Моделирование и описание сущностей
Основу модели базы данных в любой диаграмме составляют сущности и связи, которые впоследствии трансформируются в таблицы и связи базы данных. Создание сущностей выполняется при формировании диаграммы модели базы данных. Визуальное представление модели является неотъемлемой частью проектирования базы данных, поскольку оно позволяет разработчику легче анализировать возникающие некорректности в модели и представить модель в виде, удобном для рассмотрения заказчиком и другими разработчиками.
Для формирования элементов диаграммы используется палитра элементов ("Palette", рис. 3.49), где размещена область "Data" с объектами "Entity" (сущность) и связи. Выбор элемента палитры "Entity" (сущность) предоставит пользователю возможность создать объект "Сущность" на диаграмме, в результате чего необходимо ввести название сущности.
|
Рис. 3.49. Палитра для создания объекта "Сущность" |
Создание сущностей может быть также реализовано через контекстное меню папки "Package..." (пакет...), где пункт меню "Add Data Object/ Entity" (Добавить новый объект/Сущность) создаст сущность в дереве проекта и предоставит разработчику возможность, как и на диаграмме, ввести название сущности (рис. 3.50).
|
Рис. 3.50. Созданный объект модели "Сущность" |

Также возможно создание сущностей непосредственно на диаграмме с помощью контекстно-зависимого графического меню. Для этого необходимо навести курсор "мыши" на пустое пространство диаграммы и не двигать ее некоторое время, что приведет к появлению области с пиктограммами, обозначающими возможность создания допустимых элементов. Для логической модели базы данных будет выведена только одна пиктограмма, обозначающая возможность создания сущности. Ее выбор, как и в предыдущих случаях, создаст новую сущность с предложением ввести ее название.
В закладке свойств сущности "Volumetries" (Измерители) разработчик может указать параметры изменения количества экземпляров рассматриваемой сущности (рис. 3.51), среди которых:
• Initial number of rows (начальное количество экземпляров) — указывает на то количество данных (экземпляров), которое должно быть добавлено сразу после создания таблицы;
• Row growth per month (добавление экземпляров в месяц) — указывает, какое количество экземпляров должно добавляться в месяц;
• Maximum number of rows (максимальное количество экземпляров) — указывает на максимальное количество экземпляров, которое может храниться в таблице, описываемой рассматриваемой сущностью.
|
|
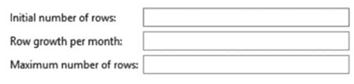
Рис. '3.51. Установление параметров изменения
количественных показателей сущности
В разделе свойств сущности среди параметров закладки "General" (основное) разработчику предлагается установить дополнительный параметр "Persistent" (постоянный), который определяет возможность трансформации сущности в таблицу при переходе от логической к физической модели базы данных. Но вся информация о структуре будущей базы данных заложена в связях между сущностями и атрибутах, которые характеризуются значительно большим количество параметров. Используя закладку "Attributes" (атрибуты), можно создать атрибуты сущности и определить их основные параметры.
Также, аналогично созданию сущности, атрибуты могут быть созданы различными способами (рис. 3.52):
- с помощью контекстного меню — используется контекстное меню сущности в дереве проектов, где предоставляется возможность выбрать объект для создания — атрибут, альтернативный ключ, ограничение и т.д.;
— с помощью свойств сущности — используется область свойств в закладке "Attributes" (атрибуты), где с помощью имеющегося там инструментария создаются и специфицируются атрибуты;
с помощью графического меню диафаммы — используется графическое меню с пиктограммами при наведении "мыши" на сущность, с помощью которого создаются первичный ключ и простые атрибуты с предоставлением возможности указать название атрибута.
