Информационно-поисковый язык
Применение естественного языка для отображения ПОД и ПОЗ связано со значительными трудностями, обусловленными наличием в языке синонимов, омонимов и тому подобных неоднозначностей использования терминов естественного языка. Поэтому на определенном этапе развития теории и практики создания ИПС вместо естественного языка стали применять искусственные информационно-поисковые языки – ИПЯ.
Существуют различные названия и определения специализированного языка, с помощью которого отражают основное ОГЛАВЛЕНИЕ документов, вводимых в ИПС.
Информационно-поисковый язык (retrieval language) – это специализированный искусственный язык, предназначенный для выражения основного содержания документов или информационных запросов с целью отыскания документов в некотором их множестве [14, с. 259].
Информационно-поисковый язык (ИПЯ) используется для отображения содержания документов информационно-поисковой системы в поисковом образе документа – ПОД и запроса в поисковом образе запроса – ПОЗ, или поисковом предписании.
Такой язык называли вначале информационным языком (ИЯ), предъявляя к нему требование однозначной записи содержания документа, языком индексирования (index language), определяемым как совокупность или систему символов или индексных терминов и правил их использования для выражения предметного содержания документов, документальным языком (language documentaire) и т.п. (подробнее с обзором этих терминов можно ознакомиться в [14]).
В окончательном варианте понятийного аппарата теории информационного поиска утвердился термин информационно-поисковый язык (retrieval language).
Обобщая различные представления об информационно-поисковом языке, можно дать следующее определение:
Информационно-поисковый язык (ИПЯ) является формализованной семантической системой, обеспечивающей передачу (запись) содержания документа в объеме, необходимом для целей поиска.
Документ, записанный на этом языке, может быть, в принципе, и не понят человеком, даже если в записи используются слова естественного языка, поскольку в ИПЯ употребление слов, выражений, отношений между ними стандартизировано определенным образом.
Задачей ИПЯ является перевод содержания документа в поисковое предписание, или поисковый образ документа (при вводе документа в ИПС) и перевод содержания запроса пользователя в поисковый образ запроса (поисковое предписание).
Первые исследователи в качестве составляющих ИПЯ выделяли: алфавит (набор буквенных и цифровых символов), слова, формируемые из алфавита с помощью морфологических правил – морфологии, словарь перевода (в котором каждому слову или осмысленной конструкции естественного языка сопоставлено слово или словосочетание ИПЯ), правила, отражающие взаимоотношения между словами документа, которые в конкретных ИПЯ реализуются, например, с помощью текстуальных или контекстуальных отношений или с помощью специальных правил грамматики – синтаксиса.
Словарь может состоять из ключевых слов (словосочетаний) или дескрипторов. Вначале некоторые авторы (например, Ч. Мидоу [13]) отождествляли эти понятия и понимали под дескриптором все слова, выбранные для включения в словарь.
Однако в дальнейшем термину дескриптор стали придавать более сложный смысл в отличие от ключевых слов, выбираемых предварительно из документов массива, для поиска в котором разрабатывается ИПЯ; под дескриптором понимается некоторый (выбранный разработчиком ИПЯ), обобщающий термин для отображения группы синонимов или слов, которые для целей поиска в конкретной ИПС можно считать синонимами.
Такие слова объединяют в класс условной эквивалентности, обобщаемый соответствующим дескриптором, и если в тексте документа или запроса встречается слово из данного класса, то его заменяют в ПОД или ПОЗ дескриптором.
Таким образом, дескриптор – специальное понятие, введенное и используемое в теории информационного поиска. В современных информационно-поисковых языках под дескриптором понимают имя класса условной эквивалентности [14, 24].
Класс условной эквивалентности формируется из ключевых слов, связанных парадигматическими отношениями.
Парадигматические (базисные) отношения – один из видов семантических отношений, предложенных в теории информационного поиска и применяемых при разработке информационно-поисковых языков.
Парадигматические отношения представляют собой внетекстовые смысловые отношения между лексическими единицами ИПЯ, которые устанавливаются на основании потребностей информационного поиска.
Роль парадигматических отношений сводится к следующему. Принципиальной особенностью естественного языка является тот факт, что в нем одни и те же события могут быть описаны в разных терминах. Тогда в поисковом образе документа – ПОД и поисковом образе запроса – ПОЗ могут быть использованы разные слова с сохранением смысла документа и запроса.
