Микроархитектура многоядерных процессоров
В начале XXI в. стало ясно, что дальнейшее увеличение производительности процессоров, построенных на основе одного ядра, будет ограничиваться растущим энергопотреблением. В то же время возможности технологии, уменьшение технологической нормы позволяли реализовывать в одном кристалле до несколько сотен миллионов транзисторов. В этих условиях ведущие разработчики процессоров, как Intel, так и AMD, приняли решение, что дальнейшее повышение производительности возможно за счет совмещения в одном кристалле двух и более процессорных ядер. С учетом того, что режим работы компьютера многозадачный, это позволяло существенно повысить его производительность.
В 2005 г. практически одновременно оба ведущих производителя представили свои двухъядерные процессоры: в марте фирма Intel – процессор Smithfield, в мае фирма AMD – процессор Opteron 2хх.
Первые двухъядерные процессоры просто объединяли в одном корпусе два ядра, которые ранее реализовывались в виде одноядерных процессоров. Так, процессор Smithfield практически совмещал в одном кристалле кремния два процессорных ядра, аналогичных Prescott, которые были подключены к общей системной шине. Напомним, что в процессоре Prescott была использована микроархитектура Net Burst. Затем Intel выпустила еще один двухъядерный процессор Presler с той же микроархитектурой. Он был реализован по технологии 65 нм и схемотехнически просто объединял в одном корпусе два кристалла, на каждом из которых располагался одноядерный процессор. На этом эра микроархитектуры NetBurst закончилась.
Будущее многоядерных процессоров фирмы Intel разработчики связали с развитием микроархитектуры Р6. Первым двухъядерным процессором, ядра которого были реализованы на этой базе, стал Yonah, появившийся в январе 2006 г. В нем уже была общая для обоих ядер инфраструктура: кэш второго уровня и контроллер системной шины. Процессор Yonah можно рассматривать как последний представитель базовой микроархитектуры Р6. Вслед за ним летом 2006 г. фирма Intel представила процессоры, построенные на основе новой микроархитектуры, специально разработанной для реализации многоядерных процессоров, которая во многом опиралась на базовую структуру Р6, но имела и много нововведений. Она получила название Intel Core, в ней снова стал использоваться короткий конвейер, состоящий из 14 ступеней (в последних модификациях Pentium 4 на ядре Prescott число ступеней конвейера было доведено до 30).
Наконец, в конце 2008 г. Intel представила процессоры, построенные на базе новой микроархитектуры Nehalem, которая также, в свою очередь, стала развитием Intel Core. Разумеется, и Intel Core, и Nehalem – это микроархитектуры новых поколений с большим объемом нововведений. И все же отправной точкой для всех многоядерных процессоров фирмы Intel, начиная с 2006 г., стала микроархитектура Р6.
Микроархитектура Nehalem
Микроархитектура Nehalem была разработана для многоядерных процессоров фирмы Intel, ориентированных на использование в высокопроизводительных персональных компьютерах и серверных системах. На ее базе выпускались двух-, четырех- и восьмиядерные процессоры. Она использует базовые наработки, созданные при проектировании микроархитектуры Intel Core, но имеет и целый ряд усовершенствований.
При разработке схемотехники своих многоядерных процессоров фирма Intel стала использовать совершенно новые материалы для реализации транзисторов. С уменьшением технологической нормы и ростом числа транзисторов в кристалле процессора уменьшалась толщина изолирующего слоя – диоксида кремния, пока не достигла значения 1,2 нм, или 5 атомов. По мере уменьшения толщины изолирующего слоя рос ток утечки, а вместе с ним и рассеиваемая мощность. Для снижения токов утечки нужно было увеличить толщину изолирующего слоя, который для сохранения характера взаимодействия затвора и канала транзистора должен был обладать более высоким коэффициентом диэлектрической проницаемости. В 2007 г. инженеры фирмы Intel разработали технологию изготовления изолирующего слоя не из диоксида кремния, а из материала на основе гафния, которая позволила снизить ток утечки в десять раз. Однако новый материал оказался несовместимым с затвором транзистора. Транзисторы с новым изолирующим материалом работали менее эффективно, чем со старым. Тогда было предложено заменить и материал затвора: корпорация Intel открыла уникальное сочетание металлов, состав которого держится в строгом секрете. Новые технологии реализации транзисторов позволили перейти на более низкую технологическую норму – с 65 на 45 нм, что обеспечило увеличение числа транзисторов, размещаемых на той же площади. При этом снизилась мощность процессов включения-выключения транзистора и повысилась скорость переключения.