|
|

Puc. 3.52. Пример создания атрибута
через свойства сущности
При использовании свойств сущности разработчик в закладке "Attributes" (атрибуты), используя пиктограмму со знаком "+", создает новые атрибуты, после чего должен определить основные параметры созданного атрибута:
• Name (наименование) — наименование атрибута, по которому определяется содержательный смысл описываемых данных;
• Primary Key (первичный ключ) — признак, обозначающий, что атрибут является элементом первичного ключа и для него необходимо создать соответствующие ограничения целостности;
• Surrogate Key (суррогатный ключ) — признак, обозначающий, что атрибут не является элементом предметной области, но необходим для эффективной работы с базой данных и будет содержать значения, автоматически генерируемые в соответствии с правилами арифметической прогрессии;
• Туре (тип) — тип данных, которым описываются значения, представляемые атрибутом;
• Length/Precision (размер/точиость) — числовое значение, обозначающее количество символов (байт), необходимых для хранения максимального значения по описываемому атрибуту;
• Scale (масштаб) — числовое значение, используемое для числовых атрибутов, которое описывает количество знаков после десятичной точки при работе с вещественными числами;
• Required (обязательность) — признак невозможности хранения по атрибуту пустого значения NULL;
• Derived (вычисляемое) — признак необходимости вычисления значения по определенному выражению, используя математические, лингвистические операции и различные функции языка СУБД;
• Default Value (значение умолчания) — значение, которое должно записываться, если при добавлении или изменении данных для атрибута не было определено;
• Derivation Expression (вычисляемое выражение) — формульное выражение, которое должно вычисляться при добавлении или изменении данных.
Важно отметить, что инструментальное средство предоставляет возможности сортировки атрибутов в сущности в нужном разработчику порядке. Осуществляется это с помощью пиктограмм управления в виде разнонаправленных стрелок. Однако с учетом того, что правилами Кодда определяется независимость от порядка расположения атрибутов, установление порядка не является необходимой составляющей в модели базы данных. Есть две причины, чтобы выстраивать необходимый порядок атрибутов:
— удобство работы — при выстраивании порядка атрибутов по определенным правилам (например, первыми должны идти атрибуты, обозначающие первичный ключ, далее нужно разместить внешние ключи, потом альтернативный ключ и простые атрибуты) легче читать диаграмму модели и идентифицировать некоторые проблемные ситуации, которые могут возникнуть при практической работе с базой данных;использование особых технологий обработки — при добавлении данных в языке SQL предусматривается возможность не указывать перечень
нолей таблицы, в которые будут вноситься указанные в команде данные, что требует от разработчика программного кода знания о точном порядке полей в таблице, которое на уровне логической модели может быть определено сортировкой атрибутов.
Помимо установления характеристик для каждого атрибута, включая задание значения по умолчанию и формульного выражения для вычисления, любая сущность может иметь ограничения целостности, обеспечивающие корректное хранение значения по соответствующему атрибуту. Например, для атрибута, хранящего значения годов, может быть необходимым ограничить минимальное значение. Поскольку на уровне построения логической модели разработчик может не знать о том, какая СУБД будет применяться для реализации, то использование функций на любом из языков программирования не будет корректным. Однако инструментальное средство IBM InfoSphere Data Architect предоставляет возможность разработчику указать условие ограничения на нескольких языках (рис. 3.53):
• OCL (Object Constraint Language) — язык ограничений для объектов, применяемый при объектно-ориентированном представлении данных и программы приложения, достаточно редко применяемый при реализации реляционных баз данных, использует стандартные логические выражения и указания на атрибуты сущностей (например: Сущность. Год >= 2000):
• SQL (Structured Query Language) — язык структурированных запросов, применяемый при обработке реляционных баз данных, обычно ориентирован на конкретную СУБД и имеет множество функций, присущих только выбранной СУБД, использует логические операции (AND (И), OR (ИЛИ) и др.) и применяет их на уровне атрибута рассматриваемой сущности (например: Год >= 2000 and Год < 2100);
• English — естественный язык, непереводимый в язык программирования, обычно применяемый для описания ограничения с последующим представлением в процессе программирования соответствующим логическим выражением (например: Год представляется значением в диапазоне [2000; 2100));
• XML (Extended Mark Language) — язык расширенной разметки, применяемый для описания иерархически структурированных сведений, для ограничений используется в рамках специализированных языковых логических выражений по обработке действий надданными XML-документа.
|
Рис. 3.53. Настройка ограничения целостности |

Создание нового ограничения целостности выполняется с помощью контекстного меню сущности в дереве проектов "Add New Object/Constraint" (Добавить новый объект/Ограничсние). В результате разработчику в области свойств объекта будет предложено ввести наименование ограничения, которое обычно представляется латинскими символами, что объясняется необходимостью последующего его трансформирования в ограничение физической модели и физической базы данных, которые зачастую не могут корректно обрабатывать объекты, названные с использованием национального алфавита.
