Моделирование процессов обработки данных
Использование СУБД в реализации баз данных предполагает применение технологий обработки хранимых в базах данных сведений на основе встроенных инструментов обработки: хранимые процедуры, триггеры и представления. Каждый из этих инструментов обладает индивидуальными особенностями реализации и использования. Представления являются наиболее часто применяемым инструментом, предполагающим обработку данных в части исполнения запросов пользователей по получению сведений из базы данных. Структурно представления реализуются в виде программного кода на языке манипулирования данными (DML). Для реляционных баз данных таким языком является SQL.
Реализация представления осуществляется, как правило, на основе заранее зафиксированных в коде запроса параметров либо без параметрических элементов. Эта особенность накладывает очень серьезные ограничения на их (представления) использование, поскольку не позволяет использовать данные, введенные пользователем, и получать в результате сведения из базы данных на их основе. Хранимые процедуры являются вторым по частоте использования инструментом обработки данных и используются, когда необходимо произвести операции по модификации данных в таблицах базы данных, а также они применяются при организации выборки данных на основе сведений, введенных пользователем в экранную форму. Физически хранимая процедура реализуется в СУБД в виде программного кода на языке манипулирования данными (DML) и (или) встроенной в СУБД собственной модификации такого языка, а также может реализовываться на прочих языках программирования, как, например, Java или С.
Для различных СУБД язык представления хранимых процедур может быть различным, как, например, SQL-Server использует язык Transact- SQL, Oracle Database - PL/SQL, IBM DB2 - SQL, PostgreSQL - pgPL/ SQL и т.д. Такая особенность в СУБД накладывает определенные ограничения на правила обработки данных, но все указанные и аналогичные языки построены на основе единого языка — SQL. Этот язык описывает основные конструкции по манипулированию данными, общий синтаксис которых является стандартом для современных реляционных СУБД.
Триггеры, являясь частным случаем хранимых процедур, выполняют также операции по манипулированию данными, но ограничены возможностями применения, а именно: не могут возвращать результат выборки по параметрам пользователя, не могут принимать от пользователя исходных данных, основываются на действиях по манипулированию данными (добавление новых записей, изменение значений в ячейках базы данных, удаление записей), в качестве исходных данных используют старые и новые значения записей, которые обрабатываются действиями манипулирования данными.
Для написания триггеров, как и для хранимых процедур, используется язык манипулирования данными, основанный на стандарте языка SQL. Выполняться триггер может "до" или "после" исполнения операции по модификации данных (добавление, изменение, удаление). Процесс разработки базы данных, как и для информационной системы, проходит через стадии проектирования, моделирования и реализации, где проектирование с моделированием, ввиду использования специализированных программных инструментов, соединяются в единую операцию. При этом разработка базы данных предполагает не только моделирование структуры базы данных и установление правил ссылочной целостности, но также рассматривает вопросы манипулирования данными, а именно: добавление, изменение, удаление и, наиболее часто встречающаяся операция, выборка. Эти операции бывают достаточно сложными и зачастую требуют серьезного подхода к их проектированию и описанию.
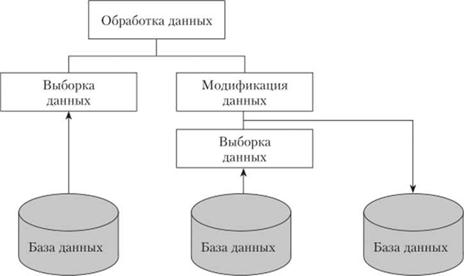
Ставя задачу описания обработки данных, разработчики всегда отделяют выборку от модификации данных, понимая при этом, что в рамках выполнения операций по модификации данных также необходимо будет реализовывать множество действий по выборке данных. Таким образом, вложенность операций можно представить, как показано на рис. 5.50.
