Лекция 3. Общая теория баз данных
С момента появления понятия "база данных" возникла необходимость в теоретической математической поддержке процессов в ней. Постепенно выявились три относительно самостоятельные части теории баз данных: 1) построение баз данных; 2) использование баз данных; 3) функционирование баз данных. Они выстроились в относительно стройную систему позднее в рамках реляционных БД.
В настоящее время при проектировании структур данных применяют три основных подхода.
1. Сбор информации в рамках одной таблицы и поВперед ее декомпозиция.
2. Использование CASE-технологии [2].
3. Структурирование информации в процессе проведения системного анализа на основе совокупности правил и рекомендаций.
Первоначально на роль теории баз данных независимо от используемой модели данных претендовала CASE-технология. Позже выяснилось, что CASE-технология охватывает лишь процедуру построения БД, да и то не полностью.
Широкое распространение реляционных БД привело к необходимости добавления в CASE-технологию процедуры нормализации, являющейся частью теории реляционных баз данных, на основе ER-диаг- рамм. Процедура нормализации была формализована и реализована на компьютере (в диалоговом варианте) в ряде СУБД (Access, Oracle). Вместе с тем, построение ER-диаграмм – процедура специфическая.
Возникают сложности и с процедурой нормализации [2,3].
В связи с этим реляционные БД чаще проектируют, применяя понятие "отношение".
В то же время в CASE-технологии заложены возможности автоматизации процедуры проектирования баз данных, что особо важно при создании баз данных большой размерности (20 Гбайт и выше).
Модели представления данных
БД, как элемент системы принятия решений (например, в АСУ) есть отражение предметной области реального мира [9]: ее объекты, отношения между ними и отношения в БД должны соответствовать друг другу. Компьютер (и АСУ в частности) оперирует только формальными понятиями (моделями), соответствующими объектам и связям внешнего мира. В настоящее время имеется свыше тридцати моделей представления данных, которые до последнего времени не были систематизированы.
Их можно разделить на две группы:
1) формальные (математические, скорее теоретические), предполагающие разработку БД обязательно с участием человека;
2) математические представления, рассчитанные на автоматизацию процесса проектирования БД ("компьютерное представление").
Вторая группа рассмотрена в парагр. 3.2, а первую обсудим здесь.
Сразу отметим разницу двух понятий [9|: "модель данных" – средство моделирования; "модель БД" – результат разработки БД. Модель (представление) БД – множество конкретных ограничений над объектами и операциями с ними.
Модель данных (точнее – модель представления данных) есть множество элементов (объектов, типов данных) и связей (отношений) между ними, ограничений (например, целостности, синхронизации многопользовательского доступа, авторизации) операций над типами данных и отношениями.
Множество допустимых типов данных и их отношений образуют структуру данных. В модели данных, следовательно, выделяется три компоненты: структура данных; ограничения, определяющие допустимое состояние БД; множество операций, применяемых для поиска и обновления данных. Эти компоненты отображаются языковыми и программными средствами описания и манипулирования данными.
Описание часто проводят последовательно: структура, ограничения, операции. Начнем с описания структур данных.
Проще всего структуру (отношение) можно задать таблицей с "плоской" (см. табл. 1.11) или сложной (см. табл. 1.12) структурой. При таком задании хорошо видны элементы (столбцы, поля), однако плохо просматриваются отношения, которые могут быть четырех типов: 1:1, 1:М, M:l, M:N.
Более наглядным (особенно для представления типа 1:1) является представление в виде ориентированного графа (рис. 3.1), восходящее к математике, теории автоматического управления и теории информации. Элементами п (п принадлежит N) графа Г(N, U) являются столбцы (поля), а связи между ними определяются дугами и (и принадлежит U). Такому графу соответствует матрица смежности (табл. 3.1) или двудольный граф. Разновидностью графов являются предложенные Д. Мартиным овал-диаграммы (рис. 3.2).
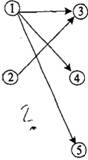
Рис. 3.1. Ориентированный граф:
1–5 – узлы графа
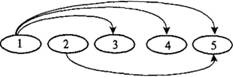
Рис. 3.2. Овал-диаграмма: 1–5 – узлы диаграммы
Таблица 3.1
Матрица смежности
|
1 |
2 |
3 |
4 |
5 |
|
|
1 |
0 |
0 |
1 |
1 |
1 |
|
2 |
0 |
0 |
0 |
0 |
1 |
|
3 |
0 |
0 |
0 |
0 |
0 |
|
4 |
0 |
0 |
0 |
0 |
0 |
|
5 |
0 |
0 |
0 |
0 |
0 |
Теория графов достаточно хорошо развита, однако прямое ее применение для представления данных встречает затруднения, вызванные следующими обстоятельствами:
• связи в моделях представления данных относительно просты (см. рис. 3.1), матрицы смежности получаются разреженными, что снижает ценность их использования;
• в графах отражается чаще всего один тип связи (например, 1:1): выходом здесь может быть использование овал-диаграмм;
• при постановке задачи представления (моделирования) данных, в отличие от теории управления и математики, в которых широко используются начальные предположения, велик объем неформальной составляющей.