Существенным недостатком процессоров Intel Core стал их немодульный дизайн. Дело в том, что они изначально проектировались как двухъядерные полупроводниковые кристаллы. Поэтому четырех- и шестиядерные представители микроархитектуры Core просто собирались из нескольких двухъядерных кристаллов, а это приводило к затруднению взаимодействия между ними. Обмен данными между разрозненными ядрами организовывался через системную память. Конечно, такой подход к реализации обмена вызывал большие задержки, обусловленные ограниченной пропускной способностью процессорной шины.
В отличие от процессоров Intel Core микроархитектура процессоров Nehalem создавалась с ориентацией на модульный дизайн. Она включает в себя лишь несколько основных электронных модулей, из которых на этапе конечного проектирования и производства, как из строительных блоков, может быть собран итоговый процессор. Этот набор включает в себя процессорное ядро, кэш-память, контроллеры системной шины и памяти и т.д.
На этапе проектирования процессора необходимые модули собирают в едином полупроводниковом кристалле. В зависимости от назначения процессора в него включают то или иное число модулей. Например, процессор для персональных компьютеров может иметь два процессорных ядра, одну кэш-память, а также одни контроллер памяти и контроллер системной шины.
Серверный процессор может включать в себя уже восемь ядер, несколько контроллеров системной шины для объединения в многопроцессорные системы, кэш-память и контроллер памяти.
В соответствии с модульной концепцией в процессорах Nehalem выделяются два уровня. На нервом расположены ядра процессора, второй объединяет устройства, общие для всех ядер. Прежде всего, это кэш третьего уровня (у процессоров Intel Core общим был кэш второго уровня). Второй компонент второго уровня у процессоров Nehalem – контроллер системной шины, третий – общий контроллер оперативной памяти.
Для Nehalem был разработан новый интерфейс, связывающий процессор с микросхемами материнской платы, обеспечивающими его взаимодействие с памятью и внешними устройствами (чип-сетом). Этот интерфейс основан на использовании новой системной шины, получившей название Intel QuickPath Interconnect (QPI). Шина QPI является двунаправленной и состоит из 20 пар линий, каждая из пар передаст один бит – 16 для данных и 4 – для служебных сигналов. Шина QPI повышает скорость передачи данных по сравнению с ранее использовавшейся, начиная с процессоров Pentium 4, шиной Quad-Pumped Bus в 4–8 раз. Она используется как для связи ядер процессора с чип-сетом, так и для связи их между собой. Шина QPI обеспечивает невиданную для всех более ранних процессоров фирмы Intel скорость обмена данными – свыше 25 Гбайт/с.
В некоторые модели процессоров Nehalem во втором уровне также устанавливается общий графический контроллер.
Процессоры Nehalem могут поддерживать технологию многопоточной обработки Simultaneous Multi-Threading, которая известна под названием Hyper Threading. Напомним, что она использовалась еще в некоторых процессорах Intel Pentium 4 с микроархитектурой NetBurst, однако в процессорах с микроархитектурой Intel Core она отсутствовала. Благодаря наличию технологии Hyper Threading операционная система компьютера будет рассматривать двухъядерный процессор Nehalem как четыре, а четырехъядерный – как восемь отдельных логических процессоров.
Очень важной чертой микроархитектуры Nehalem стала высокая эффективность энергопотребления. Все схемотехнические компоненты процессора разрабатывались исходя из критерия энергосбережения. Внедрена инновационная система управления электропитанием ядер процессора. Фактически в него встроен специальный контроллер питания, который контролирует температуру и силу тока потребления каждого ядра и в зависимости от этого управляет их напряжением питания и тактовой частотой. В результате энергопотребление ядер, не задействованных в процессе выполнения программ, резко снижается.
Функциональная схема процессора с микроархитектурой Nehalem показана на рис. 5.5.
Как уже отмечалось, микроархитектуры процессоров Intel Core и Nehalem имеют много общего с Р6, но в них также есть и целый ряд принципиальных нововведений, что позволило разработчикам Intel позиционировать их как принципиально новые поколения. Рассмотрим эти новые микроархитектуры на примере процессоров Nehalem.
