Коэффициент демпфирования колебаний и границы фильтра
В методе неравномерного сглаживания важную роль играют два коэффициента: коэффициент демпфирования колебаний у и коэффициент η, задающий границы фильтра. Очевидно, что методов их задания можно предложить очень много и в зависимости от используемого метода точность прогнозов будет меняться. В этом параграфе мы обсудим самые простые из них.
Методы задания границ фильтра
Для начала мы предлагаем выделить следующие методы задания η:
1. η можно задать на основе экспертного мнения. Данный вариант не очень хорош, так как обоснован лишь мнением исследователя относительно того, что отсеивать, а к чему адаптироваться. В некоторых случаях, если исследователь хочет включить в интервал какие-то конкретные значения, он может внести правки в значение η, по полагаться целиком и полностью на экспертное мнение ие стоит.
2. η можно задать на основе статистик по остаткам регрессионной модели, построенной по тому же ряду данных.
Здесь возможны различные варианты реализации. Например, можно построить регрессию по всему ряду данных и получить распределение остатков, которое затем потребует изучения. Кроме того, учитывая эволюционность ряда, можно построить регрессию по какой-нибудь первой его части и опять же изучить распределение остатков. Второй вариант, однако, менее предпочтителен из-за слабой формализуемости – в нем остается неясным число наблюдений, требуемое для включения при построении регрессии.
Здесь и далее мы будем основывать вычисления на первоначальной оценке модели МПК по всему ряду данных.
Среди статистик, которые можно использовать для фильтра, выделим следующие:
а) средняя абсолютная ошибка:
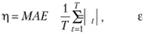 (11.38)
(11.38)
где εt – ошибка на наблюдении t в модели регрессии, оцененной МНК по всему ряду.
Ранее мы уже использовали этот показатель для задания η. Средняя абсолютная ошибка в регрессии обычно меньше СКО ошибок, что приводит к более частой адаптации модели. В некоторых случаях это хорошо, так как позволяет более часто учесть возможные изменения в связях;
б) среднеквадратическое отклонение ошибки:
Установление такой меры фактически означает задание таких интервалов, в которых в случае с нормально распределенной случайной величиной лежало бы не более 68,2% всех ошибок модели. Если распределение несимметрично, процент включенных наблюдений может быть меньше, что будет приводить к более частой адаптации модели.
С использованием СКО можно предложить и другой вариант задания границ;
в) границы на основе t-статистики:
В таком случае исследователь будет определять процент ошибок (считающихся случайными), который надо включить в интервал. Это позволяет более гибко варьировать ширину интервала. Эмпирическое правило здесь заключается в следующем. Если исследователь предполагает, что в ряде данных не происходит сильных изменений в связях, то можно установить более широкий интервал (например, с α = 0,1). Если же есть основания предполагать, что зависимости между результатом и факторами могут меняться более хаотично, то стоит установить более узкий интервал (например, с α = 0,25). Правда, при малых значениях остаточной вероятности полученный интервал будет включать все ошибки и модель не будет адаптироваться. При этом метод (11.40) будет иметь смысл лишь при нормальном распределении оцененных ошибок. Кроме того, на СКО будут оказывать значительное влияние "выбросы" в остатках (в нашем слу
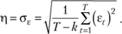 (11.39)
(11.39)
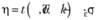 (11.40)
(11.40)
чае это будут отклонения, выходящие за определенные нами рамки, но тем не менее имеющие случайный характер). Если в распределении имеются "выбросы", то в качестве робастной оценки СКО можно использовать медианное абсолютное отклонение – MeAD;
г) медианное абсолютное отклонение:
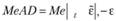 (11-41)
(11-41)
где 
Значение MeAD меньше СКО и обычно ниже МАЕ, поэтому при задании границ с использованием (11.41) модель будет адаптироваться к ошибкам чаще, чем при других статистиках.
Как мы помним из параграфа 5.1, в случае с нормальным распределением остатков выполняется равенство
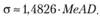 (11.42)
(11.42)
В таком случае, используя (11.42), можно прийти к робастной оценке СКО и использовать ее далее в формуле (11.40).
Впрочем, в случае ненормально распределенных остатков эта оценка может быть заниженной по сравнению с оценкой СКО (11.39);
д) доля от максимальной абсолютной ошибки:
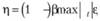 (11.43)
(11.43)
где β – коэффициент фильтрации – устанавливаемая прогнозистом величина, по смыслу близкая к постоянной сглаживания в модели Брауна. В случае, если β = 0, в границы войдут все ошибки и модель адаптироваться не будет. Если β = 1, в границы не войдет ни одна ошибка, а значит, модель будет адаптироваться ко всем ошибкам подряд. Выбор β осуществляется самим исследователем, что усложняет оценку интервала, но при этом данный вариант задания границ никак не завязан на симметричность распределения остатков.