Кроме того, на практике может оказаться необходимым отыскивать документы, в которых речь идет о более частных понятиях, чем в ПОЗ. Не потерять такие документы может помочь введение парадигматических (базисных) взаимоотношений между дескрипторами ИПЯ.
В широком смысле в состав парадигматических отношений включают отношения синонимии (тождество означаемых при различии означающих), омонимии (тождество означающих при различии означаемых), отношения (парадигмы склонения и спряжения), основанные на одинаковости основы при различных окончаниях.
Однако в более узком смысле при разработке ИПЯ иногда предлагается под парадигматическими отношениями понимать "лишь такие отношения между словами (означающими), которые основаны на существовании тех или иных связей между означаемыми" [14, с. 433].
Разные специалисты предлагают различные способы определения парадигматических связей: по сходству предметов, по принадлежности к одному классу, ассоциативные отношения (ассоциации по смежности в пространстве и во времени, по сходству, по контрасту, отношения соподчинения, "вид – род", "причина – следствие", "часть – целое" и т.п.).
При этом допускается произвольное установление отношений в конкретном ИПЯ, с ориентацией на повышение эффективности информационного поиска.
В частности, Э. С. Бернштейн, Д. Г. Лахути и В. С. Чернявский [1] использовали при разработке ИПС "Пусто – непусто" парадигматические отношения, которые определяют как отношения, существующие между словами поискового языка независимо от контекста, называя именно их базисными отношениями, и задавали их списком (включая в тезаурус). Эти отношения увеличивают семантическую силу системы, позволяют формулировать запросы в терминах, отличных от терминов, употребляемых в релевантных документах.
Фиксированные базисные отношения могут быть заданы различными способами: с помощью структуры слов, как в УДК, с помощью системы ссылок, с помощью деревьев дескрипторов и т.п.
Следует иметь в виду, что стремясь улучшить результаты поиска, можно увеличить "шум", т.е. избыточную выдачу.
В различных языках компоненты ИПЯ используются по-разному. Словарь может иметь достаточно сложную структуру, т.е. представлять собой тезаурус, который может включать в себя и алфавит, и слова, и словосочетания, и более сложные конструкции.
Термин тезаурус (от греч. θηδαυροζ, thesauros – сокровищница, богатство, клад, запас и т.п.) в общем случае характеризует "совокупность научных знаний о явлениях и законах внешнего мира и духовной деятельности людей, накопленную всем человеческим обществом" [14, с. 85J. Этот термин был введен в современную литературу по языкознанию и информатике в 1956 г. Кембриджской группой по изучению языков. В то же время термин существовал раньше: в эпоху Возрождения тезаурусами называли энциклопедии. С обзором определений тезауруса и первых тезаурусов можно познакомиться в [14, с. 415–432, 469–505J.
Особую роль в формировании тезауруса играют парадигматические отношения, которые исторически являются элементом логики ИПС.
В математической лингвистике и семиотике термин тезаурус используется в более узком смысле, для характеристики конкретного языка, его многоуровневой структуры.
Для этих целей удобно пользоваться одним из принятых в лингвистике определений тезауруса как "множества смысловыражающих элементов языка с заданными смысловыми отношениями" [2].
Это определение иллюстрирует рис. 6.4 на элементарном примере формирования слов из букв и предложений из слов.
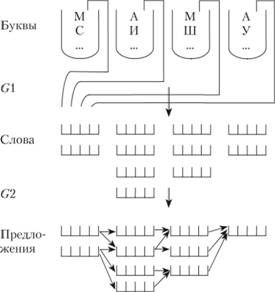
Рис. 6.4. Принципы формирования структуры тезауруса
Разумеется, в реальных тезаурусах уровни носят иные названия: ключевые слова, дескрипторы, абзацы и иные лингвистические и логические элементы.
При этом между уровнями тезауруса могут существовать различные взаимоотношения – от древовидных иерархических до причинно-следственных.
Таким образом, тезаурус позволяет представить структуру языка в виде уровней (страт) множеств слов, предложений, абзацев и т.п., смысловыражающие элементы каждого из которых формируются из смысловыражающих элементов предшествующих структурных уровней.
