Использование конджойнт-анализа (совместного анализа)
Конджойнт-анализ - эффективный инструмент в разработке товаров. С его помощью исследователь может получить ответы на вопросы о том, какие характеристики товара для потребителей важны, а какие - нет; какие уровни этих характеристик имеют в виду потребители; какой будет маркетинговая доля основных конкурирующих товаров по сравнению с нашими существующими или предполагаемыми к выпуску товарами. Преимущество конджойнт-анализа в том, что респондента просят делать выбор точно так, как он это обычно делает в жизни: путем сопоставления разных характеристик.
Предположим, что вы хотите заказать билеты на самолет. Вы можете выбирать между тесным и просторным креслом; дорогим и дешевым билетом; прямым рейсом (2 ч в пути) и рейсом с посадкой (5 ч в пути). Выбор по каждому параметру по отдельности (при прочих равных условиях) очевиден. Но в жизни так не бывает.
Конджойнт-анализ имеет дело с выбором между продуктами, каждый из которых характеризуется целым набором характеристик. Например, респондента просят сделать выбор из следующих восьми вариантов условий полета (табл. 13.2).
Таблица 13.2. Характеристики предлагаемых вариантов
|
№ варианта |
Сиденье |
Цена, долл. |
Продолжительность полета, ч |
|
1 |
тесное |
225 |
2 |
|
2 |
тесное |
225 |
5 |
|
3 |
тесное |
800 |
2 |
|
4 |
тесное |
800 |
5 |
|
5 |
просторное |
225 |
2 |
|
6 |
просторное |
225 |
5 |
|
7 |
просторное |
800 |
2 |
|
8 |
просторное |
800 |
5 |
Затем, сказав, что выбор наиболее предпочтительного варианта почему-либо невозможен, его просят сделать выбор из оставшихся вариантов и т.д. Если нам известны еще какие-либо, скажем, социально-демографические характеристики каждого респондента, мы можем определить маркетинговые сегменты. Например, путешествующие студенты, предприниматели и т.д. Каждый такой сегмент по-своему чувствителен к разным характеристикам продукта, для каждого сегмента являются допустимыми разные уровни этих характеристик, поэтому каждому из таких сегментов авиакомпания должна адресовать свой вариант продукта.
Применяются два подхода к сбору данных о предпочтениях. Первый подход основан на принципе парных сравнений (pairwise approach) и состоит в следующем. Для каждой из всевозможных пар характеристик товара (в данном случае это, например, - "сиденье-цена" и "сиденье-продолжительность полета") исследователь готовит таблицу, столбцы которой соответствуют возможным значениям одной характеристики, а строки - другой. Респондентов просят пронумеровать клетки каждой из этих таблиц в порядке своих предпочтений. Достоинство этого подхода - относительно небольшое число производимых сравнений, а недостаток - некоторая нереальность требований к респонденту. Например, ему, возможно, трудно оценить приемлемость пятичасового полета в тесном кресле, пока он не узнал стоимость билета.
Второй подход основан на принципе полного упорядочения (full concept approach). При его использовании респондента просят расположить согласно своим предпочтениям карточки, на каждой из которых указаны определенные значения всего набора характеристик товара. Недостаток этого подхода в том, что при большом числе характеристик и их градаций карточек становится так много, что их ранжирование представляется респонденту очень трудным. Тем не менее мы рассмотрим здесь использование именно этого подхода. Этот подход реализован в модуле Categories пакета программ SPSS.
Остановимся более детально на процессе сбора данных в соответствии с этим подходом. Респондентам демонстрируется набор карточек. Каждая рассказывает о каком-либо варианте товара, например товар с таким-то названием, с таким-то вариантом дизайна, с такими-то техническими характеристиками, с такой-то ценой. Иногда респондентов просят разложить карточки в порядке убывания своих предпочтений, иногда - оценить каждую карточку, например, по стобалльной шкале. Полученная информация обрабатывается; для отдельного респондента и по всем опрошенным в целом оценивается роль каждой характеристики в формировании предпочтений. В результате становится возможным оценивать степень привлекательности товаров с любым сочетанием значений рассматриваемых характеристик.
