Корреляционный подход и использование статистических мер связи
Проверка гипотез о связях, если речь идет о более чем одной переменной, предполагает одновременные изменения и измерения их безотносительно к указаниям направленности влияний (какая из переменных рассматривается как влияющая на другую). Статистической мерой связи служит при этом выборочный коэффициент ковариации Sjy/. Он подсчитывается как среднее произведений отклонений каждой переменной:
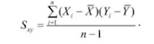
Именно ковариация характеризует связь двух переменных X и У.
Ковариация даст количественную характеристику диаграммы рассеивания, на которой переменные обозначены осями, а отдельные наблюдения, т.е. полученные эмпирические данные, — точками в прямоугольной системе координат. Множество точек образует "облако", по форме которого судят о связи переменных X и У.
Если связь положительна, то более высоким значениям одной переменной (X) чаще соответствуют и более высокие значения другой переменной (У). Этот случай представлен на рис. 15.4. Чем больше по величине коэффициент корреляции, тем более вытянутым выглядит на диаграмме рассеивания это "облако" данных.
Заметим, что ковариация переменной с самой собой — это дисперсия.
При обсуждении трех основных условий причинного вывода применительно к экспериментальным данным речь

Рис. 15.4. Диаграмма рассеивания
идет также о ковариации независимой и зависимой переменных. Однако здесь подразумевается не случайность характера связи между изменениями этих переменных, а не необходимость подсчета коэффициентов ковариации или корреляции. Для количественной оценки экспериментально полученных эффектов обычно используются меры различий, а не меры связей. В корреляционном по способу сбора данных исследовании предпочтение отдается коэффициенту корреляции как более удобному способу количественной оценки величины связи.
Корреляция есть отношение полученной ковариации к максимально возможной:
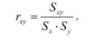
где г — процент от максимально возможной ковариации, которая в данном эмпирическом исследовании достигнута.
Другое определение коэффициента корреляции: корреляция есть ковариация стандартизованных переменных. Обозначение г происходит от понятия регрессии. Ф. Гальтон и К. Пирсон использовали его в исследованиях регрессии физических измерений от одного поколения к другому. Это обозначение закрепилось за коэффициентом корреляции Пирсона, основанном на подсчете произведения моментов, в то время как другие коэффициенты корреляции закрепили за собой другие обозначения (ф — "фи"-коэффициент, т — "тау" Кендэлла и др.). Коэффициент регрессии также имеет разные обозначения, в том числе и г.
В отличие от коэффициентов ковариации и корреляции, которые направлены па установление меры связи между переменными, коэффициент регрессии используется для цели предсказания одной переменной по данным другой. При этом становится важным определиться, значение какой из переменных — X или У- служит для предсказания значений другой. Это отражается в указании последовательности х и у в индексе коэффициента регрессии. Соответственно, коэффициенты регрессии с разным порядком следования переменных в индексации будут иметь разные величины, в то время как для коэффициентов ковариации и корреляции указание последовательности переменных в индексе не имеет значения, так как это будет одна и та же величина связи.
Коэффициент корреляции и стандартизация переменных
Удобство использования коэффициента корреляции связано со следующими моментами:
• он дает меру связи между переменными и в том случае, если они измерены в разных единицах или в разных психологических шкалах;
• он изменяется в определенном диапазоне (от +1 до -1) и предполагает возможность единой нормативной интерпретации;
• разработаны разные статистические подходы к подсчету коэффициента корреляции как в зависимости от используемых шкал (наименований, порядка, интервалов, отношений), так и в пределах одной и той же шкалы.
Так, разные подходы измерения связи использованы при обосновании процедур подсчета коэффициентов "тау" Кендэлла и "роу" Спирмена как разных ранговых коэффициентов корреляции.
Психологам часто приходится сталкиваться с проблемой выявления связей между переменными, измеренными в различных единицах. Так, баллы, полученные в интеллектуальном тесте, обычно предполагающие использование шкалы интервалов, сравниваются с "сырыми" баллами какого-нибудь личностного опросника, по отношению к которым чаще следует предполагать лишь выполнение условий шкалы порядка. Оба названных показателя могут сравниваться, например, со временем решения мыслительной задачи или числом попыток, осуществленных испытуемыми до нахождения ими окончательного решения. Баллы и секунды можно привести к единой шкале, присвоив, например, им ранги и преобразовав тем самым исходные данные в сопоставимые шкалы порядка. Однако в таком случае обычно речь идет о потере информации, поскольку шкала более высокого уровня "низводится" к шкале более низкого уровня, но не наоборот. Возможны исключения: так, по отношению к результатам процедуры прямого вынесения субъектом балльных оценок предлагаются разные способы обработки данных, рассматривающие получаемые психологические переменные то как шкалы порядка, то как шкалы интервалов.
Вариантами решения этой проблемы являются, во-первых, стандартизация переменных и, во-вторых, использование коэффициентов корреляции, заведомо включающих предположения исследователя о типе используемых шкал. Дж. Гласе и Дж. Стэнли |1976| приводят таблицу, демонстрирующую эту ориентацию выбора коэффициента корреляции на тип используемых в исследовании переменных. Остановимся коротко на том, что такое стандартизированные данные, или г-преобразования переменной.