Цикл выполнения команд здесь, как и в процессорах Р6, начинается с работы буфера предсказания переходов (на рис. 5.5 не показан). Блок выборки команд на основе данных буфера осуществляет выбор наиболее вероятной ветви программы и ввод из кэш второго уровня целых блоков команд. Как и в процессорах Р6, выборка команд из кэша выполняется 16-байтными блоками, причем время выборки составляет 1 такт. Поскольку блок имеет фиксированную длину, а команды х86 могут содержать разное число байтов, в нем необходимо выделить границы команд (в процессорах Р6 выполнялось в процедуре выравнивания). В процессорах Nehalem эта процедура именуется преддешифрацией.
После преддешифрации команды порциями по четыре поступают в очередь команд (этот блок в процессорах Р6 отсутствовал). Отсюда они с тактовой частотой теми же порциями поступают в дешифратор.
Дешифратор процессора Nehalem очень похож на Р6. Только здесь простых дешифраторов не два, а три. Сложные (состоящие из 2–4 МО) команды декодируются в дешифраторе сложных команд. Наконец, команды, для декодирования которых требуется больше чем 4 МО, поступают в ROM микрокодов МО (аналогичный узел в Р6 назывался планировщиком последовательностей МО).
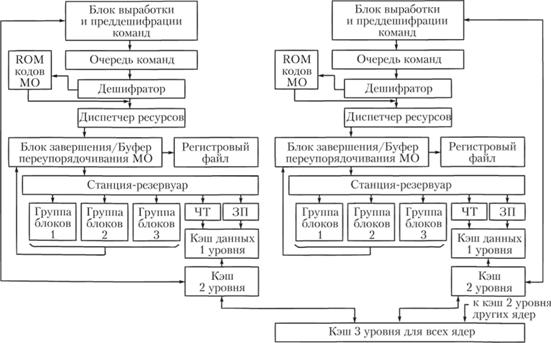
Рис. 5.5. Функциональная схема процессоров с микроархитектурой Nehalem
Из дешифратора МО порциями по четыре за такт поступают в очередь МО. Разумеется, это возможно только тогда, когда четыре команды х86 занимают не более 16 байтов.
В процессорах Intel Core и Nehalem введена технология обнаружения циклов программ. Для этого в состав блока выборки и преддешифрации команд введен блок обнаружения программных циклов. Он принимает непосредственное участие в процессах выборки команд из кэша и содержит буфер ранее выбранных команд программных циклов. Если блок обнаруживает в программе команды цикла, которые уже имеются в буфере, они непосредственно из буфера поступают на исполнение. В процессорах Intel Core это позволяет исключить из конвейера стадию выборки команд. В процессорах Nehalem технология обнаружения программных циклов была усовершенствована. Буфер ранее выбранных команд был расширен с 18 до 28 команд. Кроме того, его расположили не до, а после дешифратора, и хранить он стал уже декодированные команды. Можно сказать, что эта технология хранения уже декодированных участков программ была взята из архитектуры NetBurst. Это нововведение еще больше сократило цикл выполнения команды.
Еще одной инновацией в процессорах Intel Core и Nehalem стала технология так называемых слияний на уровне команд и МО. Технология слияния команд (MacroFusion) заключается в том, что некоторые пары команд, следующие друг за другом, сливаются в одну внутреннюю МО, которая затем будет исполняться именно как одна МО.
Первой командой, подлежащей слиянию, может выступать команда сравнения СМР. Напомним, что она выполняет вычитание двух операндов, формируя при этом признаки результата – флажки, но сам результат вычитания при этом не сохраняет. Она выполняется только для того, чтобы получить признаки результата, которые затем нужны для выполнения команды условного перехода, в качестве которой может выступить команда "перейти, если меньше" JL, "перейти, если больше" JNL, "перейти, если результат равен нулю" JZ или любая подобная. По существу, команда сравнения всегда выполняется вместе со следующей за ней командой условного перехода. Значит, их было бы целесообразно объединить в одну. Эту задачу и выполняет технология MacroFusion.
