавало много неудобств не только программистам, но и пользователям, так как тексты, созданные на одном компьютере, могли быть искажены до неузнаваемости при попытке прочитать их на другом. Считается, что решить эту проблему можно, если компьютерные системы будут самостоятельно определять тип кодирования текста и осуществлять перекодировку в случае необходимости. Однако для этого необходимо было бы прийти к соглашению о принятии общих стандартов кодирования, что на ранних этапах существования Интернета не всегда удавалось достичь. Примером одновременного существования нескольких стандартов кодирования знаков языкового алфавита является Россия. Поскольку разработка программного обеспечения для сетевых компьютерных приложений велась в России на начальном этапе появления в нашей стране Интернета достаточно бессистемно и несогласованно, для кодирования кириллических знаков до сих пор используются несколько разных кодировок, созданных отечественными и зарубежными программистами в разное время. Другие языки с нелатинской письменностью тоже страдали из-за наличия нескольких разных кодировок.
Долгое время основной русской кодировкой в Unix-совместимых операционных системах и в электронной почте была разработанная в России кодировка КОИ-8 (код обмена информацией, 8 битов). Существует несколько вариантов кодировки КОИ-8 для различных кириллических алфавитов, например для отображения знаков украинского алфавита (KOI8-U), сербского и др. Однако в результате практически повсеместного распространения в России на клиентских компьютерах операционной системы Windows эту кодировку постепенно вытеснила кодировка Windows-1251, которая была стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Вместе с тем оказалось, что такого типа кодировки все же не позволяли решить все проблемы, возникающие при отображении текста на языках, использующих отличные от латиницы знаковые системы. Поэтому процесс создания новых кодировок продолжился, что еще более усугубило проблему совместимости программного обеспечения, особенно такого, которое обеспечивало работу в Интернете.
Попыткой кардинального решения проблемы стала разработка стандартной универсальной кодировки, которая позволила бы отобразить знаки всех известных (т.е. описанных лингвистами) языков мира, – Юникода (англ. Unicode – Uniform character encoding). Универсальная система кодирования (Юникод) представляет собой набор графических символов и способ их кодирования для компьютерной обработки текстовых данных на большинстве известных письменных языках. В компьютерных документах, использующих кодировку Юникод, могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, при этом становится ненужным проводить переключение кодов. В настоящее время для набора символов Юникода используются несколько видов кодировки, которые обозначаются как UTF-8, UTF-16 и UTF-32.
Стандарт кодировки Юникод состоит из двух основных разделов: универсальный набор символов (англ. UCS – Universal Character Set) и семейство кодировок (англ. UTF – Unicode Transfomation Format). Универсальный набор символов задает однозначное соответствие символов кодам, семейство кодировок определяет машинное представление последовательности кодов. Коды в стандарте Юникод разделены на несколько областей:
1) область, совпадающая с базовой американской стандартной кодировочной таблицей для печатных символов и некоторых специальных кодов (англ. ASCII – American Standard Code for Information Interchange), которая была исходной для всех видов компьютерной обработки информации;
2) области знаков различных письменностей, знаки пунктуации и некоторые технические символы;
3) область кодов, зарезервированная для использования в будущем при возникновения такой необходимости.
Роль кодировки Юникод в информационном обмене в Интернете постоянно растет, достаточно заметить, что на начало 2010 г. доля веб-сайтов в Интернете, использующих Юникод, составила уже около 50%.
Поскольку Юникод является системой для линейного представления текста, символы, которые имеют дополнительные над- или подстрочные элементы, могут быть представлены в ней в виде построенной по определенным правилам последовательности базовых кодов (т.е. по технологии так называемого составного знака – англ. composite character) или в виде единого многокомпонентного символа (англ. precomposed character).
Графические символы в Юникоде подразделяются на протяженные и непротяженные. Непротяженные символы при отображении не занимают места в строке. К ним относятся, в частности, знаки ударения и прочие диакритические знаки. Как протяженные, так и непротяженные символы имеют собственные коды. Протяженные символы иначе называются базовыми (англ. base characters), а непротяженные – модифицирующими (англ. combining characters); причем последние не могут встречаться самостоятельно.
Например, символ "а́" может быть представлен в Юникоде как последовательность базового символа "а" (машинный код "U+0061") и модифицирующего символа "'" (машинный код "U+0301") или как монолитный символ "а́" (машинный код "U+00C1"). Аналогично формируется представление, например, таких русских букв, как Ё и Й (механизм представления буквы Й показан на рис. 4.3).
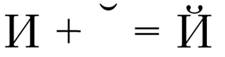
Рис. 4.3. Представление символа "Й" в виде базового символа "И" и модифицирующего символа "”"
При всем удобстве использования кодировки Юникод в качестве универсального стандарта кодирования символов все же остаются пока еще не разрешимые с помощью этой системы проблемы: в частности, изображение "длинных" надстрочных символов, которые пишутся сразу над несколькими буквами (как, например, знак "титла" в церковнославянском языке), пока не реализовано.