Микроархитектура NetBurst
Микроархитектура NetBurst пришла на смену микроархитектуре Р6. На ее основе был создан ряд процессоров Pentium 4, первые из которых появились на свет в конце 2000 г.
Основным препятствием в дальнейшем повышении производительности процессоров микроархитектуры Р6 при тогдашнем уровне технологии в 0,18 мкм было число схемотехнических элементов в одной ступени 12-ступенчатого конвейера. Относительно большая длина ступени приводила к тому, что предельная частота, с которой мог работать такой конвейер, находилась в районе 1,1-=-1,2 ГГц. Предвидя эту ситуацию, специалисты фирмы Intel заранее приступили к проектированию процессора с новой микроархитектурой, основу которой составил 20-ступенчатый конвейер. Поскольку число схемотехнических элементов в одной ступени конвейера существенно уменьшалось, это позволяло повысить тактовую частоту работы процессора. При проектировании процессора планировалось, что основным его приложением были бы задачи с минимальным числом ветвлений, среди которых основное место занимали бы приложения, непосредственно связанные с Internet. Отсюда и громкое название микроархитектуры, которое можно перевести как "сетевой взрыв".
В основу микроархитектуры NetBurst вошли все перспективные наработки, применявшиеся ранее в архитектуре процессоров семейства Р6, а также были разработаны и новые архитектурные решения.
NetBurst была положена в основу микропроцессоров седьмого поколения Pentium 4, Pentium D, Celeron и Xeon. Первые процессоры архитектуры NetBurst были анонсированы 20 ноября 2000 г., а 8 августа 2007 г. компания Intel объявила о начале действия программы по снятию с производства всех процессоров этой архитектуры. Им на смену пришли двухъядерные процессоры семейства Core 2 Duo.
Структура процессоров NetBurst
Процессоры архитектуры NetBurst состоят из четырех основных подсистем (рис. 5.2):
• входной;
• исполнения с изменением последовательности;
• исполнения;
• памяти.
Входная подсистема выполняет предварительную выборку данных, предсказание переходов и преобразование сложных команд х86 в простые внутренние МО.
Подсистема исполнения с изменением последовательности обеспечивает исполнение МО в оптимальном порядке.
Подсистема исполнения состоит из набора блоков, осуществляющих выполнение МО, и узлов, обеспечивающих взаимодействие исполнительных блоков.
Подсистема памяти состоит из группы узлов, обеспечивающих взаимодействие процессора с оперативной памятью.
Входная подсистема
К устройствам этой подсистемы относятся следующие узлы.
Блок предварительной выборки команд. Этот узел выполняет предварительную выборку команд программы (в кодах х86) на основании данных из входного буфера предсказания переходов и преобразование программного адреса команды в физический с помощью таблицы трансляции адресов, входящей в состав этого блока.

Рис. 5.2. Функциональная схема процессоров NetBurst
Входной буфер предсказания переходов. Узел хранит таблицу ранее выполненных переходов объемом 4 Кбайта. Это в восемь раз больше, чем у процессоров Р6, что позволяет хранить более подробную историю предыдущих переходов. Также в NetBurst применен более совершенный алгоритм предсказания переходов, что вместе с расширенным объемом таблицы переходов обеспечивает вероятность удачного предсказания следующего адреса перехода около 93-94%.
Дешифратор команд. Как и в процессорах Р6, узел выполняет преобразование сложных CISC-команд х86 в последовательность более простых RISC-МО, исполняемых процессором.
Кэш последовательностей МО. Этот узел не имеет аналогов в архитектуре Р6, в чем заключается одна из инноваций архитектуры NetBurst. Кэш последовательностей МО обеспечивает исполнительные устройства постоянным потоком микроопераций, что минимизирует возможные простои. В него заносятся последовательности декодированных внутренних МО, готовых к исполнению, т.е. если в архитектуре Р6 кэш команд первого уровня находился до дешифратора, то теперь он расположен после него, что существенно сокращает время выполнения команд х86 при их многократном повторном исполнении в циклических программах, поскольку избавляет от необходимости выполнять дешифрацию.
МО упорядочиваются в соответствии с несколькими предсказанными ветвями программы, для чего используется буфер предсказания переходов для кэш МО. Кэш последовательностей МО имеет объем 12 Кбайт и может хранить несколько достаточно длинных фрагментов программы – так называемых трасс (рис. 5.3). Он разбит на 2048 блоков, организованных в 256 наборов по восемь блоков. Каждый блок состоит из шести ячеек и может хранить до шести МО (т.е. по одной ячейке на МО). Если же команда х86 использует непосредственный способ адресации, т.е. содержит операнд, или адрес, то соответствующая ей МО может занять более чем одну ячейку.
Как правило, трасса начинается с МО, на которую следует переход в командах условного перехода (на рис. 5.3 начало трассы отмечено тегами К). При линейном следовании команд исходной программы трасса естественным образом повторяет ход программы. Однако при появлении ветвлений она не прекращается. В соответствии с вероятным направлением продолжения программы в нее добавляются МО, следующие за командой условного перехода. Более того, в циклических программах одни и те же группы МО в трассе (соответствующие одной из ветвей) могут многократно повторяться и следовать друг за другом, т.е. трасса как бы "разворачивает" циклическую программу в линейную последовательность команд. Взаимосвязь между блоками устанавливается с помощью тегов. Максимальное число блоков в трассе – 64, после чего она обрывается. Если трасса формируется на линейном участке программы, то она "нарезается" на куски этой длины.
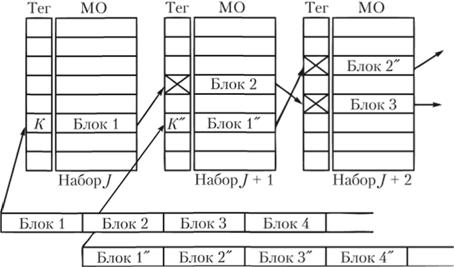
Рис. 5.3. Схема формирования трасс в кэш последовательностей МО
Буфер предсказания переходов для кэш МО. Этот узел, так же как и входной буфер предсказания переходов, хранит таблицу ранее выполненных переходов, объем которой меньше – 512 Байт. На основе данных таблицы переходов этого узла формируются трассы.
ROM микрокодов. Здесь хранятся микропрограммы исполнения сложных CISC-команд х86. Если CISC-команда может быть преобразована в набор, состоящий от одной до четырех простых RISC-МО, то дешифратор команд заносит их в кэш последовательностей МО. Для сложных CISC-команд в кэш вместо МО заносится адрес
ROM микрокодов, по которому располагается микропрограмма исполнения сложной команды.
Очередь микроопераций. Этот узел хранит очередь полностью декодированных МО (включая и сложные, декодированные с помощью ROM микрокодов), куда они заносятся из кэш последовательностей МО порциями по три микрооперации за такт. Узел является аналогом пула команд у процессора Р6, но объем его существенно больше – до 126 МО. Кроме того, установление связей между логическими регистрами х86 и их физическими аналогами здесь еще не выполнено. Больший поток МО предоставляет процессору более широкие возможности по реализации стратегии динамического исполнения команд программы с изменением последовательности out-of-order.