Кроме наименования ограничения разработчик определяет язык, на котором представлено логическое выражение для ограничения. Здесь важно понимать, каким образом далее будет это ограничение обрабатываться. Если предполагается, что ограничение должно быть трансформировано в условия на языке программирования, то применяется один из языков (OCL, SQL, XML), из которых для реляционных баз данных используется язык SQL. Если трансформация не предусматривается, а программист базы данных должен будет самостоятельно, учитывая описание ограничения, сформулировать логическое выражение, то оно может быть представлено на естественном языке.
При использовании любого из языков программирования разработчик, используя правила этого языка, в поле "Expression" (выражение) указывает необходимое выражение, а также определяет одно из правил трансформации:
— None (отсутствует) — трансформация логического выражения не предусматривается и ограничение может быть выведено только в отчете по логической модели базы данных;
— Check Constraint (проверочное ограничение) — трансформация переведет указанное выражение в соответствующее логическое выражение па указанном языке программирования, учитывая особенности выбранной для физической модели базы данных СУБД;
Trigger (триггер) трансформация приведет к созданию программного модуля автоматической обработки (триггер), который будет выполняться при запуске операций добавления, изменения или удаления данных.
Как правило, поскольку ограничение уровня сущности и атрибута представляется простым логическим выражением, то наиболее частым вариантом трансформации ограничения является Check Constraint (проверочное ограничение), подчиняющееся правилам построения логических выражений и возвращающее в качестве результата выполнения логическое значение "True" (истина) или "False" (ложь).
При использовании варианта трансформации "Trigger" (триггер) разработчиком базы данных может быть, в рамках последующего программирования, создан программный код, обрабатывающий не только проверяемые экземпляр (запись), поле или таблицу, но и другие экземпляры (записи) и таблицы базы данных.
Иногда разработчики базы данных, понимая, что некоторые атрибуты не должны использоваться в качестве первичных ключей, но при этом обладают ограничениями, которые накладываются на ключевые атрибуты, создают альтернативные ключи (рис. 3.54). Как правило, такая ситуация возникает, если в качестве ключевого атрибута должны выступать атрибут
символьного типа или группа атрибутов, формирующая сцепленный ключ в родительской сущности. Эти варианты требуют создания суррогатных ключей, представляемых в качестве первичного ключа, а также определения альтернативного ключа с наложением соответствующих ограничений: уникальное значение в пределах сущности и невозможность хранения пустого значения NULL.
|
Puc. 334. Описание альтернативного ключа |
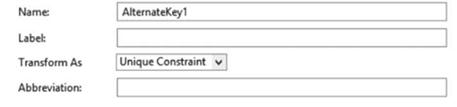
Для реализации этой задачи (создание альтернативного ключа) разработчик, используя контекстное меню сущности в дереве проектов "Add New Object/Alternate Key" (Добавить новый объект/Альтернативный ключ), создает необходимый объект и в области свойств объекта на закладке "General" (Основное) указывает наименование ключа (как правило, используя латинские символы) и тип трансформации ключа в физическую модель базы данных:
• Unique Constraint (уникальное ограничение) — проверка уникальности значения осуществляется на основании программной обработки таблицы с применения языка базы данных;
• Unique Index (уникальный индекс) — проверка реализуется на основании механизма индексирования данных по указанным атрибутам ключа без создания специализированного программного модуля.
В закладке "Key Attributes" (атрибуты ключа) разработчик указывает состав ключа из перечня атрибутов, сформированных для рассматриваемой сущности. Именно указанные для ключа атрибуты будут обрабатываться при обеспечении уникальности значений. Причем если выбрано несколько атрибутов (сцепленный ключ), то уникальность будет обеспечиваться на уровне совокупности значений по всем атрибутам.