Как уже отмечалось, при реализации этого подхода число карточек может оказаться слишком большим. Например, используются четыре характеристики товара и каждая принимает по три значения (скажем, три варианта названия электрокофемолки, три ее разных дизайна, три варианта цены и три варианта емкости). Для полного понимания "логики" каждого респондента он должен был бы сравнить между собой 81 вариант товара (три в четвертой степени варианта, полученные по принципу "каждый с каждым"). Поэтому обычно делается предположение, что человек оценивает предложенный ему вариант товара, анализируя одну характеристику товара за другой. Следовательно, он предпочитает одно значение характеристики другому вне зависимости от того, в каком сочетании со значениями других характеристик они встретились. Другими словами, предполагается, что эффектами сочетания факторов можно пренебречь. Это, конечно, сильное допущение, однако оно дает большой выигрыш в практической применимости метода. Это предположение позволяет строить экономные, так называемые ортогональные планы, содержащие существенно меньшее число карточек. Так, в приведенном выше примере товара с четырьмя характеристиками вместо 81 варианта нужно протестировать всего девять.
Пример 13.1
Создание ортогонального плана и подготовка карточек для сбора данных
Рассмотрим пример ортогонального плана, построенного для исследования потребительских предпочтений по отношению к кофемолкам (рис. 13.2). Девяти карточкам этого плана соответствуют первые девять строк таблицы, в которых в столбце статуса указано Design.
Для построения ортогонального плана в SPSS используется процедура Generate Orthogonal Design (в меню Data). В ней указывается
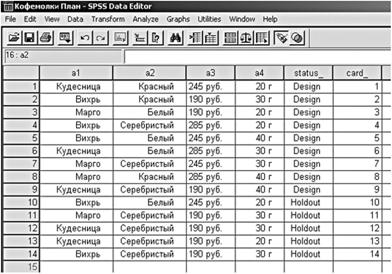
Рис. 13.2. Ортогональный план в задаче исследования по кофемолкам:
а1 - название кофемолки; а2 - ее цвет; а3 - цена; а4 - разовая порция кофе; status - статус; card - номер карточки)
наименование каждой характеристики, а также число и, при желании, наименование каждого из ее возможных значений. Если исследователь считает необходимым демонстрировать респондентам не менее определенного числа карт, программа дает возможность задать минимально допустимое число строк таблицы. При создании ортогонального плана каждой строчке таблицы приписывается статус, который может принимать три значения: Design, Holdout и Simulation. Design приписывается строчкам, по которым рассчитываются параметры модели; Holdout - строчкам, данные которых тоже выносятся на карточки, демонстрируются респондентам наравне с первыми, но используются не для построения, а для проверки пригодности модели. Строки Design и Holdout формирует программа, причем можно потребовать, чтобы они были перемешаны случайным образом. Строки же со статусом Simulation исследователь вводит сам. В ортогональный план они не включаются, респондентам не демонстрируются, но приведенные в них значения характеристик интересуют исследователя и оцениваются по модели, полученной в результате анализа. Например, это могут быть варианты, рассматриваемые в числе возможных для реализации, но не вошедшие в ортогональный план.
В приводимом нами примере наряду с девятью строками, имеющими статус Design, были автоматически сформированы пять строк со статусом Holdout. На приведенном выше рисунке это строки с десятой по четырнадцатую. Строки со статусом Simulation в этом примере не создавались.
Предположим, что приведенные в таблицах характеристики плана экспериментов мы сохранили в автоматически созданном файле "КофемолкиПлан.sav" формата SPSS.
Наряду с таблицей SPSS позволяет автоматически вывести в файл отчета или в другой файл заготовки карточек для демонстрации респондентам. Для этого применяется процедура Display Ortogonal Design также в меню Date. Каждая из полученных с ее помощью карточек содержит развернутое описание варианта, соответствующего одной из строк таблицы. При необходимости респондентам также демонстрируются фотографии или рисунки, дающие представление о вариантах дизайна товара. Приведем пример такой карточки.
|
Карточка товара № 1 Название "Кудесница" Цвет Красный Цена 245 руб. Емкость 20 г |
Эта процедура позволяет получить еще и удобный для исследователя список применяемых карточек. Вместо того чтобы пользоваться программным интерфейсом, можно написать в окне редактора файла команд и выполнить соответствующую команду. Формат этой команды имеет вид:
PLANCARDS [FACTORS=varlist]
[/FORMAT = {LIST}]
{CARD}
{BOTH}
[/TITLE='string']
[/FOOTER='string']
[/OUTFILE=file]
[/PAGINATE],
Все субкоманды этой команды, кроме /OUTFILE = file, доступны через пользовательский интерфейс. Задание же файла удобно: оно позволяет направить вывод в текстовый файл.