Правила формирования смысловыражающих элементов второго, третьего и последующих уровней в тезаурус не входят. Они образуют грамматику информационно-поискового языка (Gl, G2 и т.д.). В тезаурусе же определяется только вид и наименование уровня, характер и вид смысловыражающих элементов.
Иногда вместо термина смысловыражающие элементы используется термин синтаксические единицы тезауруса. Однако это менее удачный термин, так как при формировании элементов нового множества смысловыражающих элементов каждого последующего уровня (при образовании слов из букв, фраз и предложений из слов и т.д.) у элементов вновь образованного множества появляется новый смысл, т.е. как бы проявляется закономерность целостности, и это хорошо отражает термин "смысловыражающий элемент".
Понятие тезауруса стало в первую очередь использоваться при разработке информационно-поисковых языков, но в последующем его стали применять и при создании других искусственных языков моделирования, автоматизации проектирования.
Тезаурус позволяет охарактеризовать язык с точки зрения уровней обобщения, ввести правила их использования при индексировании информации. В теории научно-технической информации исследуются различные свойства тезауруса.
Можно говорить о глубине тезауруса того или иного языка, характеризуемой числом уровней, о видах уровней обобщения и, пользуясь этими понятиями, сравнивать языки, выбирать более подходящий для рассматриваемой задачи или, охарактеризовав структуру языка, организовать процесс его разработки.
В практике создания информационно-поисковых систем наиболее известен словарь-тезаурус "Тезаурус ASTIA" [3].
В системе SMART [4] содержится два вида тезаурусов:
• тезаурус с иерархической структурой понятий. Дает возможность для любого номера понятия найти их "родителя", "сыновей", "братьев" и множество возможных перекрестных ссылок;
• тезаурус в виде словаря синонимов.
Используется для замены значащих слов номерами понятий, каждое из которых представляет класс основ слов, близких по смыслу.
Простейшими тезаурусами являются словари дескрипторов при толковании дескриптора как имени класса условной эквивалентности, формируемого на основе парадигматических отношений.
Тезаурусы разрабатываются и в отечественных отраслевых системах научно-технической информации (например, в АСНТИ-геология [5]). Термин тезаурус иногда используется в более широком смысле.
Например, Ю. И. Шемакин тезаурусом называет сложную систему организации в автоматизированных системах управления и обработки информации в разных ее видах (научно-технической, управленческой, представляемой в документальной и фактографической форме) [6].
Морфологию и синтаксис удобно объединять единым термином – грамматика. Тогда говорят, что ИПЯ состоит из тезауруса и грамматики, а затем рассматривают смысловыражающие элементы (синтаксические единицы) тезауруса и правила грамматики.
Под грамматикой (которую иногда называют синтактикой, синтаксисом, что сужает понятие грамматики, исключая из нее морфологию) понимаются правила, с помощью которых формируются смысловыражающие элементы языка. Пользуясь этими правилами, можно "порождать" (формировать) грамматически (синтаксически) правильные конструкции или распознавать их грамматическую правильность.
Простейшими правилами грамматики являются синтагматические (текстуальные) отношения. Синтагмой называются правила типа {ai, rк, bj} где ai Î A; bj Î В – взаимодействующие множества (подклассы) исходных понятий языка; rk e R – множество отношений, которые могут иметь произвольный вид.
При создании и использовании искусственных языков для информационно-логических систем применяют понятия математической лингвистики и формальных языков, в частности понятия порождающей и распознающей грамматики.
Под порождающей грамматикой понимается совокупность правил, с помощью которых обеспечивается возможность формирования (порождения) из первичных элементов (словаря) синтаксически правильных конструкций.
Под распознающей грамматикой – правила, с помощью которых обеспечивается возможность распознавания синтаксической правильности предложений, фраз или других фрагментов языка [7].
На базе математической лингвистики развивается теория формальных грамматик Н. Хомского. Классы формальных грамматик Н. Хомского [8] считаются основой теории формальных языков.
Формальный язык определяется как множество (конечное или бесконечное) предложений (или "цепочек"), каждое из которых имеет конечную длину и построено с помощью некоторых операций (правил) из конечного множества элементов (символов), составляющих алфавит языка.