Естественно, что разработчики их рассматривают отдельно и для каждой из них описывают правила реализации. Так, для операции выборки определяются исходные данные, которые должны поступить от пользователя, а также на основе каких таблиц эти исходные данные основываются и какие таблицы участвуют в формировании результата выборки. К тому же определяются дополнительные параметры, такие как: правила сортировки, правила вычисления и группировки, условия ограничения выборки. В процессе моделирования разработчиками планируется последовательность работы СУБД по использованию промежуточных таблиц, наложения ограничений на результаты выборок из этих таблиц и применения подзапросов, функций или ранее созданных представлений.
|
Рис. 5.50. Операции обработки данных |
Для разработки процедур обработки данных необходимо также представлять модель реализации, которая выстраивается по принципам, знакомым разработчикам по процедурной алгоритмизации, используемой в программировании. Хранимая процедура представляется набором программных операций с применением конструкций условий, циклов и конструкций курсоров, используемых только для баз данных.
Под курсором в языке манипулирования данных понимается ссылка на область памяти, заполняемую результатами запроса к базе данных по выборке данных.
Курсоры основываются на запросах выборки данных и предоставляют возможность в хранимой процедуре последовательно обрабатывать каждую запись результата выборки, что позволяет обеспечить уникальность обработки данных в записях на основании специфических условий для каждой записи выборки.
Для описания хранимых процедур используются сведения о параметрах, которые пользователь должен заполнить на основании экранной формы, и о результате, который процедура должна вернуть, включая вариант возврата набора записей после выборки. Учитывая, что результатом работы хранимой процедуры может быть набор записей после выборки данных, такая хранимая процедура при моделировании похожа на модель запроса выборки, но с учетом входных параметров от пользователя.
Для триггера моделирование полностью идентично хранимой процедуре, учитывая, то пользователь исходные данные представить не может, а сама процедура применяет только сведения, которые модифицируются соответствующим действием над данными.
Применение инструментария IBM WebSphere Business Modeler для моделирования обработки данных позволяет визуализировать ал го- ритмы работы программ и запросов, обозначая место и последовательность использования таблиц базы данных. На основе таких моделей специалист, занимающийся программированием элементов базы данных (представления, хранимые процедуры, триггеры), сможет правильно реализовать соответствующие операции, а проект информационной системы получит качественную документацию по вопросам программной реализации базы данных.
Интеграция инструмента с системой моделирования и реализации базы данных IBM InfoSphere Data Architect позволяет синхронизировать структуры таблиц, представляемых в инструменте бизнес-элементами (рис. 5.51). Для моделирования запросов и хранимых процедур необходимо воспользоваться механизмом моделирования бизнес-процессов.
