Классическая декомпозиция
Метод классической декомпозиции (также известный как метод "Census II"[1]) предполагает следующую процедуру разложения ряда на составляющие.
Исходный ряд данных сглаживается простой скользящей средней порядка не меньше лага сезонности для того, чтобы "убрать" ошибки и сезонность и оставить лишь тренд, лежащий в основе ряда. Например, в случае с ежемесячными данными лаг сезонности s будет равен 12 (повторяемость роста и спадов каждые 12 месяцев), а значит, для устранения влияния ошибок и сезонности надо сгладить исходный ряд SMA(12). В данном случае при сглаживании ряда используется четный порядок скользящей средней, поэтому при проведении сглаживания стоит воспользоваться центрированной 5714/4(12), рассчитываемой по формуле (5.4).
Полученный сглаженный ряд считается рядом, соответствующим трендовой компоненте у„ описываемой некоторой функцией f(t). Получив его, мы можем рассчитать соответствующие сезонные компоненты по формулам:
• для аддитивной модели:
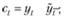 (6.8)
(6.8)
• для мультипликативной модели:
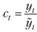 (6.9)
(6.9)
Очевидно, что эти компоненты будут содержать в себе случайные отклонения εt. Чтобы избавиться от них, компоненты усредняют по периодам, в результате чего получается набор "универсальных" сезонных компонент. Например, для получения январской компоненты считается средняя компонента по всем январям:
• для аддитивной модели – средняя арифметическая:
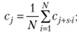 (6.10)
(6.10)
• для мультипликативной – средняя геометрическая:
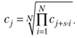 (6.11)
(6.11)
Здесь j характеризует номер сезонной компоненты в периоде (например, первый месяц в году).
Стоит заметить, что результат применения формулы (6.10) для расчета мультипликативной сезонности обычно несильно отличается от результата формулы (6.11), но он более корректен в отношении того, что собой представляет соответствующая компонента.
После получения усредненных сезонных коэффициентов они корректируются (нормализуются), чтобы не вносить помехи в трендовую компоненту:
• в случае с аддитивной моделью – так, чтобы в сумме давать 0 – путем центрирования относительно средней арифметической полученных s сезонных компонент:
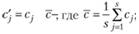 (6.12)
(6.12)
• в случае с мультипликативной – так, чтобы их произведение давало 1 – путем нормирования относительно средней геометрической полученных s сезонных компонент:
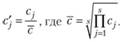 (6.13)
(6.13)
Полученные новые сезонные компоненты могут быть использованы в прогнозировании (так, для прогнозирования значения ряда в январе в случае с аддитивной сезонностью к трендовой составляющей нужно просто прибавить январскую сезонную компоненту).
Кроме того, для целей исследования может быть полезным получение "десезонализированного" ряда данных (ряда, состоящего из трендовой компоненты и случайной ошибки). Для этого:
• в случае с аддитивной сезонностью из фактических значений нужно вычесть полученные по формуле (6.12) сезонные компоненты:
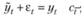 (6.14)
(6.14)
• в случае с мультипликативной сезонностью фактические значения нужно разделить на сезонные компоненты, полученные по формуле (6.13):
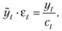 (6.15)
(6.15)
Полученный десезонализированный ряд может быть использован как для построения регрессий, так и для прогнозирования тенденций с помощью более сложных математических методов. Для вычленения остатков из этого ряда его нужно еще раз сгладить простой скользящей средней, после чего из десезонализированного ряда вычесть (или разделить в случае с мультипликативной сезонностью) сглаженный ряд.
Если же исследователя нс удовлетворили полученные оценки трендовой и сезонной компонент, то по десезонализированному ряду можно провести повторное сглаживание с вычленением новых сезонных коэффициентов и уточнением старых по описанной выше методике. Однако обычно значительного улучшения повторная декомпозиция не приносит, поэтому можно остановиться и на одной итерации.
Как видим, метод классической декомпозиции достаточно прост и позволяет получить элементы тренд-сезонной модели с минимальными усилиями. Однако у него есть ряд недостатков:
1. При сглаживании исходного ряда исследователь теряет несколько первых и последних значений. Это становится особенно критичным в ситуациях, когда в распоряжении имеется небольшой временно́й ряд, в котором требуется вычленить сезонность.
2. Вычленить всплески, вызванные праздничными днями, в рамках классической декомпозиции проблематично. Так, сезонная компонента может различаться как раз из-за количества выходных и праздничных дней в месяце. В рамках классической декомпозиции это вызовет искажение в значениях сезонных коэффициентов.
3. Классическая декомпозиция предполагает, что сезонная компонента несильно меняется во времени, что на практике может не выполняться, в результате чего метод становится неприменимым. Так, например, пик продаж в январе одного года может сменить пик продаж в феврале следующего года либо в разные годы может наблюдаться разная амплитуда колебаний вне зависимости от величины трендовой составляющей. В целом из-за эволюции экономических процессов сезонная компонента может достаточно сильно меняться во времени, что никак методом классической декомпозиции не учитывается.