Для реализации таких "сдвоенных" МО в процессоре есть соответствующие исполнительные блоки. Следовательно, теперь за счет технологии слияния пять старых команд х86 преобразуются в четыре МО, которые процессор может передать на исполнение за один такт.
Кроме технологии MacroFusion, в процессорах также была внедрена технология слияния микроопераций (Microops fusion). Она заключается в том, что в ряде случаев две МО сливаются в одну, содержащую два элементарных действия. Любая х86-команда, как правило, разбивается на несколько МО. Технология Micro-ops fusion позволяет объединить две одинаковые МО, относящиеся к двум разным командам х86, в одну слитую, которая и будет обрабатываться как одна МО. В результате число обрабатываемых МО снижается, а производительность процессора растет. В дальнейшем результат такой МО расслаивается, чтобы восстановить исходный ход программы.
После декодирования команд х86 и преобразования их в потоки МО начинается этап исполнения. В диспетчере ресурсов выполняется процедура закрепления за МО, использующими в качестве операндов одни и те же логические регистры х86, реальных физических регистров процессора, разных для разных МО (в структуре процессоров Р6 эту роль играла таблица назначения регистров). Эта процедура необходима для организации внеочередного выполнения команд.
Затем поток МО порциями заносится в буфер переупорядочивания МО, откуда они поступают в станцию-резервуар, которая осуществляет проверку их готовности (в зависимости от наличия операндов) и отправку на исполнение. Данные для этого берутся либо из буфера переупорядочивания, либо из регистрового файла. Буфер переупорядочивания МО и блок завершения совмещены в одном устройстве, но работа блока завершения начинается уже после того, как МО будут выполнены, т.е. когда становится возможным восстановить исходный порядок их следования в соответствии с порядком следования команд х86 в исполняемой программе.
Из станции-резервуара через специальные порты диспетчеризации, аналогичные портам в микроархитектурах Р6 и NetBurst, МО поступают к группам (кластерам – cluster) исполнительных блоков (рис. 5.6). Всего портов шесть, каждый связан со своими группами исполнительных блоков. Станция-резервуар может выдавать на исполнение по шесть МО за такт, т.е. через все шесть портов (разумеется, если в станции-резервуаре есть необходимые МО и соответствующие им исполнительные блоки свободны).
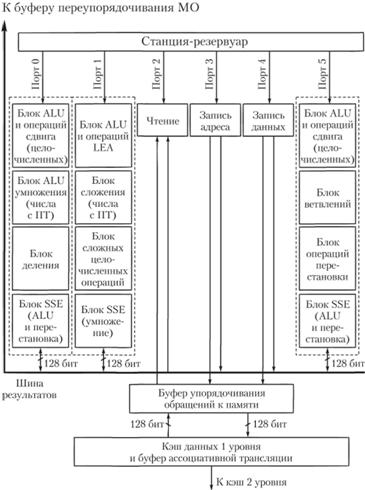
Рис. 5.6. Группы исполнительных блоков процессоров Nehalem и их взаимодействие с ядром процессора
Порты 0, 1 и 5 обеспечивают загрузку групп вычислительных блоков, порты 2, 3, 4 – блоков для работы с памятью.
Таким образом, всего одновременно могут исполняться три вычислительные МО и три операции по работе с памятью.
Исполнительное ядро многоядерных процессоров Intel было спроектировано первоначально для микроархитектуры Intel Core. В микроархитектуре Nehalem были введены изменения, направленные на улучшение работы исполнительного ядра, но в целом оно базируется на разработках микроархитектуры Intel Core.
Исполнительные блоки в процессорах Intel Core и Nehalem представлены гораздо богаче, чем в предшествующих микроархитектурах даже самых последних модификаций – как Р6, так и NetBurst. Именно они в конечном итоге обеспечивают высокую производительность процессора, и вся его структура направлена на обеспечение эффективной загрузки исполнительных блоков.
В каждой группе вычислительных блоков есть блоки для работы с целыми числами, числами с ПТ и выполнения потоковых векторных операций над множественными данными (SIMD).
Для наглядного представления возможностей исполнительных блоков процессоров Nehalem по выполнению различных МО воспользуемся табл. 5.1.