|
Рис. 5.51. Инструмент моделирования |
Также для моделирования необходимо определять бизнес-элементы, которые, имея возможность описать атрибутивный состав, могут представлять структуры таблиц, а возможности интеграции с IBM InfoSphere Data Architect позволяют перенести эти структуры в модель базы данных, а впоследствии в саму физическую базу данных.
Из палитры процесса для формирования моделей запросов и хранимых процедур потребуются элементы, перечисленные в табл. 5.5
Таблица 5.5
|
Применимость компонентов моделирования
|
|
Компонент |
Модель запросов |
Модель обработки |
|
Процесс Операция обработки данных |
Подзапрос |
Запрос, функция, хранимая процедура |
|
Цикл While Циклическая обработка |
— |
Цикл с ограничением, обработка курсора |
|
Цикл For Циклическая обработка |
— |
Цикл с известным количеством повторений |
|
<£ Простое решение Условная конструкция |
— |
Условие обработки |
|
Решение с множественным выбором Условная конструкция |
Условия использования значения |
Условие обработки, использования значения |
|
Хранилище Таблица базы данных |
Указание на чтение из таблицы базы данных |
Указание на сохранение в таблице базе данных, чтение для подзапроса в операции модификации данных |
|
Выборка данных |
Пример
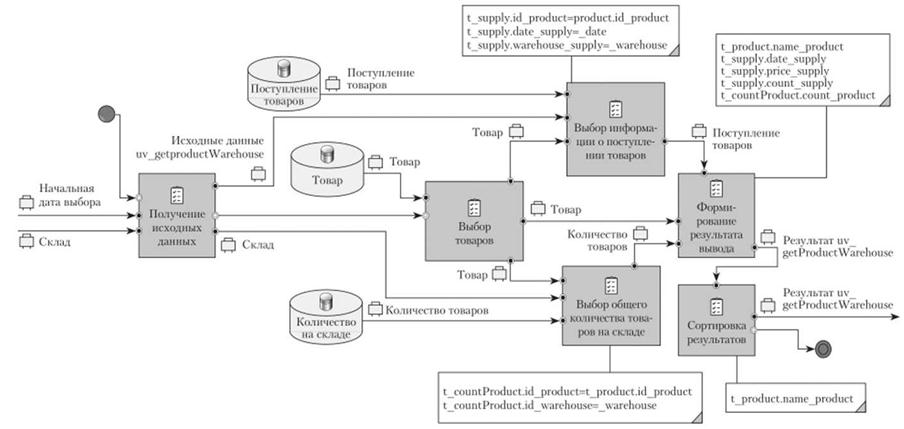
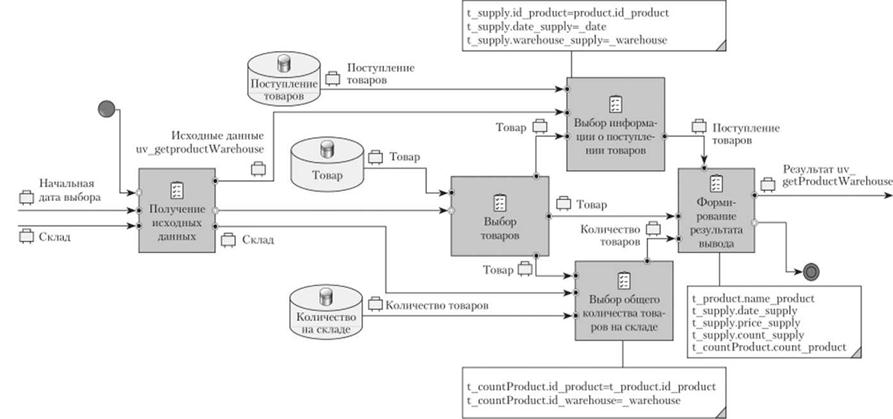
11редположим, что требуется выбрать сведения о товарах на складе, поступивших 1 ноября 2015 г. (01.11.2015) и принятых на складе № 1. Результат должен содержать сведения о наименовании товара, его артикуле, цене поступления, количестве поступления, текущем количестве. Выбранные записи необходимо отсортировать, но алфавиту наименований товара.
Анализ примера запроса выборки показывает, что пользователь должен выбрать склад, на который принимается товар, и указать дату, на которую будут выбираться товары. Использование этих параметров в качестве заранее предустановленных в запросе выборки нецелесообразно, поскольку они могут изменяться с течением времени и по потребности пользователя (рис. 5.52). Исходя из этого можно сделать заключение, что должна выполняться процедура выборки с возвратом множества записей выборки.
Моделирование таких запросов и запросов с фиксированным набором значений по параметрам не имеет никаких различий. Все различия находятся в реализации, где применяется представление или хранимая процедура соответственно.
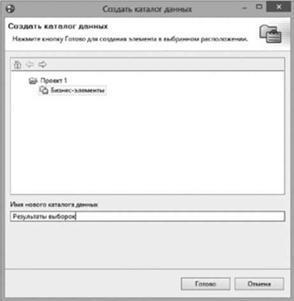
Для начала моделирования необходимо определиться со структурой данных, которые должны быть получены в результате обработки. Для этого создается бизнес-элемент "Выборка процесса 1". Чтобы не запутаться в большом количестве бизнес-элементов, создается каталог данных "Результаты выборок" (рис. 5.53). Для создания каталога данных нужно в дереве проектов вызвать контекстное меню бизнес-элементов и выбрать
пункт меню "Создать/Каталог данных", после чего в диалоговом окне указать название каталога данных и описание, что за сведения будут храниться в данном каталоге.