Формальную грамматику определяют в виде четверки множеств:
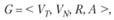 (6.9)
(6.9)
где VT – множество основных, или терминальных, символов; VN – множество вспомогательных, или нетерминальных, символов; R – множество правил вывода, или продукций, которые могут иметь вид:
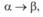 (6.10)
(6.10)
где 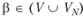 , т.е. β – цепочка конечной длины из терминальных и нетерминальных символов множеств VT и VN;
, т.е. β – цепочка конечной длины из терминальных и нетерминальных символов множеств VT и VN; 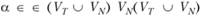 , т.е. а является цепочкой из терминальных и нетерминальных символов, содержащей, по крайней мере, один нетерминальный символ из VN; А – множество аксиом (в грамматиках комбинаторного типа, к которым относятся грамматики Н. Хомского, А состоит из одного начального символа S, причем
, т.е. а является цепочкой из терминальных и нетерминальных символов, содержащей, по крайней мере, один нетерминальный символ из VN; А – множество аксиом (в грамматиках комбинаторного типа, к которым относятся грамматики Н. Хомского, А состоит из одного начального символа S, причем  ).
).
Учитывая, что в литературе по формальным грамматикам, как правило, не стремятся к содержательной интерпретации получаемых выводов, а рассматривают лишь формальную сторону процессов порождения и распознавания принадлежности цепочек к соответствующему классу грамматик, приведем содержательный пример порождающей грамматики.
Предположим, дано:
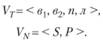
Порождающая грамматика Распознающая грамматика
 (6.11)
(6.11)
Применяя правила R левой части (6.11) в приведенной последовательности, получим
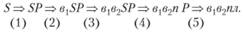
Это – формальная сторона процесса порождения. Для того чтобы получить интерпретируемое выражение, нужно расшифровать терминальные символы, включенные в VN, где б, – ВСЕ; в2 – ВОЗРАСТЫ; п – ПОКОРНЫ; л – ЛЮБВИ.
Тогда полученное предложение:
"в1в2пл" – "ВСЕ ВОЗРАСТЫ ПОКОРНЫ ЛЮБВИ".
Если изменить последовательность применения правил, то будут получаться другие предложения. Например, если применить правила в последовательности (1) Þ (3) Þ (2) Þ (4) Þ (5), то получится "ВОЗРАСТЫ ВСЕ ПОКОРНЫ ЛЮБВИ". Если применить не все правила: например, (1) Þ (2) Þ (4) Þ (5), то получим "ВСЕ ПОКОРНЫ ЛЮБВИ".
Если же попытаться получить предложение, как у А. С. Пушкина – "Любви все возрасты покорны", то, как бы мы не меняли последовательность правил, получить эту фразу не удается. Нужно изменить первое правило: вместо S → SP включить в R правило S → PS.
Из примера видно, что вид порождаемых цепочек (предложений) зависит от вида правил (исчисления) и от последовательности их применения (алгоритма).
С помощью приведенного примера легко также продемонстрировать тесную связь понятия "грамматически правильный" с языком (грамматикой).
Распознающая грамматика для рассматриваемого примера будет содержать как бы "перевернутые" правила – правая часть (6.11), которые должны применяться в обратной последовательности. Пример представления анализа правильности предложения с помощью правил распознающей грамматики приведен на рис. 6.5.
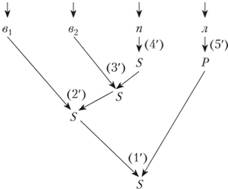
Рис. 6.5. Пример анализа предложения с помощью правил распознающей грамматики
При распознавании правильности предложения если не оговаривать, что предложение (цепочка) грамматически правильно с точки зрения правил данного формального языка, то можно, пользуясь формальной грамматикой в первоначальном виде, получить вывод, что приведенная фраза
Пушкина грамматически неправильна с точки зрения правил грамматики (6.11).
Действительно, с точки зрения правил грамматики для построения делового текста, которым соответствуют правила (6.11), другие поэтические строки часто получали бы формальную оценку "грамматически неправильно". И, напротив, если построить грамматику на основе анализа пушкинского стиля, то в деловом тексте получились бы предложения типа "Я решение свое принял правильное" (подобно фразе "Я памятник себе воздвиг нерукотворный").
Понятие формальной грамматики используют при создании языка моделирования соответствующего литературного или музыкального произведения – пародий, подражательств или, как иногда принято говорить, произведений соответствующего стиля или класса.
