Методы формирования и отбора данных
К вопросу идентификации систем с точки зрения методов сбора исходной информации наметилось несколько подходов. Первый предполагает использование специальных тестовых сигналов – методы активной идентификации. Второй связан с наблюдением за системой в рабочем состоянии – пассивная идентификация. Третий – объединяет первые два, компенсируя некоторые их недостатки и сохраняя ряд преимуществ. Четвертый подход основан на эвристиках (предположениях) и имитации (экспертные данные).
В первом случае (методы активной идентификации) режим нормального функционирования исследуемого объекта прерывается, и на объект подаются сигналы (воздействия) специального вида (заранее рассчитанные). Коллектив сотрудников, индивиды, население предупреждаются о проводимых социоэкономических обследованиях, и полученная информация отражает это знание.
Характерными примерами тому являются:
• в социологии – анкетирования, опросы;
• в экономике – всевозможные пилотные проекты по созданию экономических зон, схем развития.
Во втором случае (методы пассивной идентификации) исследователь наблюдает (фиксирует) интересующие его параметры, не вмешиваясь в процесс функционирования социально-экономического объекта. Исследуется нормальный режим его функционирования – рабочий. Это, например, работа со статистикой на предприятии, по архивным данным в различных информационных центрах.
В третьем подходе (активно-пассивный метод) наблюдение за объектом осуществляется пассивно, но для идентификации модели данные отбираются исходя из целей исследования, производственных критериев и используемого математического инструментария, т.е. активно.
Четвертый поход (экспертный метод) основан на эвристической классификации широкого спектра входных сигналов (в том числе предполагается вид и оцениваются параметры шума – ошибок наблюдений). Это позволяет, комбинируя тестовые сигналы, имитировать функционирование объекта не только в рабочей, но и в гипотетической зоне развития.
С целью выявления математических и информационных проблем и условий целесообразности применения указанных подходов проведем их краткий анализ. Его результаты сведены в табл. 7.4.
Таблица 7.4
Сравнение различных методов сбора информации
|
№ п/п |
Наименование свойства, характеризующего способ сбора информации |
А |
П |
А-П |
Э |
|
1 |
Отражение рабочей области данных |
– |
+ |
+ |
+ |
|
2 |
Отражение общей области изменения данных |
+ |
– |
+ |
+ |
|
3 |
Отражение множества гипотетических данных |
– |
– |
– |
+ |
|
4 |
Полнота модели |
– |
+ |
+ |
+ |
|
5 |
Устойчивость вычислительной процедуры расчета параметров модели |
+ |
– |
+ |
+ |
|
6 |
Необходимость останавливать нормальный режим функционирования объекта |
– |
+ |
+ |
+ |
|
7 |
Необходимый объем исходных данных (время наблюдения) |
+ |
– |
– |
+ |
|
8 |
Стратегическая адекватность (макровидение) |
– |
– |
– |
+ |
|
9 |
Тактическая адекватность (микроанализ) |
– |
– |
– |
+ |
Примечание. А – оценка указанного свойства с точки зрения активного подхода; П – преимущества или недостатки пассивного подхода; А-П – свойства активного и пассивного подходов; Э – свойства экспертного, имитационного подхода.
Прокомментируем некоторые утверждения таблицы.
Рабочей областью данных в нашем исследовании считается диапазон изменения исследуемой переменной (цены продуктов на рынке, стоимости ценных бумаг, курсы валют, степень инновационности производства и т.д.), сложившийся в результате естественного функционирования системы. Для различных систем эти диапазоны отличаются друг от друга. Поэтому исследования, проведенные на одном объекте, не могут быть автоматически перенесены на другие.
Общая область изменения данных определяется интервалом значений исследуемой переменной, который в принципе может иметь место, включая и редкие (но иногда критические) наблюдения.
Первая и вторая строки таблицы отражают тот факт, что рабочая область данных адекватнее отражается при пассивном эксперименте (дает необходимые законы распределения наблюдаемых случайных величин), но не дает информации о развитии процесса в редко наблюдаемых (трудновоспроизводимых) ситуациях. Активный эксперимент предусматривает "искусственный" анализ этих ситуаций, но при этом теряется вероятностная характеристика исследуемых процессов. Если перед исследователем стоит задача определить сущность происходящих в системе процессов, то, очевидно, следует использовать методы пассивного эксперимента, если же ставится задача анализа надежности функционирования разработанного алгоритма управления в сложных ситуациях – активного.