Если переменная представлена множеством случаев (это могут быть испытуемые, задачи и т.д.) со средним X и стандартным отклонением 8, выступающим в качестве меры разброса, то эти же данные можно преобразовать в другое множество со средним 0 и стандартным отклонением, равным 1. Новые значения при этом будут непосредственно выражаться в отклонениях исходных значений от среднего, измеренных в единицах стандартного отклонения. Новые, т.е. преобразованные, значения переменной называются значениями г:
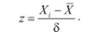
Величина г также является выборочной характеристикой дисперсии.
Z-шкaлa выступает примером линейного преобразования значений переменной. При таком преобразовании сохраняется соотношение между первичными показателями (X) и новыми показателями г. "Относительная величина разницы между стандартными показателями, полученными при таком линейном преобразовании, в точности соответствует относительной величине различия первичных показателей. Все свойства первоначального распределения показателей полностью воспроизводятся в распределении линейных стандартных показателей. По этой причине любые вычисления, которые можно производить с исходными данными, могут также выполняться и с линейными стандартными показателями без какого-либо искажения конечных результатов" [Анастази, 1982, с. 78].
Для ряда психологических переменных используются сложившиеся в той или иной области общепринятые оценки г. Так, для интеллектуальных тестов преобразование исходных "сырых" баллов осуществляется переводом их в шкалу со средним, равным 100, и стандартным отклонением 15 или 16. В нормативных личностных опросниках использование г-преобразования приводит к шкалам степов и станайнов ("стандартная десятка" и "стандартная девятка"). Использование этих шкал позволяет сопоставлять результаты одних и тех же испытуемых в разных тестах. Сопоставимости данных г-преобразование служит и в тех случаях, если в пределах одного и того же методического средства фиксируются содержательно разные показатели. Приведем пример методики измерения стиля "импульсивность — рефлексивность" [Экспериментальная..., 2002].
Экскурс 15.4
Дж. Каган предложил методику, согласно котором в обследованной выборке испытуемых — детей — выделял для интерпретации показатели двух подгрупп. Отметим, что 50% данных не учитывались, поскольку не могли быть подведены под теоретически предполагаемые типы, заданные пересечением двух рядов показателей: испытуемые с медленным поиском и большим количеством ошибок, а также испытуемые с быстрым поиском и маленьким числом ошибок не соответствовали группам, названным рефлексивными и импульсивными. В результате из четырех возможных типов соотношения фиксируемых показателей: времени и точности испытуемого в выборе — только два далее представляли свойства, типичные для импульсивных и рефлексивных испытуемых.
При следовании инструкции "найти как можно быстрее заданное (эталонное) изображение среди других восьми схожих, но чем-нибудь отличающихся от эталонного", испытуемые (дети разного возраста) делали выбор с разными временем поиска и степенью ошибок. Время фиксировал экспериментатор с помощью секундомера, а число ошибок определяли по совокупности неверных выборов в 12 стимульных ситуациях. Те испытуемые, которые давали ответ быстро и делали много ошибок, были отнесены к импульсивным по преобладающему у них когнитивному стилю (это понятие предполагало двухполюсную оценку стиля как способа разрешения субъектом ситуации неопределенности на уровне перцептивных стратегий). Испытуемые, которые давали ответ после длительного поиска и почти не ошибались, назывались рефлексивными. Без квалификации оставались результаты двух подгрупп испытуемых: тех, которые действовали медленно и ошибочно либо быстро и безошибочно.
Авторы других работ, используя эту методику и не желая терять информацию о половине испытуемых — неимпульсивных и нерефлексивных в понимании Дж. Кагана, решили проблему на основе г-преобразований обоих показателей [Overton et al., 1985]. Выразив результат каждого испытуемого в г-показателе времени поиска и z-показателе числа ошибок, они получили возможность характеризовать результаты каждого испытуемого одним числом (общим 2-показателем): Z- Z ||шбки - 2времени. Тем самым результаты всех испытуемых, а не только двух подгрупп могли быть представлены на шкале "импульсивности — рефлексивности". Этот же пример может служить демонстрацией того факта, что не сам по себе фиксируемый показатель выступает в качестве переменной в психологическом исследовании, а способ его оценки. Так, для квалификации когнитивного стиля "импульсивности — рефлексивности" в исходной работе Дж. Кагана использовалась по существу номинативная шкала, в то время как те же показатели в суммарном 2-преобразовании позволяют всех испытуемых выстроить в один ряд и перейти как минимум к шкале порядка. В таком случае испытуемые начинают характеризоваться как более импульсивные или более рефлексивные.
В современных нормативных тестах г-преобразования позволяют выражать отклонения индивидуального результата от средней нормы в единицах, пропорциональных стандартному отклонению распределения. Стандартные показатели могут быть получены как линейными, так и нелинейными преобразованиями первичных показателей.