Пример 13.2
Сбор данных о предпочтениях респондентов
Следующий шаг работы - формирование файла с информацией о предпочтениях респондентов. Набор карточек с номерами 1-14 предъявляют респондентам. Каждого просят оценить описанные на карточках варианты товара. Полученные результаты записываются в одной из строк файла данных. При этом в SPSS допускается использование любого из следующих трех способов записи предпочтений.
Первый способ - последовательность предпочтений. Респондентов просят разложить карточки в порядке убывания своих предпочтений. В этом случае в каждой строке файла слева направо записываются сначала идентификатор респондента, а затем - номера карточек в порядке убывания предпочтений. Приведем фрагмент такого файла данных (рис. 13.3).
Мы видим, что респондент по фамилии Иванов считает наиболее предпочтительным вариант № 14 (кофемолку "Вихрь" серебристого цвета по цене 190 руб. с размером разовой порции кофе 30 г). Следующий по предпочтительности вариант, с точки зрения Иванова, - № 8.
Если матрица данных имеет такой вид, в команде запуска конджойнт-анализа используется подкоманда "/sequence=prefl to prefl4".
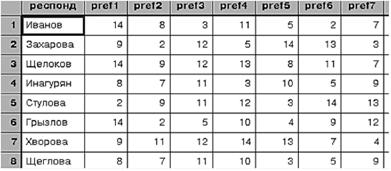
Рис. 13.3. Предпочтения респондентов в задаче по кофемолкам
Второй способ - ранги карточек. Респондентов также просят разложить карточки в порядке убывания своих предпочтений, но теперь в первой, второй и т.д. клетках строчки таблицы записывают ранги - места, которые, с точки зрения соответствующего респондента, занимает первая, вторая и т.д. карточка. Если данные таблицы имеют смысл рангов, то в команде запуска конджойнт-анализа используется подкоманда "/range=prefl to prefl4".
Третий способ - оценки карточек. Респондентов просят приписать каждой карточке оценку по 100-балльной шкале. Чем выше балл, тем больше предпочтение респондента. В этом случае используется подкоманда "/score=prefl to prefl4>>. Предположим, что мы создали файл данных о предпочтениях в формате SPSS первым из перечисленных способов (последовательность предпочтений) и назвали его "КофемолкиОпрос.sav".
Пример 13.3
Запуск процедуры конджойнт-анализа
Доступ к программе через пользовательский интерфейс невозможен. Запуск осуществляется в командном окне с помощью команды:
conjoint plan='с:SРSS_КофемолкиПлан.sav'
/data='с:SРSS_КофемолкиОпрос.sav'
/sequence=prefl to prefl4
/subject=респонд
/factors=al a2 (discrete) a3 (linear less) a4 (linear more)
/utility='с:$Р55_КофемолкиUtility.sav'
/print=analysis.
Подкоманды plan и data содержат информацию об именах и расположении файлов с планом экспериментов и данными опроса. Подкоманда subject указывает на то, что идентификаторы респондентов содержатся в поле "респонд" файла, указанного в подкоманде data.
Подкоманда factors содержит названия характеристик товара. Как указывалось выше, смысл факторов следующий: а1 - название кофемолки, а2 - цвет корпуса, а3 - цена, а4 - размер однократной порции. В скобках после а3 и а4 приведены предположения исследователя о типе зависимости предпочтений от данных характеристик. Linearless означает, что связь линейна, и чем больше цена, тем ниже предпочтение; linearmore означает, что связь линейна, и чем больше размер разовой порции, тем больше предпочтение. После а1 и а2 тип зависимости не указан. В таких случаях по умолчанию предполагается тип зависимости discrete, когда вклад каждого значения в общие предпочтения оценивается отдельно в виде константы.