Имитационное моделирование в дополнение к сказанному позволяет исследовать модели объектов, структурируя и параметризируя шумы данных. На основе анализа эмпирической информации, высказываний экспертов в модели (имитационной) можно учесть различные виды и параметры законов распределения шумов. Последнее позволяет построить более полную, а значит и адекватную, модель исследуемого процесса, что и отражено п. 4 в табл. 7.4 и на рис. 7.4, в.
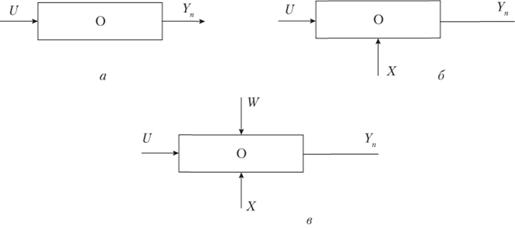
Рис. 7.4. Схемы, иллюстрирующие сущность подходов к сбору данных и идентификации объектов:
а – активный; б – пассивный; в – имитационный подход: U – вектор входных управляемых переменных (инвестиции в процесс, обучение сотрудников, изменение структуры организации и т.д.); X – вектор контролируемых, но не управляемых параметров (рыночные цены, сложившийся спрос и предложение и пр.); W – помехи (шумы); Yn – наблюдаемый выход (объемы продаж, рентабельность, прибыль, себестоимость и пр.)
В случае активного подхода (см. рис. 7.4, а) исследуемая (выходная) величина Ym ставится в зависимости только от управляемых переменных U:
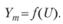 (7.9)
(7.9)
Схема пассивного подхода на рис. 7.4, б определяет зависимость выхода модели Ym и от X, и от U, т.е.
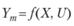 (7.10)
(7.10)
и, наконец, в третьем случае имеем
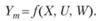 (7.11)
(7.11)
Формула (7.11) описывает сценарный подход к моделированию и управлению.
При идентификации процессов не исключается возможность появления коллинеарных наблюдений. Вычислительные проблемы моделирования, возникающие в связи с вышеуказанными свойствами данных, достаточно подробно изложены в теории некорректных задач и требуют разработки специальных методов. Пункт 5 табл. 7 .4 отражает предпочтительность в данном случае активных методов сбора информации, которые позволяют избежать неустойчивости вычислительных процессов идентификации.
Строки 5 и 6 табл. 7.4 достаточно очевидны и в дополнительных комментариях не нуждаются.
На основании приведенных рассуждений в данной работе предлагается следующее.
1. Осуществлять до начала моделирования по табл. 7.4 оценку соответствия метода сбора данных целям исследования и качеству исходной информации и на этой основе избирать наиболее предпочтительный метод.
2. Объединить процедуры, характерные для названных методов, а именно: наблюдения осуществлять пассивно, но для идентификации использовать не все данные, а только отобранные по специальной процедуре, исключающей коллинеарные наблюдения и коррелированные переменные.
3. Используя методы когнитивного и морфологического анализа, определять характер воздействия на объект управления внешних возмущений (шумов W) и проигрывать варианты функционирования при их различных видах. По результатам имитации определяться наиболее рациональные структуры объектов управления.
При решении практических задач приходится сталкиваться с реально существующей неопределенностью, которая связана с рядом причин: несовершенство средств измерения и контроля, невозможность учета всех влияющих факторов, разброс параметров в пределах заданных допусков и т.д.
Активные методы сбора информации
Математическая теория эксперимента дает в руки исследователя научно обоснованные методы, позволяющие при минимальных затратах времени и средств планировать эксперимент таким образом, чтобы получать максимум требуемой информации об объекте.
В соответствии с задачей данного подраздела в дальнейшем мы будем использовать представление объекта исследования в виде формулы (7.9), соответствующей рис. 7.4, а.
Качество решения задачи поиска математического описания исследуемого объекта в значительной степени зависит от имеющейся в распоряжении у экспериментатора априорной информации о виде уравнения связи и характере возмущающих воздействий.
Наиболее благоприятен для экспериментатора случай, когда имеется априорная информация в виде уравнения связи. Оно может быть известно либо на основании анализа данных экономических свойств объекта, либо на основании предварительных опытов. Для такого уровня априорных сведений разработаны эффективные методы планирования. Для широкого класса функций и некоторых критериев оптимальности планирование сводится к использованию готовых таблиц, описывающих характеристики оптимальных планов. Менее развиты методы планирования эксперимента по выявлению истинной модели при неизвестном виде модели.