Таблица 5.1
|
Порт |
Тип вычислений |
Выполняемые операции |
Число тактов |
|
Порт 0 |
Целочисленный |
Арифметико-логические (ALU) Операции сдвига |
1 1 |
|
Порт 0 |
Векторный |
SIMD – арифметико-логические (ALU) |
1 |
|
SIMI) – перестановка |
1 |
||
|
Порт 0 |
С плавающей точкой |
Умножение |
4 |
|
Умножение с двойной точностью |
5 |
||
|
Операции FP/SIMD/SSE (пересылка, логические) |
1 |
||
|
Операции перестановки |
1 |
||
|
Операции деления и вычисления квадратного корня |
4 бита за такт |
||
|
Порт 1 |
Целочисленный |
Арифметико-логические (ALU) |
1 |
|
Пересылка |
1 |
||
|
Умножение |
1 |
||
|
Порт 1 |
Векторный |
SIMD – умножение |
1 |
|
SIMD – сдвиг |
1 |
||
|
SIMD – вычисление абсолютной разности |
3 |
||
|
SIMD – сравнение строк |
3 |
||
|
Порт 1 |
С плавающей точкой |
Сложение |
3 |
|
Порт 2 |
Целочисленный |
Чтение |
4 |
|
Порт 3 |
Целочисленный |
Запись адреса |
5 |
|
Порт 4 |
Целочисленный |
Запись данных |
- |
|
Порт 5 |
Целочисленный |
Арифметико-логические (ALU) |
1 |
|
Операции сдвига |
1 |
||
|
Операции перехода |
1 |
||
|
Порт 5 |
Векторный |
SIMD – арифметико-логические (ALU) |
1 |
|
SIMD – перестановка |
1 |
||
|
Порт 5 |
С плавающей точкой |
Операции FP/SIMD/SSE (пересылка, логические) |
1 |
Как видно из табл. 5.1, подавляющее большинство операций, включая и векторные, выполняется за один такт. Исключение составляют традиционно сложные для процессоров операции – умножения и деления. Тем не менее, даже операция умножения с двойной точностью (64 бита) выполняется за пять тактов.
У ядер процессоров Соте и Nehalem есть три блока ALU для целочисленных вычислений, каждый из которых может исполнять однотактовые 64-битные целочисленные операции. Простые арифметико-логические целочисленные операции могут выполнять три блока. Все они способны выполнять операции над 64-битными операндами. Поскольку они расположены на разных портах, то теоретически (при наличии соответствующих команд в исходной программе) ядро процессора Nehalem может за один такт выполнять сразу три операции над целыми 64-разрядными числами.
Для выполнения сложных операций над целыми числами здесь, как и is ядре процессоров Р6, есть один 64-разрядный блок.
Пятый порт содержит блок для вычисления адресов переходов в операциях условного перехода (блок ветвлений). Он вместе с блоком ALU может работать параллельно над выполнением команд х86, объединенных в процессе реализации технологии MacroFusion.
Еще одной особенностью процессоров Core и Nehalem стало наличие специального блока для выполнения операций деления. Он реализует операции деления как над целыми числами, так и над числами с плавающей точкой. По сравнению со всеми предыдущими процессорами Intel используется усовершенствованный алгоритм деления, позволяющий за каждый шаг вычислять 4 бита частного, в то время как в более ранних процессорах вычислялись только 2 бита. Наличие специального блока деления обеспечивает повышение производительности научных вычислений, преобразования трехмерной графики и других функций с высоким ОГЛАВЛЕНИЕм математических вычислений.
В ядрах Core и Nehalem используются два исполнительных блока для вычислений с плавающей точкой, способных осуществлять как обычные (с двумя операндами), так и векторные арифметические операции. Блок, расположенный на порту №1, выполняет сложение и другие простые операции в форматах: для обычных операций – с одинарной (32 бит) и двойной (64 бит) точностью; для векторных операций – с одинарной (для четырех операндов) и двойной (для двух операндов) точностью. Исполнительный блок на порту №0 осуществляет операции умножения в этих же форматах.
Одно из важнейших улучшений в ядрах процессоров Core и Nehalem – блоки потоковых векторных операций над множественными данными (SIMD). Архитектура обеспечивает полноценную 128-битную обработку во всех векторных блоках. В предыдущих процессорах Intel у SIMD-блоков не было возможности работы с трехоперандными и 128-битными командами. Из-за этого они разбивались на пары команд, работающих с 64-битными операндами, которые выполнялись за два такта. Теперь этот недостаток был устранен, и SSE-команды, ранее выполнявшиеся за два, стали выполняться за один такт.