|
|
Рис. 5.52. Создание каталога данных
|
Рис. 5.53. Диалоговое окно создания каталога данных |
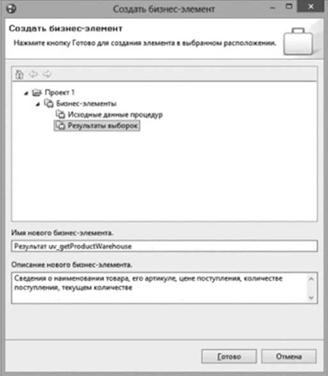
Для создания бизнес-элемента, описывающего структуру выходных данных, аналогичным образом вызывается контекстное меню каталога данных "Результаты выборок", выбирается пункт меню "Создать/Бизнес элемент" и в диалоговом окне определяется название бизнес-элемента и описание его структуры (рис. 5.54). В качестве описания можно использовать
формулировку из текста запроса, где указано, что должно быть выведено в качестве результата.
|
Рис. 5.54. Диалоговое окно создания бизнес-элемента |
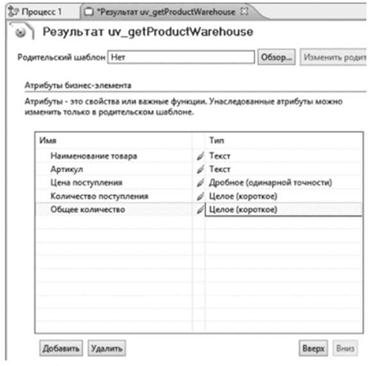
В итоге с помощью соответствующего механизма описывается атрибутивный состав вывода результата запроса, типы данных в котором относятся к простым (рис. 5.55). * V
|
Рис. 5.55. Описание атрибутов результата выборки |
Для того, чтобы проводить моделирование запроса выборки, необходимо представлять модель базы данных, с которой потребуется работать. При моделировании можно воспользоваться логической моделью, но для реализации необходимо использовать физическую модель базы данных, где наименования таблиц и полей представлены идентично физической реализации базы данных. Поэтому лучшим вариантом описания запроса выборки будет описание, основанное на физической модели базы данных (IBM InfoSphere Data Architect, рис. 5.56).
|
Puc. 5.56. Физическая модель базы данных |
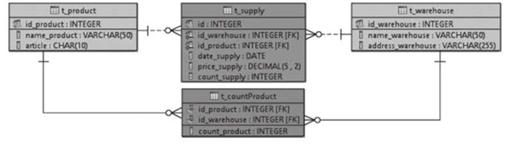
Представленная модель отражает только ту часть базы данных, которая необходима для полноценного рассмотрения примера запроса выборки и включает таблицы и атрибуты, которые перечислены в табл. 5.6.
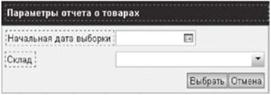
На следующем шаге вместе с определением результирующих данных необходимо определить набор входных данных. Поскольку рассматриваемый пример предполагает получение исходных данных от пользователя, то для этого необходимо определить экранную форму, которая позволит пользователю ввести эти данные (IBM Form Designer, рис. 5.57).
|
Рис. 5.57. Пример формы для задания параметров выборки |
Также при моделировании реализации запроса выборки необходимо определить экранную форму для вывода результирующего электронного документа (IBM Form Designer, рис. 5.58).
|
Рис. 5.58. Пример формы вывода отчета |

|
Описание физической модели базы данных
|
В случае, когда результат выборки используется в компоненте экранной формы, для нее определяются перечень атрибутов и их соответствие с атрибутами описания результата выборки. Так, для экранной формы параметров выборки требуется указать склад, по которому необходимо сформировать результат. Для этого используются данные из таблицы базы данных, атрибуты которой должны быть ассоциированы с экранной формой и ее элементом (в рассматриваемом случае это выпадающий список "Склад"), где используются ИДФ и наименование склада (табл. 5.7).