4. В случае наличия "выбросов" (например, резкий скачок продаж в одном из месяцев в одном году, вызванный удачно проведенной маркетинговой кампанией), сезонные компоненты в данном методе будут искажены, что в итоге приведет к неточным прогнозам.
Рассмотрим метод классической декомпозиции на примере ряда данных №1683 из базы рядов М3 (рис. 6.8).
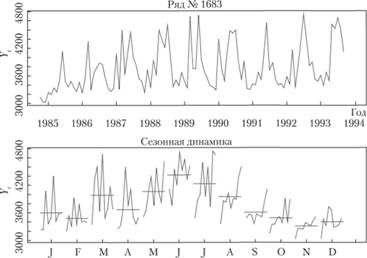
Рис. 6.8. Ряд данных № 1683 из базы рядов М3, отсортированный по времени появления наблюдений и по периодам[2]
Как видим, в динамике показателя наблюдается некоторая тенденция к росту, сам ряд обладает сезонностью, однако эта сезонность изменяется во времени. К графику "Сезонная динамика" мы уже однажды обращались в параграфе 2.3. Он позволяет понять, изменяется ли показатель из года в год в конкретные месяцы. Как видим, однозначного вывода о росте либо снижении показателя в разные месяцы по годам сделать нельзя. Кроме того, определить, изменяется ли амплитуда колебаний с ростом уровня ряда в данном случае затруднительно: единственное, что можно сказать по поводу амплитуды, – это то, что в начале ряда она меньше, чем в конце, однако изменение уровня ряда при этом неочевидно. Тем не менее попробуем рассматривать этот ряд как ряд с мультипликативной сезонной составляющей и осуществим его декомпозицию классическим методом.
Мы имеем дело с месячными данными, поэтому s = 12, значит, для сглаживания ряда данных возьмем SМA(12). В результате получим ряд, показанный в верхней части рис. 6.9.
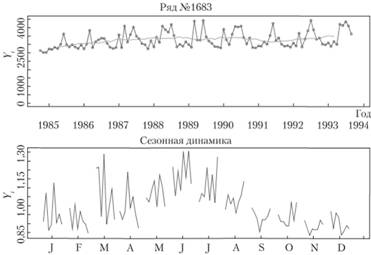
Рис. 6.9. Вверху: ряд данных № 1683 (линии с точками), он же, сглаженный SMA(12) (сплошная линия). Внизу: ряд мультипликативных сезонных коэффициентов
Как видим, такое сглаживание привело к потере значений на концах ряда, но в целом это позволило выявить некоторую эволюционирующую трендовую компоненту.
Рассчитаем сезонные коэффициенты по формуле (6.9). Полученные сезонные коэффициенты изображены на рис. 6.9 (внизу). Как видим, амплитуда их колебаний достаточно высока, а в некоторых сезонных коэффициентах наблюдается тенденция к росту (например, коэффициенты за июнь и июль).
Усредним полученные сезонные коэффициенты, используя формулу (6.11), и нормируем их по формуле (6.13). Получим ряд мультипликативных сезонных коэффициентов, изображенный на рис. 6.10.
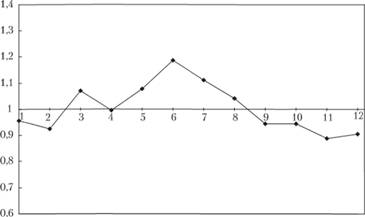
Рис. 6.10. Ряд мультипликативных сезонных коэффициентов, полученный в результате декомпозиции ряда № 1683
На рис. 6.10 по оси абсцисс откладываются номера месяцев в году, а по оси ординат – значения сезонных коэффициентов. Можно заметить, что в среднем в исследуемом ряде данных пики наблюдаются летом (приходятся на июнь – июль), а спады – на конец осени – начало зимы (ноябрь – декабрь).
Из десезонадизированного ряда, рассчитанного по формуле (6.15), мы вычленили ряд ошибок. В результате были получены трендовая, сезонная компонента и ряд ошибок, показанные на рис. 6.11.
Как видим, из-за сглаживания простыми скользящими средними мы потеряли по шесть наблюдений в начале и в конце ряда. Соответственно при прогнозировании такого ряда мы столкнемся со сложностями по подбору подходящей модели тренда, описывающей динамику трендовой компоненты.
Кроме того, можно заметить, что ряд ошибок все еще содержит сезонность (видно, что амплитуда колебаний в начале каждого года выше, чем к концу соответствующих годов), что говорит о том, что убрать сезонность из ряда до конца не удалось. Однако в нашем случае проблема заключается в том, что мы имеем дело с эволюционным рядом данных, в котором изменения претерпевает не только трендовая компонента (что хорошо видно по второму графику на рис. 6.11), но и сезонная (это можно заметить по исходному ряду данных (первый график рис. 6.11)): пики и спады из года в год приходятся на разные месяцы. Все это наводит на мысль о том, что стандартные методы, разработанные для обратимых процессов, не позволяют дать точный прогноз для ряда данных.

Рис. 6.11. Сверху вниз: исходный ряд данных, трендовая компонента, сезонная компонента, остатки