Нестационарные процессы и приведение их к стационарному виду
Чтобы разобраться в том, как привести исходный ряд данных к стационарному виду, рассмотрим для начала, какие типы нестационарных процессов выделяет классическая эконометрика. А их всего два:
1) процесс, стационарный в конечных разностях;
2) процесс, не стационарный в конечных разностях.
К первому могут относиться различные процессы, описываемые моделями трендов, а также процессы с переходом показателя с одного уровня на другой. Они изображены на рис. 8.5.
Ко второму типу процессов относятся все остальные нестационарные процессы.
Левый верхний график на рис. 8.5 представляет собой нестационарный процесс, описываемый линейным трендом
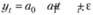
Этот процесс будет стационарным в первых разностях, так как взятие их в такой ситуации влечет избавление от угла наклона:
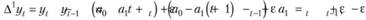
что приводит нас к постоянному математическому ожиданию и дисперсии.
Левый нижний график на рис. 8.5 демонстрирует нестационарный процесс, описываемый параболой.
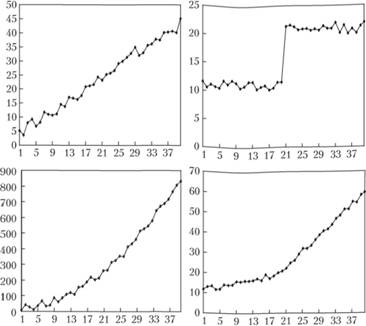
Рис. 8.5. Виды стандартных нестационарных процессов
По аналогии с линейным трендом можно показать, что этот процесс будет стационарен во вторых разностях.
На правом верхнем графике рис. 8.5 изображен нестационарный процесс со сменой уровня ряда. На себя обращает внимание то, что примерно до 20-го наблюдения значение уt колеблется вокруг одного значения константы, а после него – вокруг другого. Этот ряд так же становится стационарным в случае с взятием первых разностей, так как при этом происходит избавление от констант и все колебания происходят уже на уровне нуля. Заметим, что в ряде в разностях при этом появляется выброс, соответствующий переходу на новый уровень после 20-го наблюдения.
Наконец, на правом нижнем графике рис. 8.5 изображен нестационарный процесс со сменой угла наклона. Примерно до 20-го наблюдения динамика процесса носит более спокойный характер, чем после него. Взятие вторых разностей в этом случае так же приводит процесс к стационарному виду.
Очевидно, что только этими видами экономические процессы не ограничиваются (мы привели в качестве примера только базовые) и взятие разностей, к сожалению, не всегда повышает точность прогноза. А в случае с эволюционными процессами, в которых происходят постоянные изменения всех статистических параметров, взятие разностей может наоборот уменьшить точность прогноза: ряд действительно может стать "стационарным" со статистической точки зрения, но пользы от этого будет немного, потому что уже на периоде прогнозирования наметившаяся тенденция может смениться. Поэтому приведение ряда к стационарному виду нельзя считать "панацеей".
Чтобы включить разности в модель ARMA, обычно используют лаговый оператор. Например, разности первого порядка можно записать следующим образом:
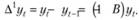 (8.39)
(8.39)
Вторые разности в этой же записи принимают вид
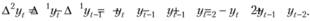 (8.40)
(8.40)
Применив теперь к (8.40) лаговый оператор, получим
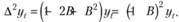 (8.41)
(8.41)
Вообще, разности порядка d с помощью лагового оператора записываются в виде
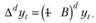 (8.42)
(8.42)
Модель авторегрессии со скользящей средней, построенная на основе разностей, обозначается как ARIMA(p,d,q), где буква 1 отвечает за порядок d интеграции (взятой разности), и записывается в компактном виде
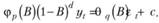 (8.43)
(8.43)
Обычно в случае, если d > 0, константа из (8.43) убирается, так как при переходе от разностей к исходным данным из-за нее в модели появляется тренд ct, а трендовые компоненты в ARIMA должны описываться элементами авторегрессии. Однако иногда константу оставляют, и тогда такая модель называется модель ARIMA с дрейфом ("with drift").
Рассмотрим теперь для примера, что будет собой представлять модель АRIМА(2,1,1). Она записывается в виде
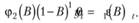 (8.44)
(8.44)
Чтобы понять, чему соответствует такая модель, раскроем эту запись:
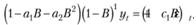
Перепишем разность через разностный оператор:
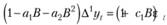 (8.45)
(8.45)
и раскроем скобки в (8.45):
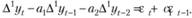
Перенесем все, кроме значения разности, на наблюдении t, в правую часть:
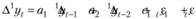 (8.46)
(8.46)
Теперь, чтобы получить финальное значение yt, нужно воспользоваться формулой (8.39). Получим

или, что равноценно,
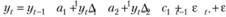 (8.47)
(8.47)
По модели (8.47) можно легко получить прогноз на один шаг вперед:
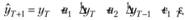 (8.48)
(8.48)
К сожалению, для того, чтобы получить прогноз на большее число шагов вперед, нужно воспользоваться рекурсивной процедурой, описанной нами в параграфе 8.1.
Обратим внимание на то, что обычно при построении модели ARIMA порядок разностей ограничивается числом d = 2. Это вызвано тем, что взятие вторых разностей обычно позволяет привести к стационарному виду практически любые нестационарные ряды данных.
Как видим, инструмент разностей достаточно удобен и прекрасно вписывается в модель ARMA, но это, конечно же, не единственный инструмент по приведению нестационарного ряда к стационарному виду. Расскажем кратко о других методах.
Один из самых простых методов приведения к стационарности – это построение по исходному ряду данных модели тренда. Построив модель выбранного тренда, исследователь рассчитывает остатки по модели и уже по ним строит модель ARMA.
У такого метода есть один существенный недостаток – негибкость. Сами тренды никоим образом не учитывают новую поступающую информацию, поэтому и модели, построенные на их основе, будут застывшими. Однако использование трендов при приведении ряда к стационарному виду позволяет в ряде случаев получать более точные прогнозы в долгосрочной перспективе[1].
Достаточно перспективной, но не очень распространенной альтернативой взятию разностей является метод, предложенный в 1982 г. Э. Парзеном[2]. Его суть заключается в том, чтобы описать исходный ряд данных нестационарной моделью AR, после чего по полученным остаткам построить модель ARMA. Полученная в итоге модель называется ARARMA.
Еще одним вариантом приведения ряда данных к стационарному виду является взятие нецелых разностей (когда d становится нецелым числом), что достигается путем разложения (l-B)d в ряды Тейлора. Суть метода заключается в том, что взятие целых разностей может быть излишним для некоторых рядов данных (стационарность может лежать где-то между d = 0 и d= 1). Порядок разности d в таком случае подбирается автоматически. По преобразованному ряду вновь строится ARMA. Модель, получаемая в результате этого, носит название ARFIMA (AutoRegressive Fractionally Integrated Moving Average)[3].
Кроме того, существует метод, использующийся для получения постоянной дисперсии (обычно решающий проблему гетероскедастичности во многих случаях), – логарифмирование исходного ряда данных. Он позволяет получить ряд с постоянной дисперсией в тех случаях, когда ошибка в модели носит мультипликативный характер.
Сезонные ряды данных так же могут считаться нестационарными (так как дисперсия, например, в начале года может отличаться от дисперсии в середине). Чтобы избавиться от сезонности, можно либо воспользоваться одним из методов сезонной декомпозиции, либо взять сезонные разности. Первый вариант решения данной проблемы был рассмотрен нами в параграфе 6.1, а ко второму мы обратимся в параграфе 8.4.