Конечно же, существует множество других статистик, с помощью которых можно задавать границы фильтра. Мы не ставим перед собой задачу описать их все, а лишь рассказываем о самых простых и эффективных. Заметим, что в случае наличия систематических ошибок при оценке исходного ряда данных остатки модели будут излишне завышенными, а значит, и любые статистики, рассчитанные по ним, будут велики. Это, в конце концов, будет приводить к тому, что модель будет адаптироваться значительно реже, чем следовало бы с учетом этих систематических ошибок. Поэтому можно предложить и другой метод задания границ фильтра.
3. η можно подобрать автоматически.
В данном случае в качестве критерия выбора можно использовать, например, минимум RSS, а подбирать границы можно, либо непосредственно изменяя η, либо изменяя β в формуле (11.43). Последнее удобнее, так как легче воспринимается, поэтому далее при автоматическом подборе границ фильтра мы будем обращаться к величине коэффициента фильтрации.
Очевидно, что при подборе нужно ставить ограничение на η, которая должна быть неотрицательна, что достигается за счет β < 1. Учитывая, что при β = 0 адаптации уже не происходит, можно ограничить этот коэффициент пределами от 0 до 1.
При использовании такого метода задания границ фильтра мы, однако, можем столкнуться с проблемой большого числа локальных минимумов, из-за которых будет невозможно найти оптимальное значение коэффициента фильтрации β.
Рассмотрим различные методы задания границ фильтра на примере модели линейного тренда, построенной по данным ряда № 25 из базы рядов М3 – Competition. Последние шесть значений из ряда данных мы возьмем для проверки точности модели и исключим при построении прогнозов.
По этому ряду были построены модели, в которых коэффициент демпфирования колебаний задавайся по формуле (11.16).
В результате расчетов были получены значения, сведенные в табл. 11.5.
Таблица 11.5
Результаты адаптации модели линейного тренда методом неравномерного сглаживания при разных значениях границ фильтра
|
№ |
Формула метода |
Используемая статистика |
Финальное уравнение |
sMAPE по ряду, % |
sMAPE по прогнозу, % |
|
|
1 |
(11.38) |
η = МАЕ = 115,91 |
Yt = 1266.74 + + 248,65t |
3,91 |
9,15 |
|
|
2 |
(11.39) |
η = σ= 155,13 |
Yt = 1247,03 + 247,26/. |
4,07 |
9,93 |
|
|
3 |
(11.40) |
η = σ/(0,5; 12) = 107,89 |
Yt = 1271,25 + 248,90/ |
3,87 |
8,99 |
|
|
4 |
(11.41) |
η = Me AD = 76,43 |
Yt = 1289,86 + 249,82/ |
3,76 |
8,37 |
|
|
5 |
(11.42) |
η = (1 -0,8) 287,01 = 57,40 |
Yt = 1301,73 + 250,33/ |
3,73 |
8,01 |
|
|
6 |
(11.43) |
η подобран = 0 |
Yt = 1371,76 + 249,43/ |
3,22 |
7,05 |
|
По данным таблицы видно, что для этого ряда наиболее точным получается прогноз при использовании как можно более узких границ (что было достигнуто за счет установления границ с β = 1 в шестом методе). Что характерно, за счет того, что в данном случае на периоде ретропрогноза тенденции, наметившиеся ранее, сохранились, видна закономерность: чем ниже sMAPE по ряду, тем меньше sMAPE по прогнозу.
Графически аппроксимация ряда данных разными методами и прогнозы представлены на рис. 11.6. Графики пронумерованы в соответствии с номерами методов в табл. 11.5.
По рисунку видно, что чем у́же оказываются границы, тем сильнее модель адаптируется к последнему скачку, произошедшему в 1988 г. Более того, если попытаться подобрать такое значение β без ограничений, которое гарантировало бы минимум ошибки аппроксимации ряда, это значение оказывается равным 1,23. С точки зрения задания ширины интервала, это нс имеет никакого смысла, так как η оказывается в таком случае отрицательной. Однако вызвано это тем, что мы задавали коэффициент демпфирования колебаний по формуле (11.16). В результате этого η < 0 приводит к более сильной адаптации модели, чего ей в случае с данным рядом как раз и не хватает.
Итак, для каждого ряда данных должна быть выбрана своя оптимальная ширина фильтра. В каких-то случаях эту ширину можно задать одной из статистик, но в общем случае она требует отдельного подбора со стороны прогнозиста.
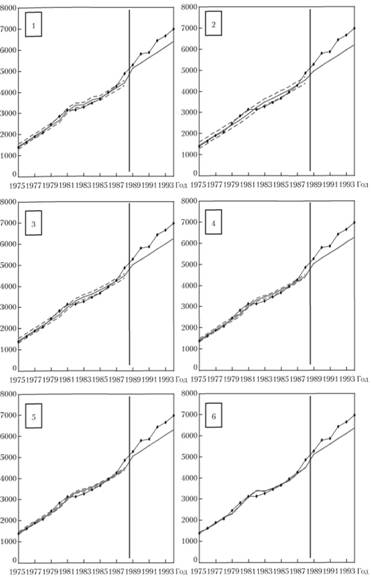
Рис. 11.6. Адаптация модели линейного тренда по ряду № 25 и прогнозы по ней с использованием разных методов задания границ