SIMD-блоки процессоров Intel Core и Nchalem стали поддерживать новый расширенный набор команд технологии SSE – SSE4. Он представляет собой самое значительное усовершенствование набора команд для мультимедийных приложений с 2001 г. Новый набор позволил существенно повысить производительность программных приложений по обработке графики, трехмерных изображений, видео, систем кодирования, компьютерных игр. Кроме того, он эффективно используется в программных приложениях, связанных с выполнением алгоритмов сжатия звука, изображений, данных и многих других приложений.
Полный набор команд SSE4, введенный у процессоров Intel Core, насчитывал 47 команд, у процессора Nehalem дополнительно было введено еще 7 команд. Все они работают с 128-битными регистрами.
Новый набор SSE4 содержит команды ускорения для кодирования и декодирования видеофайлов, вычисления векторных примитивов на основе целых чисел, вставки и извлечения 8-, 16-, 32- и 64-битных полей в 128-битные регистры для чисел с плавающей точкой, скалярного умножения векторов, смешивания для формирования операндов, проверки отдельных битов и групп, округления.
Чтобы получить представление о сложности действий, выполняемых исполнительными SIMD-блоками, кроме уже известного скалярного произведения векторов, рассмотрим еще одну команду.
При кодировании и сжатии видеоинформации кадры разбиваются на небольшие фрагменты и определяются вектора их смещения на изображении от кадра к кадру. Задача определения векторов смещения решается путем вычисления для группы соседних пикселей (из которых состоят фрагменты) сумм абсолютных значений разностей байтов, кодирующих информацию о пикселях. Для подобных вычисления в наборе команд SSE4 есть команда MPSADBW. Она выполняет вычисление восьми сумм абсолютных значений разностей (SAD) смещенных 4-байтных беззнаковых групп А и В:
Если {А0, А1, ..., А15} и {В0, В1, ..., В15} – указанные в качестве операндов группы байтов, то результатом операции станут восемь сумм {SAD0, SAD1, SAD2, ..., SAD7}, вычисляемых по правилам:
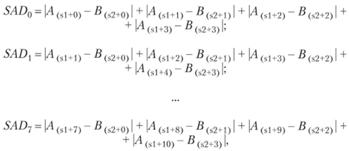
где s1 и s2 – смещения от 0 до 3, определяющие, для каких байтов выполняются вычисления.
Новые команды, введенные в процессорах Nehalem и дополнившие набор SSE (он получил название SSE4.2), в отличие от всех ранее введенных SIMD-команд были ориентированы не на реализацию задач мультимедиа, а на решение более узких и специфических задач, благодаря чему они получили название "ускорители прикладного назначения". Пять новых команд предназначены для обработки текстов и, в частности, XML-файлов. Шестая обеспечивает подсчет 32-разрядных контрольных сумм, которые широко применяются для проверки правильности переданной по каналам связи информации. Седьмая обеспечивает подсчет числа единичных битов.
Важную роль в повышении производительности процессоров Intel Core и Nehalem сыграли буферы ассоциативной трансляции. Эти устройства представляют собой буферы сверхоперативной памяти процессора, которые используются для ускорения трансляции адреса виртуальной памяти (указанного в программе) в адрес физической памяти. Они содержат фиксированный набор записей, в каждой из которых находится соответствие адреса страницы виртуальной памяти адресу физической памяти. Если адрес в буфере отсутствует, процессор вынужден выполнять вычисления для определения физического адреса памяти, что занимает гораздо больше времени.
В процессорах Intel Core использовались два отдельных буфера – для команд и для данных, которые можно рассматривать как буферы первого уровня. В процессорах Nehalem дополнительно введен унифицированный буфер ассоциативной трансляции для данных и команд, который стал буфером второго уровня. Он рассчитан на 512 записей, каждая из которых хранит адрес страницы объемом 4 Кбайт (малая страница). На первом уровне остались два буфера – для команд и для данных. Первый рассчитан на 128 записей адресов малых страниц и семь записей адресов больших страниц, объемом 2 Мбайт/4 Мбайт, второй – на 64 записи адресов малых страниц и 32 записи адресов больших страниц.