Например, известны работы Р. X. Зарипова [9] по моделированию музыкальных произведений в стиле, или в классе популярных советских песен по моделированию процесса сочинения стихотворных произведений и т.п.
Подобным же образом можно моделировать порождение деловых писем или других документов, имеющих, как правило, не только формализованный стиль, но и формальную структуру. Аналогично можно создавать языки моделирования структур, языки автоматизации проектирования сложных устройств и систем определенного вида (класса).
Основу таких работ составляют идеи, которые можно пояснить с помощью классов грамматик, впервые предложенных Н. Хомским [10].
Разделение грамматик на классы определяется видом правил вывода R. В зависимости от них можно выделить четыре основных, наиболее часто рассматриваемых класса грамматик (табл. 6.4). В полной теории формальных грамматик с правилами типа подстановки есть и промежуточные классы.
В теории формальных грамматик показано, что имеет место следующее соотношение:
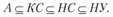 (6.12)
(6.12)
Иногда доказывают, что имеет место строгое вхождение:
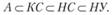 (6.12, а)
(6.12, а)
Таблица 6.4
Основные классы грамматик Н. Хомского
|
Класс |
Характеристика |
|
1 -й класс. Неукорачивающие (НУ-грамматики) |
На правила вывода накладывается только одно требование, чтобы в левой его части было всегда меньше символов, чем в правой, т.е. чтобы правила были неукорачивающими, нс уменьшали число символов в выводимых цепочках. Иногда эти грамматики называют грамматиками типа ноль (нулевого типа) или алгоритмическими |
|
2-й класс. Контекстные, контекстно-связанные |
На правила вывода, помимо требований неукорачиваемости, накладывается ограничение, чтобы на каждом шаге изменялся только один символ в контексте, т.е. чтобы Z1 BZ2 → Z1 WZ2, где В – один нетерминальный символ, W – непустая цепочка символов, т.е. W'. Иногда применяют термин – грамматика непосредственных составляющих (НС-грамматика) |
|
З-й класс. Контекстно-свободная (КС-грамматика) или бесконтекстная |
Кроме неукорачиваемости требуется, чтобы правила имели вид В → β, т.е. а всегда состоит из одного вспомогательного символа |
|
4-й класс. Автоматные (А-грамматики) |
Па правила вывода накладывается по сравнению с третьим классом еще одно ограничение, требующее чтобы в правилах вывода нетерминальный символ всегда стоял справа или слева, т.е. с одной стороны. Если нетерминальный символ стоит слева, т.е. правила имеют вид А≠аВ или А → а, где (А, В) Î VN, a e VT, автоматная грамматика является праволинейной; если нетерминальный символ стоит справа, – то автоматную грамматику называют леволинейной |
При исследовании разных классов формальных грамматик получены результаты, которые позволяют сделать вывод, что по мере уменьшения числа ограничений, накладываемых на правила вывода, т.е. по мере продвижения в (6.12) слева направо, в языке увеличивается возможность отображения смысла, т.е. возможность выражения с помощью формальных правил семантических особенностей отображаемого текста, проблемной ситуации. Говорят, что формальная система становится более богатой. Однако при этом в языке растет число алгоритмически неразрешимых проблем, т.е. увеличивается число положений, истинность или ложность которых не может быть доказана в рамках формальной системы языка.
Здесь мы сталкиваемся фактически с проблемой Гёделя [11], которая в теории формальных языков обсуждается обычно в терминах этой теории. А именно: вводится понятие "операция определена (или не определена) на множестве языков данного класса"; и считают, что операция определена на множестве языков данного класса, если после применения ее к языкам, входящим в эго множество, получается язык, принадлежащий множеству языков этого класса.
Например, если Я1 Ì КС и Я2 Ì КС, и если (Я1 и Я2) Ì КС, то операция объединения и определена на классе KС-языков.
Характеризуя с помощью введенного понятия классы языков, отмечают, что в последовательности (6.12) по мере продвижения слева направо увеличивается число операций, которые нс определены на множестве языков данного класса.
Здесь правда, следует оговорить, что дело обстоит не так прямолинейно. Точнее было бы сказать, что для большого числа операций нет доказательств, что они определены на классах НС-языков и НУ-языков, т.е. эти доказательства становятся сложнее или вообще (в силу теоремы Гёделя) нереализуемы средствами теории формальных грамматик.