Наряду с перечисленными типами зависимостей можно задать тип ideal и antiideal. Они применяются, когда исследователь предполагает наличие параболической зависимости. Тип ideal предполагает, что вершина параболы находится вверху, а тип antiideal - что внизу.
Подкоманда utility позволяет указать название файла данных SPSS, в который будут выводиться основные результаты работы процедуры: характеристики индивидуальной для каждого респондента модели и расчетные оценки привлекательности каждого варианта товара для каждого респондента. Приведем фрагмент такого файла (рис. 13.4).
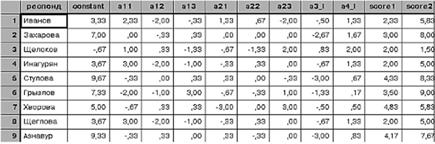
Рис. 13.4. Модели предпочтений и оценки привлекательности вариантов
Мы видим, что полезность (score 1) первого из стоящих в списке вариантов (кофемолки "Кудесница" красного цвета с ценой 245 руб. и размером разовой порции 20 г), с точки зрения респондента Иванова, оценивается величиной 2,33. Эта итоговая полезность складывается из константы (3,33) и следующих характеристик: названия кофемолки (так как "Кудесница" - второй вариант названия, берется а12 = -2,00); цвета (так как красный - второй вариант цвета, берется а22 = 0,67); цены (так как 245 руб. - тоже второй вариант цены, имеем: -0,50 · 2 = -1,00) и размера порции (так как 20 г - первый вариант, имеем: 1,33 · 1 = 1,33). Соответственно имеем: 3,33 - 2,00 + 0,67 - 1,00 + 1,33 = 2,33. Параметры, по которым рассчитываются оценки, чрезвычайно интересны сами по себе. Сравнивая строки таблицы между собой, можно заметить, что были опрошены респонденты трех совершенно разных типов. Респондентам первого типа (Иванову, Инагуряну, Щеглову, Даниловой, Зельдиной и Кукиной) нравится название "Марго", красный цвет и кофемолки с большим размером разовой порции. Цена сравнительно слабо влияет на их выбор. Респонденты второго типа (Захарова, Стулова, Грызлов, Хворова, Азнавур, Шкатов и Харламов), напротив, заботятся в первую очередь о дешевизне кофемолки, а другие признаки их почти не волнуют. Наконец, оставшиеся два респондента (Щелоков и Сандлер) испытывают явную антипатию к названию "Вихрь", предпочитают серебристые кофемолки с большим размером разовой порции. Главная же их особенность состоит в том, что при прочих равных условиях они, скорее, выберут дорогую, а не дешевую кофемолку.
Особенности отдельных респондентов можно изучать не только по представленной выше таблице, но и по файлу отчета. Для управления формой отчета существует подкоманда print. Если в ней, как в приведенном выше примере, указан параметр analysis, то будут напечатаны "досье" на всех респондентов, кроме имеющих статус simulation; если параметр simulation, - то наоборот. Параметр all указывает на необходимость вывода досье и на тех, и на других. Кроме "досье", во всех случаях выдается краткий итоговый отчет о результатах анализа. Если указан параметр summary only, то выводится только краткий отчет, а если параметр попе - отчет не выводится совсем.
Пример 13.4
Примеры "досье" респондентов
Приведем пример "досье" на респондента по фамилии Иванов (рис. 13.5).
Пользуясь этим "досье", можно рассчитать значение функции полезности для кофемолки с любым сочетанием параметров. Например, полезность кофемолки "Вихрь" красного цвета при цене 285 руб. и при размере разовой порции 20 г, с точки зрения респондента Иванова, равна: 3,3333 - 0,3333 + 0,6667 - 1,5000 - 1,3333 = 0,8334. Идеальная для Иванова кофемолка - "Марго" белого цвета при цене 190 руб. и при размере разовой порции 40 г. Ее полезность равна: 3,3333 + 2,3333 + 1,3333 - 0,5000 + 4,0000 = 10,4999. Наихудший, с точки зрения Иванова, вариант - кофемолка "Кудесница" серебристого цвета при цене 285 руб. и при размере разовой порции 20 г. Ее полезность: 3,3333 - 2,0000 - 2,0000 - 1,5000 + 1,3333 = -0,8334.

