Иерархическая кластеризация
Рассмотрим объединительные (агломеративные) методы иерархической кластеризации.
Напомним, что на первом шаге работы алгоритмов объединительной кластеризации каждый объект считается отдельным кластером. Каждый последующий шаг алгоритма состоит в слиянии каких-то определенных кластеров. В конечном итоге все объекты образуют один кластер. При этом в файл с результатами работы алгоритма выдается информация, анализ которой позволяет выбрать наиболее рациональное с определенной точки зрения.
Как уже отмечалось, недостатком агломеративных методов является их вычислительная трудоемкость: расчетное время растет пропорционально кубу числа объектов в матрице данных. Кроме того, эти методы весьма требовательны к оперативной памяти компьютера. Поэтому по нашему опыту в программном комплексе SPSS, по крайней мере до 18-й версии включительно (PASW Statistics), такая кластеризация выполняется не более чем на 12 тыс. объектов (строках матрицы данных).
Разнообразие методов данного типа связано с двумя обстоятельствами: во-первых, с тем, какая мера считается расстоянием между точками пространства и, во-вторых, по каким правилам определяются расстояния между кластерами, когда последние включают в себя два или более объектов. Меры, на основе которых определяются расстояния между точками пространства, мы рассмотрим несколько позднее. А сейчас обсудим правила определения расстояния между кластерами.
Правила определения расстояния между кластерами. На первом шаге, когда каждый объект представляет собой отдельный кластер, расстояния между этими объектами-кластерами определяются выбранной метрикой - мерой расстояния или мерой сходства объектов в пространстве переменных. Затем из определенных соображений, о которых будет сказано несколько ниже, какие-то объекты объединяются в один кластер и появляются кластеры, в которых два и более объекта. Возникает проблема: что считать расстоянием между такими кластерами? Здесь имеются различные возможности. В программном комплексе SPSS предлагаются следующие три группы методов.
1. Методы индивидуальных связей:
а) межгрупповых связей;
б) внутригрупповых связей;
в) ближайшего соседа;
г) дальнего соседа.
2. Методы связей между центрами кластеров:
а) центроидная кластеризация;
б) медианная кластеризация.
3. Дисперсионный метод - метод Варда.
При использовании методов первой группы после включения объекта в кластер по-прежнему учитываются расстояния от этого объекта до других. При использовании методов второй группы после включения объекта в кластер рассчитываются и впоследствии учитываются в расчетах расстояния от некоторой центральной в том или ином смысле точки, характеризующей кластер в целом. Метод из третьей группы базируется на иной логике: объединения не тех кластеров, которые в том или ином смысле максимально близки, а тех, слияние которых дает наименьший прирост внутрикластерной дисперсии, т.е. в наименьшей степени приводит к "разрыхлению" кластеров, выделенных на предыдущих шагах процедуры.
Рассмотрим эти группы методов подробнее.
Методы индивидуальных связей
Метод межгрупповых связей. В этом методе расстояние между кластерами рассчитывается путем усреднения всевозможных расстояний от объекта одного кластера до объекта другого. По умолчанию в SPSS предлагается использовать именно этот метод.
Метод внутригрупповых связей. В этом методе расстояние между кластерами вычисляется как среднее расстояние между всеми возможными парами объектов, принадлежащих обоим кластерам, в том числе объектов, расположенных внутри одного и того же кластера.
Метод ближайшего соседа. Расстоянием между двумя кластерами считается расстояние между двумя самыми близкими точками из разных кластеров. Этот метод хорошо работает, если кластеры в реальности имеют форму удлиненных "цепочек".
Метод дальнего соседа. Расстоянием между двумя кластерами считается расстояние между двумя самыми далекими точками из разных кластеров. Этот метод хорошо работает, когда в реальности кластеры имеют вид сильно удаленных друг от друга скоплений точек. Если же кластеры имеют удлиненную форму или их естественный тип является "цепочечным", этот метод непригоден.
Методы связей между центрами кластеров
Центроидная кластеризация. На первом шаге каждый объект образует отдельный кластер, координаты этого объекта являются центром (центроидом) кластера. При слиянии двух кластеров центроид нового кластера рассчитывается как взвешенное по числу объектов в каждом кластере среднее значение центроидов исходных кластеров. Таким образом, большее значение придается крупным кластерам. В итоге на каждом шаге алгоритма центроид каждого кластера располагается в точке со средними по всем объектам кластера значениями координат.
Медианная кластеризация. При слиянии двух кластеров центроид нового кластера рассчитывается путем усреднения координат центроидов двух сливаемых кластеров. Число объектов, входящих в эти кластеры, не учитывается, т.е. мелкие и крупные кластеры считаются одинаково важными и учитываются с одинаковыми весами.
Дисперсионный метод
Метод Варда (Ward). Метод минимизирует среднюю сумму квадратов евклидовых расстояний от объектов кластеров до своих кластерных центров. На каждом шаге объединяют такие два кластера, которые дают наименьший прирост внутрикластерной дисперсии нового кластера.