При активном планировании эксперимента статистический материал, необходимый для получения оценок неизвестных коэффициентов, набирается по определенной программе исследований. Программа исследований задастся экспериментальным планом, удовлетворяющим некоторому критерию оптимальности.
Непрерывным нормированным планом е называется совокупность величин:
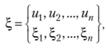 (7.12)
(7.12)
где uiÎX – точки спектра плана; ξi – частоты проведения наблюдений в соответствующих точках спектра; X – пространство планирования.
Здесь иi – значения выходной величины (вектора), приведенные обычно к промежутку [–1; 1] (подробнее см. параграф 6.2). Если переменная U изменяется на участке [а; b], это можно сделать преобразованием
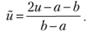 (7.13)
(7.13)
Например, исследуется характер изменения степени мотивации сотрудника от изменения размера его гонорара за выполненную работу. Минимальный (существующий) размер гонорара равен 15 тыс. руб. Планируется исследовать возможность повышения размера оплаты труда до 25 тыс. руб. То есть в нашем случае а = 15, b = 25. Формула (7.13) примет вид
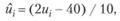
т.е. гонорару в размере и1 = 15 тыс. руб. соответствует 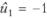 , а значению u2 = 20 тыс. руб. соответствует
, а значению u2 = 20 тыс. руб. соответствует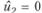 . При гонораре u3, равном по величине 25 тыс. руб., имеем
. При гонораре u3, равном по величине 25 тыс. руб., имеем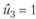
В дальнейшем будем считать, что для и это преобразование уже выполнено. Обратный переход к исходному интервалу изменения переменной по формуле (7.13) очевиден. Для частот удовлетворяется соотношение
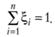
Величина ξi представляет собой долю наблюдений в точке иi при общем числе наблюдений, принятом за единицу. Основное свойство, характеризующее точные планы, состоит в том, что величина
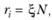 (7.14)
(7.14)
где N – общее число наблюдений.
Приведем некоторые критерии оптимальности планов экспериментов. Эти критерии связаны с видом и параметрами ошибок расчетов. Например, пусть исследуется модель, содержащая только два параметра (см. табл. 7.5, стр. 1). Если по одной оси откладывать ошибку, полученную при расчете первого параметра (у нас а0), а по второй, ей перпендикулярной, – второго (у нас а1), то получим так называемый эллипс рассеивания ошибок расчетов (рис. 7.5).
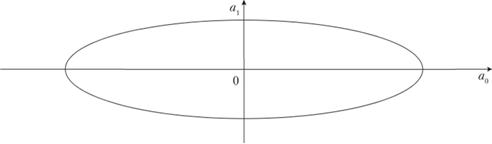
Рис. 7.5. Эллипс рассеивания ошибок наблюдений
При трех параметрах модели ошибка интерпретируется в трехмерном пространстве параметров модели эллипсоидом рассеивания. В общем случае (при п количестве параметров) имеем n-мерный эллипсоид рассеивания. Известны следующие критерии: А-, Е-, D-, G-оптимальности.
Эти критерии допускают наглядную геометрическую интерпретацию. Так, A-оптимальный план эксперимента минимизирует сумму квадратов главных полуосей эллипсоида рассеяния оценок, Е-оптимальный план минимизирует максимальную ось эллипсоида рассеяния, D-оптимальный план минимизирует объем эллипсоида рассеяния оценок, n.е. он минимизирует обобщенную дисперсию оценок неизвестных коэффициентов уравнения регрессии. Критерий G-оптимальности минимизирует дисперсию предсказанных значений регрессионной функции.
На практике наиболее актуальным считается D-оптимальное планирование. Не останавливаясь далее на процедурах построения D-оптимальных планов (эта задача специальных курсов), приведем в качестве примера (табл. 7.5 и рис. 7.6) D-оптимальные планы для некоторых моделей регрессии двух переменных и1 и и2 (т.е. U=(u1; и2)).