Рис. 13.5. Первый пример досье респондента
Таким образом, размах колебаний функции полезности для Иванова составляет (10,4999 - (-0,8334)) = 11,3333. При этом вклад названия кофемолки колеблется от -2,0000 до 2,3333, т.е. изменяется самое большее на 4,3333. Эта величина составляет 38,24% от общего размаха полезности. Кроме того, общий размах полезности на 29,41% определяется влиянием цвета кофемолки, на 8,82% - ее цены, на 23,53% - размера разовой порции. Эти данные приведены, как мы видим, в левой части "досье" Иванова и проиллюстрированы столбиками. Таким образом, Иванов обращает внимание прежде всего на название и цвет кофемолки. Другими словами, правильно назвав и окрасив кофемолку, ее можно продать таким покупателям, как Иванов, даже по относительно высокой цене.
Для сравнения приведем "досье" респондента Захаровой (рис. 13.6). Для нее, наоборот, чрезвычайно важны цена и размер разовой порции. Цвет для нее абсолютно не важен, а название - почти неважно.

Рис. 13.6. Второй пример досье респондента
Поясним теперь смысл чисел, приводимых в скобках рядом с оценками частной полезности отдельных параметров кофемолки. Это стандартное отклонение оценок частной полезности. Мы видим, что вкусы Захаровой удалось промоделировать абсолютно точно (стандартное отклонение равно нулю), чего нельзя сказать о вкусах Иванова. Особенно высока стандартная погрешность оценок вклада цены: она близка к 50% от абсолютного размера оценок. Если исследователь считает такую стандартную погрешность модели недопустимой, он может попытаться задать для данного параметра иную, более подходящую, форму зависимости, например Ideal или Antiideal.
Наконец, о смысле трех нижних строк "досье". В первой и второй из них слева приведены оценки "обычного" ("пирсоновского") коэффициента корреляции R и коэффициента корреляции τ Кендалла. Оба коэффициента являются характеристиками качества приближения с помощью модели предпочтений данного респондента. Чем ближе эти коэффициенты к единице, тем лучше модель описывает сделанный им выбор. Справа от каждого коэффициента указана его значимость (significance): вероятность того, что при данной величине оценки коэффициента он в действительности равен нулю.
Мы видим, что в обоих приведенных выше "досье" модель представляется очень точной: оценки Кит практически равны единице, вероятность равенства этих коэффициентов нулю сама является нулевой.
Несколько иную картину демонстрируют последние строки каждого "досье". Если приведенные выше оценки коэффициентов Кит рассчитывались по объектам (вариантам кофемолок), данные о которых учитывались при построении модели (т.е. имели обозначение Design в столбце статуса матрицы исходных данных), то коэффициент τ в последней строке "досье" определен лишь по данным со статусом holdouts, которые были включены в таблицу данных специально для "экзамена" модели. Мы видим, что на наших условных данных экзамен прошел не слишком успешно.
Приведем в заключение известный пример использования конждойнт-анализа в практической работе менеджеров маркетинга при разработке новой пластиковой карточки (American Complete Master Card), приемлемой для наибольшего числа пользователей.
Работа проводилась в три этапа. В ходе первой серии из 8 фокус-групп выяснялась степень заинтересованности пользователей в кредитной карточке, по которой можно было бы еще и звонить по телефону. В ходе второй серии фокус-групп было отобрано 15 свойств: годовая плата за пользование карточкой (4 градации), процент (3 градации), название (7 вариантов) и т.д. Наконец, на третьем этапе были проведены компьютерные интервью с 500 потребителями. Анкета содержала около 50 вопросов. Каждый вопрос предполагал выбор из двух вариантов. Например: "Что для вас важнее: отсутствие годовой платы или гибкий процент?" В результате остановились на следующем варианте: карточка без годовой платы с автоматической ежегодной 10%-й скидкой на большинство звонков.