|
Таблица 5.7 Пример соответствия атрибутов таблицы и модели
|
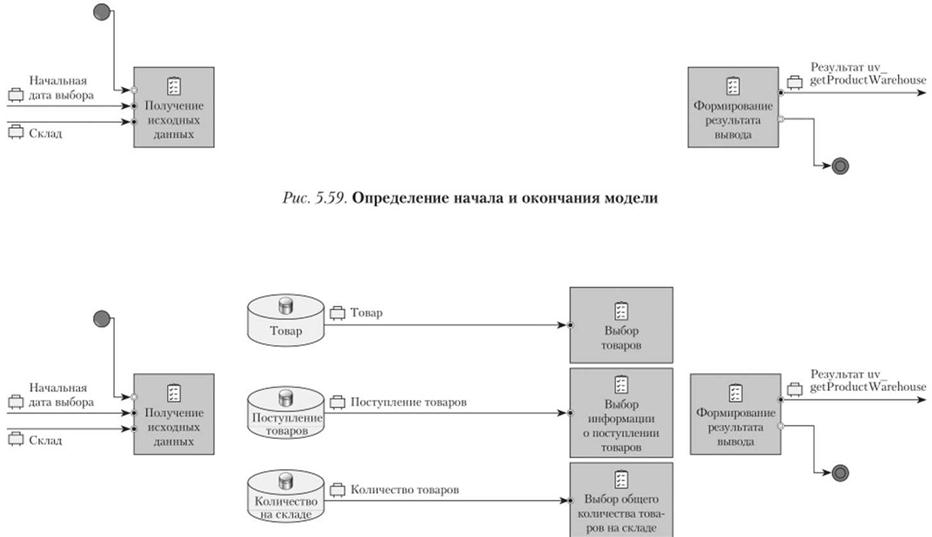
Таким образом, базовые параметры для моделирования запроса определены и можно приступать к непосредственному моделированию, которое заключается в построении визуальной модели получения и компонования данных из базы данных. Процесс начинается с определения начала и завершения процесса выборки (рис. 5.59).
Начинается процесс с получения исходных данных, которые определены несколькими бизнес-элементами. Допускается указание единого бизнес-элемента, состав которого определяет набор входных данных. В случае использования единого бизнес-элемента исходных данных впоследствии, где это требуется, необходимо будет делать явные комментарии об использовании одного из атрибутов этого бизнес-элемента.
Завершается процесс выборки задачей компонования результата вывода, который потом будет обрабатываться программным приложением для формирования экранной формы результата. На выходе этой задачи указывается бизнес-элемент результата обработки.
Следующим шагом является определение необходимых для выборки таблиц. Эта процедура сродни операции построения алгоритма выполнения программы и представляется последовательным рассуждением над процедурой формирования результата из исходных данных. Для простоты выполнения этой задачи разработчики, как правило, отталкиваются от результирующих данных, поскольку именно они могут на текущем этане однозначно подсказать набор результирующих таблиц (рис. 5.60).
Конечно, для выборки данных из этих таблиц нужны соответствующие задачи, но определение последовательности их соединения является следующей задачей, формируя этим план обработки данных. Поскольку необходимо выбрать данные о товарах и на эту таблицу не накладываются прямые ограничения, то ее целесообразно использовать в качестве первой для определения результата и, отталкиваясь от нее, подключать связанные таблицы.
Модель выполнения выстраивается на основании связей между таблицами в базе данных и возможных условий выборки, которые могут быть выполнены в процессе подсоединения таблиц (рис. 5.61). Так, процедура начинается с выбора товаров без условий ограничения, поскольку исходные
|
Рис. 5.60. Определение результирующих таблиц |
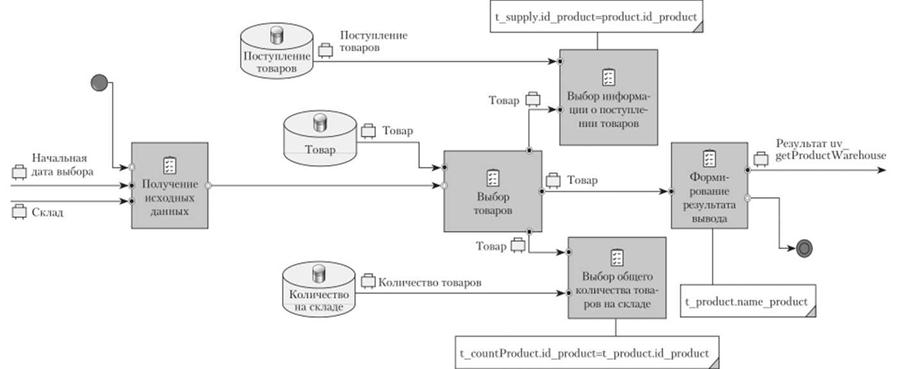
данные не содержат сведений, которые могут ограничить количество выбираемых записей. Результатом выборки из таблицы "Товары" получается набор записей таблицы со всеми полями, имеющимися в таблице. Это объясняет наличие в качестве результата операции выборки бизнес-элемента "Товар", который характеризует хранилище "Товары". А поскольку информация о товарах должна быть представлена в результате, то этот выход соединяется с задачей формирования результата.