Таблица 7.5
Оптимальные планы идентификации объектов заданного вида
|
№ п/п |
Вид уравнения регрессии |
ξ1 |
ξ2 |
ξ3 |
ξ4 |
ξ5 |
ξ6 |
ξ7 |
ξ8 |
ξ9 |
|
1 |
|
0 |
0 |
0 |
1/2 |
0 |
0,5 |
0 |
0 |
0 |
|
2 |
|
0 |
0 |
0 |
1/3 |
1/3 |
1/3 |
0 |
0 |
0 |
|
3 |
|
1/4 |
0 |
1/4 |
0 |
0 |
0 |
1/4 |
0 |
1/4 |
|
4 |
|
1/6 |
1/6 |
1/6 |
0 |
0 |
0 |
1/6 |
1/6 |
1/6 |
|
5 |
|
1/9 |
1/9 |
1/9 |
1/9 |
1/9 |
1/9 |
1/9 |
1/9 |
1/9 |

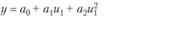
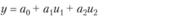
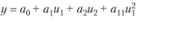
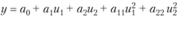
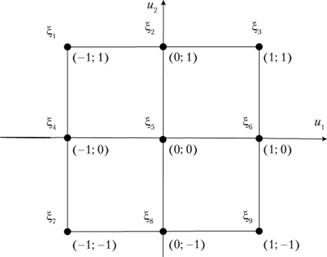
Рис. 7.6. Расположение точек D-оптимальных планов
При наличии множества планов выбирается один из возможных. Иногда множество возможных планов получается, потому что уравнение регрессии имеет специальный вид и одинаковые значения в разных квадрантах пространства планирования.
Рассмотрим пример применения описанной процедуры.
Пример 7.7. Ранее уже формулировалась зависимость уровня нестабильности рынка труда региона J от значений параметров: уровень безработицы v1 и уровень социальной напряженности в системе v2. Будем считать, что априори известен вид искомой зависимости и он соответствует в некоторой ограниченной области виду 3 (а именно, у = а0 + а1и1 + а2и2) табл. 7.5. Входные факторы в данном рассуждении переобозначены с v на и. Модель избрана линейная. Она достаточна для определения тенденций изменения исследуемой переменной – уровня нестабильности рынка труда региона.
Известно (статистические наблюдения в регионе за достаточно длительный период времени), что первая переменная изменяется в пределах от 0,5% (фрикционная безработица) до 2,5% (максимально наблюдаемая), а вторая переменная оценивается экспертами на промежутке от 0 (напряженность отсутствует) до 1 – высший уровень возможной напряженности.
Таблица 7.5 указывает точки, которые следует использовать для идентификации искомой зависимости в соответствии с критерием D-оптимальности. Это точки ξ1, ξ3, ξ7, ξ9, причем используемые с одинаковой частотой, равной 0,25. Согласно формуле (7.13) этим точкам относительных значений соответствуют следующие "натуральные" пары значений переменных v1 и v2: (0,5%; 1), (2,5%; 1), (0,5%; 0) и (2,5%; 0).
Данный подход предполагает выполнения ряда жестких ограничений на условия моделирования (например, знание аналитического вида моделируемой зависимости). Для снятия их используют также теорию самоорганизации вычислительных процессов (см. параграф 6.1).
Рассмотрим пример, иллюстрирующий роль и особенности идентификации сложных экономических объектов с учетом соотношений (7.9)–(7.11).
Пример 7.8. Агропромышленное предприятие на своих полях может посеять пшеницу или рожь в объемах и и2 – компоненты вектора управления U. Критериальным показателем является извлеченная прибыль Ym. Рисунок 7.4 позволит построить, например, модель вида (7.9), а именно
Ym = a2u2 + a2u2, (7.15)
в которой каждый слагаемый компонент описывает прибыль, полученную от соответствующей культуры. Если ввести в модель такую характеристику, как s – спрос на рынке зерна, то модель приобретет вид
Ym = a1(s)u1 + a2(s)u2. (7.16)
В данном случае коэффициенты a1(s) и a2>(s) учитывают изменение цены от спроса на зерно. Если в первом случае мы могли воспользоваться результатами теории активного эксперимента, а именно – провести эксперимент в соответствие со стр. 3 табл. 7.5, то в случае (7.16) такая возможность исключена. Соотношение (7.16) соответствует случаю (7.10), соответственно, следует воспользоваться методами пассивного эксперимента.
Если в дальнейшем при принятии решения (решая оптимизационную задачу) воспользоваться методом алгоритмической надежности, то мы перейдем к варианту (7.11), позволяющему учесть ненаблюдаемые данные, т.е. трудно предсказуемые погодные условия W.