Приведенное упрощенное представление проблемы помогает обратить внимание тех, кто будет заниматься разработкой языков программирования или программных систем, языков моделирования, автоматизации проектирования, на необходимость учета следующей закономерности: чем большими смысловыражающими возможностями обладает знаковая система, тем в большей мере растет в ней число алгоритмически неразрешимых проблем (т.е. тем менее доказательны в ней формальные процедуры).
При выходе в класс произвольных грамматик, в котором не выполняется даже условие неукорачиваемости, доказать допустимость тех или иных формальных преобразований средствами математической лингвистики практически невозможно, и поэтому в поисках новых средств исследователи обратились к семиотическим представлениям. Здесь можно провести как бы формальную границу между лингвистикой и семиотикой.
При создании ИПЯ с тезаурусом и грамматикой важную роль играют понятия семантики и прагматики.
Под семантикой понимается ОГЛАВЛЕНИЕ значения, смысл формируемых или распознаваемых конструкций языка; под прагматикой – полезность для данной цели, задачи.
В естественном языке различить понятия, с помощью которых характеризуются термины "семантика" и "прагматика", трудно; обычно пояснить различие можно лишь при парном сопоставлении терминов [27]:
<семантика>:: = <ОГЛАВЛЕНИЕ>|<смысл>|<значение>;
<прагматика>:: = <смысл>|<значение>|<полезность>.
Поэтому принято рассматривать эти понятия на примерах. Поясним различие между семантически и прагматически правильными конструкциями языка на следующих легко запоминающихся примерах.
Традиционно для пояснения синтаксической правильности и семантической бессмыслицы используется предложенный Л. В. Щербой пример "Глокая куздратщето борзданула бокра и курды чет бокренка" (в котором просто нет ни одного слова естественного языка, имеющего смысл). Но примеры можно найти и в естественной речи.
Предложение "Муха лукаво всплеснула зубами" синтаксически правильное, но не имеет смысла в естественном русском языке в обиходном, широком употреблении, т.е. является с точки зрения пользователей русским языком семантически неправильным (исключим пока гипотетическую ситуацию сказки, в которой муха может быть наделена указанными свойствами).
Другое предложение "Маленькая девочка собирает цветы на лугу" – синтаксически и семантически правильное. Однако для директора завода (если это луг, а нс заводской газон, и – учтем личный фактор, – если эта девочка не его дочь) это предложение не несет никакой информации, т.е. прагматически (с точки зрения целей руководителя) является неправильным. Другое дело, если "Иванов (который в данный момент должен находиться на рабочем месте) собирает цветы на лугу". Тогда это предложение было бы и прагматически правильным.
Возвратимся теперь к примеру с мухой. Приведенное предложение семантически неправильное, может в гипотетической ситуации сказки оказаться прагматически правильным, что важно иметь в виду при применении лингвистических представлений.
Более глубоко пояснить эту проблему помогают виды и меры информации А. А. Денисова (см. гл. 1). Например, полученное сообщение "Завод выполнил план. Завод выполнил план. Завод выполнил план" техническое устройство, воспринимающее его, может оценить с точностью до предложения, если оно настроено так, что читает текст до точки и воспринимает его как предложение (тогда ΔA = 1 предложение, и J=A/ΔA = 3 предл./1 предл. = 3); с точностью до слов, если оно воспринимает текст до пробела как слово (тогда А = 1 слово и] = А / ΔA = 6 слов / 1 слово = 6); а возможно и до букв (тогда J = 51), а человек, получив этот текст (или устройство, способное устранять дублирование) может сказать, что получил одну информацию, т.е. H=J/п = = 3 предл. / 3 =1, если объем понятия – определяется с точностью до числа предложений, т.е. п = 3 и, если в его представлении предложение семантически правильное, т.е. для кого-то может иметь смысл:
C=J•H= 1•1 = 1.
Но человек может сказать, что получил 0 информации, поскольку она для него не имеет смысла. В этом случае он применит для оценки Я вероятностную прагматическую меру (1.17, в), т.е. оценит степень влияния на его цели р' = 0, и тогда H = log (1 – р') = 0.
Пользуясь этими правилами, можно лучше отразить смысл документа или запроса в ПОД и ПОЗ, повышая релевантность поиска.