Для преодоления третьего затруднения сформировались модели представления данных "сущность – связь" (Entity – Relationship), называемые также "ER-моделями (диаграммами)" или "моделями Чена". Базовыми структурами в ER-модели являются "типы сущностей" и "типы связей".
Отличие типа связи от типа сущности – в установлении зависимости существования реализации одного типа от существования реализации другого. (Например, ЛИЧНОСТЬ – тип сущности, тип СОСТОИТ В БРАКЕ – нет, поскольку реализация последнего типа не существует, если не существует двух личностей. Тип связи может рассматриваться поэтому как агрегат двух или более типов сущностей.)
Выделяют три типа связи: связь "один к одному" (1:1), связь "один ко многим" (1:М), связь "многие ко многим" (M:N).
Примеры этих связей могут быть следующие:
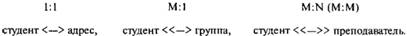
Следует отметить особенности отображения ER-модели. Выделяют следующие типы связей:
• рекурсивное (по "кольцу") множество связей, в котором участвуют несколько сущностей;
• два множества связей между одними и теми же двумя множествами сущностей;
• множество n-арных связей, например тернарных (четыре связи, "исходящие от одной сущности").
Выделение этих связей является крайне важным, так как связи 1:М и M:N имеют внутреннюю неопределенность, что сказывается при операциях модификации. Для преодоления неопределенности на этапе реализации логической модели требуется вводить избыточную информацию.
Отметим, что сущность примерно соответствует таблице, а атрибут – полю реляционной базы данных.
Фрагмент концептуальной модели предметной области "Учебный процесс" представлен на рис. 3.3, а пример представления атрибутов для конкретного объекта показан на рис. 3.4. Выделяют многозначный атрибут, атрибут множества связей.
В общем случае атрибуты отображаются либо на самой ER-диаг- рамме (при небольшом количестве объектов), либо в виде отдельных приложений по каждому объекту.
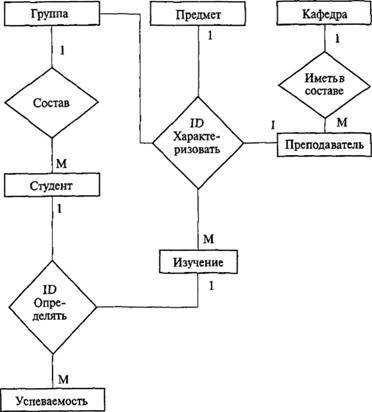
Рис. 3.3. ER-диаграмма предметной области "Учебный процесс"
При построении ER-моделей в ряде случаев целесообразно выделять ряд ограничений:
• ограничение целостности применительно к атрибутам: (например: N – студенты, целое, положительное, число студентов – диапазон от 5 до 35);
• ограничение Е по существованию сущностей (рис. 3.3);
• ID-зависимость (рис. 3.3): сущность не может быть идентифицирована в ряде случаев по значениям собственных атрибутов.
Здесь прямоугольниками показаны типы сущностей и атрибуты, ромбами – типы связей.
Покажем свойства этих моделей на примере БД "Учебный процесс" в институте (рис. 3.4). Укрупненно (и в несколько другом начертании, чем на рис. 3.3) он может быть представлен в виде отношений трех групп атрибутов (рис. 3.4, а) со связями Μ:Ν и 1:М. Поскольку группы 1 и 3 – множества, схему можно представить в виде рис. 3.4, б. Известно, что ни одна модель данных не может реализовать отношения Μ:Ν. В связи с этим схема связей после преобразования окончательно выглядит, как показано на рис. 3.4, в.
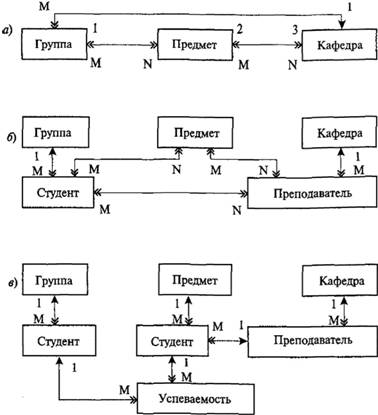
Рис. 3.4. Модель БД "Учебный процесс": а – исходная структура; б – промежуточная структура; в – результат
Заметим, что перечисленные методы обладают следующими недостатками:
• слабо ориентированы на использование компьютеров в проектировании БД;
• оперируют со статическими (неизменными) данными, тогда как в реальных системах управления используются динамические данные (потоки данных);
• отражают потоки данных не системно.
Названные недостатки устранены в CASE-технологии [25].