Поскольку таблицы "Поступление товаров" и "Количество товаров" имеют среди своих атрибутов идентификатор товара, то связывание по этому атрибуту с таблицей "Товары" является обоснованным шагом, что и отражается в модели (рис. 5.62).
Однако подсоединение таблиц не является завершающей частью, поскольку на них не наложены ограничения выборки, которые определены исходными данными (рис. 5.63). Для этого задача получения исходных данных соединяется с задачами выборки данных, где используют эти сведения, учитывая необходимые объемы сведений.
Важно понимать, что для выборки информации о поступлении товаров необходимо использовать все исходные данные, что может быть представлено (отображено на модели) комплексным бизнес-элементом, а также отдельными информационными бизнес-элементами, как это обеспечено по связи с выборкой общего количества товаров на складе. Использование комплексного бизнес-элемента обусловлено минимизацией связей между задачами. Но эту проблему можно решить еще другим способом — связи между задачами могут быть разделены (пункт "Разделить" в контекстном меню связи), тогда пересечения связей не будет и такую диаграмму будет легче читать, но большое количество разделений также приводит к путанице при чтении модели. В описании условий по ограничениям в соответствующих задачах указываются правила связывания таблиц и наложения дополнительных ограничений на основе исходных данных.
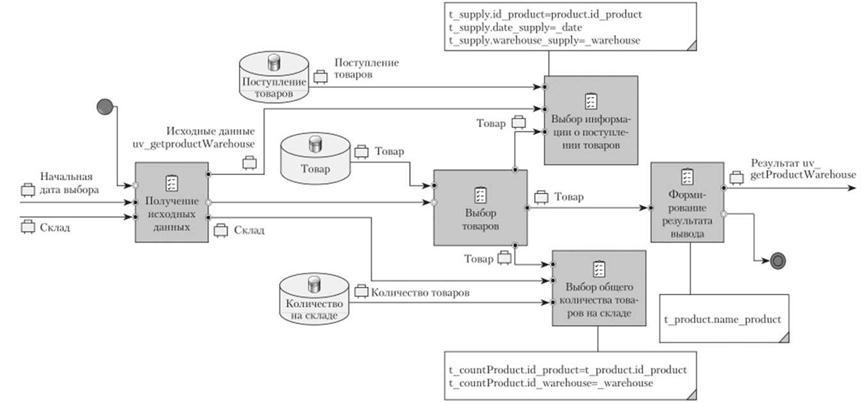
Теперь осталось выполнить простую операцию — связать задачи с результатом вывода (рис. 5.64).
В описании задачи формирования результата показываются сведения о полях, которые должны участвовать в результате выборки. Поскольку в условии примера указано, что данные необходимо отсортировать, то эта операция должна быть также отражена в модели. При этом нужно учитывать, что операции выборки по ограничениям на результат выборки, группировка, вычисление статистических данных, сортировка и ограничения на статистические вычисления выполняются после всей выборки и основываются на всех результатах, то их выполнение указывается после задачи формирования результата вывода (рис. 5.65).
Добавив задачу сортировки, необходимо указать набор полей, по которым будет осуществляться сортировка данных. Если тип сортировки (возрастание, убывание) не указан, то, как и в операциях выборки языка 50,Ц подразумевается сортировка по возрастанию.
Таким образом, получается законченная модель выборки данных по запросам пользователей. Если в выборке должны участвовать функции и подзапросы, то эти элементы представляются отдельными процессами и включаются в модель в качестве глобальных или локальных подпроцессов.
|
Рис. 5.61. Подсоединение выборки товаров |

|
Рис. 5.62. Подсоединение остальных таблиц |
|
Рис. 5.63. Наложение ограничений на таблицы |
|
Рис. 5.64. Пример модели выборки |
|
Рис. 5.65. Добавление сортировки |