Нелинейные преобразования позволяют осуществлять сравнение данных, представленных двумя или более переменными, характеризующимися распределениями различной формы. А. Анастази приводит примеры таких показателей, как умственный возраст и процент. Исходя из предположения, что распределение первичных показателей ("сырые" значения переменной) ближе к нормальному, чем к какому-либо иному, применяют нормализованные стандартные показатели. Понятно, что оценка этого допущения применительно к каждой психологической переменной -специальная задача.
Для определения нормализованных стандартных показателей используют специальные таблицы, в которых приводится процент случаев различных отклонений в "сигмах" (а) от среднего значения для кривой нормального распределения. Конкретные способы этих преобразований представлены в учебниках по статистике. Спорным остается мнение, что нормализация первичных показателей в психологических исследованиях приводит переменные к шкалам, подобным шкалам физических величин с равными единицами измерения. Следует подчеркнуть, что представленные в учебнике по статистике сведения не могут служить основаниями решения проблемы спецификации психологической переменной.
Под проблемой спецификации здесь имеется в виду только обоснование психологом, к какому типу шкал следует отнести полученные им первичные показатели. Так, например, если используется показатель времени выполнения какого-то задания испытуемыми, то психологическая переменная "время решения мыслительной задачи" может означать порядок следования испытуемых (по скорости выполнения задания), т.е. удовлетворять лишь порядковой шкале измерения соответствующих индивидуальных различий. Физические величины измерения времени, предполагающие равные единицы (шкалы интервалов), отнюдь не всегда будут соответствовать времени как психологической переменной. Соответственно, какой-нибудь пример из раздела параметрической статистики с использованием показателя времени может не соответствовать типу шкалы в конкретном психологическом исследовании, что повлечет неверный выбор коэффициента корреляции.
Экскурс 15.5
Примером неадекватного понимания первичного показателя может служить попытка прямого прочтения и шкале отношений результатов отметок испытуемыми своего положения в методике Дембо — Рубинштейн. Имеют место случаи буквального подсчета отклонений (измеренного в миллиметрах) индивидуальной самооценки от средней точки на заданной линии. Однако испытуемые оценивали себя согласно качественной шкале, которая не имела миллиметровой градации и количественного критерия отнесения людей к полюсам шкалы. Сравнения себя с другими тем более не имели метрики. Иными словами, испытуемые в такой ситуации дают ответ, осуществляя оценку своих качеств отнюдь не в миллиметрах, а путем использовании неопределенных качественных оценок: "выше среднего", "ближе к умным, чем к глупым" и т.п. С определенной натяжкой здесь можно было бы говорить о шкале порядка, если бы по этим самооценкам можно было установить порядок следования испытуемых друг за другом. Реально возможно лишь отнесение их к группам с размытыми границами — испытуемые с высокой самооценкой, средней, низкой.
Итак, искусственное представление их качественных оценок в количественной шкале способно привести к псевдоэффектам, но отнюдь не изменить тип психологической переменной. И если исследователь хочет задать переменную количественную (как минимум в шкале порядка), то он должен был иначе операционализировать измерение переменной самооценки. На это были направлены исследования, представляемые в экскурсе 15.6.
Экскурс 15.6
В своей обзорной работе А. Фернхем привел данные о том, что связи, установленные в ходе исследований соотношения самооценки интеллекта (СОИ) и психометрического интеллекта — 1(2 достаточно хорошо согласуются друг с другом. Корреляция между СОИ и уровнем интеллекта, измеренного с помощью психодиагностических тестов, в подавляющем большинстве исследований не превышает .30. Но следует отметить, что такого уровня связи с интеллектом обнаруживаются и при использовании личностных переменных.
Так, П. Боркино и А. Либлер вычислили корреляции между СОИ и результатами прохождения немецкими студентами теста интеллекта, включающего 9 частей и направленного на измерение как вербального, так и невербального интеллекта (г = .32 при контроле эффектов пола и возраста). В другом исследовании британские студенты оценивали свой общий интеллект, после чего проходили тест пространственного интеллекта (тест умственных вращений). Мужчины оценили свой интеллект в среднем значимо выше, чем женщины (120 против 116 баллов), при этом получив значимо более высокие результаты в тесте пространственного интеллекта (6.94 против 4.43). При этом корреляция между самооцениваемым и психометрическим 10_ была значимой, хотя не отличалась высоким значением (г = .16). Она оказалась значимой для мужчин (г = .27, п = 53) и незначимой для женщин (г = .09, п = 140).
В исследовании на российской студенческой выборке [Корнилова, Новикова, 2011| также была получена положительная корреляция между прямой СОИ и психометрическим интеллектом (шкалой флюидного интеллекта): г = .24. Это позволяет расширять рамки обобщений связи между 1(2 и СОИ на все студенческие популяции и не ограничивать их рамками национальных исследований.
Для этого были использованы специальные процедуры, посредством которых качественное психологическое образование — СОИ — получало определенную метрику, например, в вынесении суждений.