Практика использования методов агломеративной кластеризации показывает, что наилучшие результаты дают метод средней связи и метод Варда.
Меры расстояния между точками пространства. Когда мы говорим, что методы иерархической кластеризации объединяют в один кластер близкие между собой объекты, надо договориться, что значит близко и далеко, по каким правилам, с помощью какой меры определяются расстояния между точками в пространстве переменных. Речь при этом может идти как о точках, в которых расположены отдельные объекты, так и о точках, в которых расположены центры кластеров.
Меры, т.е. конкретные формулы, используемые для измерения расстояний, зависят от типа шкал, в которых измерены переменные.
Интервальные (метрические) шкалы
Евклидово расстояние между двумя точками х и у - это кратчайшее расстояние между ними. Если пространство двумерно или трехмерно, то эта мера геометрически является длиной отрезка прямой, соединяющей данные точки. В случае n переменных евклидово расстояние вычисляется по формуле
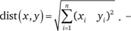 (13.3)
(13.3)
Квадрат евклидова расстояния рассчитывается по формуле
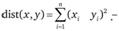 (13.4)
(13.4)
По сравнению с евклидовым расстоянием эта мера придает более серьезное значение большим расстояниям. Если применяется центроидный, медианный метод или метод Варда, обычно рекомендуется использовать именно эту меру. Однако по опыту авторов, если все переменные бинарные, которые используются как интервальные, более качественные результаты кластеризации дает евклидово расстояние.
Блок. Расстояние городских кварталов (манхэттенское расстояние, дистанция таксиста).
Это расстояние является просто суммой абсолютных значений разностей координат. Манхэттенское расстояние вычисляется по формуле
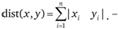 (13.5)
(13.5)
Если евклидово расстояние - это кратчайшее расстояние между двумя точками, в двумерном случае - расстояние по гипотенузе прямоугольного треугольника, то блок - это сумма длин катетов этого треугольника. Эту меру называют также манхэттэнским расстоянием. В шутку говорят, что это путь, который должен преодолеть манхэттенский таксист, чтобы проехать от одного дома к другому по улицам, пересекающимся под прямым углом.
В большинстве случаев эта мера расстояния приводит к таким же результатам кластеризации, как и обычное расстояние Евклида. Однако отметим, что так как здесь не предусматривается возведение расстояний в квадрат, влияние отдельных больших разностей (выбросов) уменьшается.
Расстояние Чебышева. Расстоянием между двумя точками определяется как максимальный модуль разностей их координат в заданном пространстве переменных:
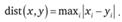 (13.6)
(13.6)
Это расстояние может оказаться полезным, когда хотят считать два объекта очень удаленными друг от друга, если они сильно различаются хотя бы по какой-то одной координате.
Расстояние Минковского. Это расстояние рассчитывается по формуле
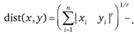 (13.7)
(13.7)
Как легко заметить, расстояние Минковского является обобщением евклидового расстояния: если r = 2, они совпадают. Варьируя параметр r, можно в различной степени придавать значение удаленным точкам по сравнению с относительно близкими. Заметим, что в данной мере связи как за взвешивание разностей по отдельным координатам, так и за взвешивание расстояний между объектами "отвечает" один и тот же параметр r.
Настроенная мера связи или степенное расстояние вычисляется по формуле
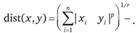 (13.8)
(13.8)
Эта мера является обобщением меры Минковского: в ней используется не один, а два параметра: для взвешивания разностей по отдельным координатам - параметр р, а для взвешивания расстояний между объектами - параметр r. Если исследователь хочет увеличить или уменьшить вес, относящийся к размерностям, по которым соответствующие объекты сильно отличаются, это может быть достигнуто с использованием степенного расстояния. Естественно, что если оба параметра - r и р равны двум, то это расстояние совпадает с расстоянием Евклида. Рекомендуется выбирать значения обоих параметров в пределах от 1 до 4.
Номинальные шкалы
Для проведения иерархического кластерного анализа при использования шкал такого типа данные должны быть подготовлены по-другому, нежели было описано выше. Ранее каждая строка таблицы данных относилась к определенному респонденту. Теперь же строки таблицы данных должны соответствовать категориям одной номинальной переменной, а столбцы - другой. Категории первой переменной рассматриваются как объекты, которые надо разбить на кластеры, а категории второй - как переменные. В клетках же таблицы содержатся частоты - число респондентов, в ответах которых обнаружено соответствующее сочетание категорий. Таким образом, кластерный анализ такого типа выполняется не на исходной матрице данных, а на таблице сопряженности.
Соответственно для сравнения между собой двух объектов - строк таблицы сопряженности (х и у), т.е. для определения расстояния между ними, используют частотные меры, о которых шла речь в подразделе 12.5: квадратный корень из критерия χ2 и фи-коэффициент Фишера.
Мера χ2. Для вычисления меры используется формула Пирсона, в которой рассчитывается сумма квадратов стандартизованных остатков по всем клеткам таблицы сопряженности, принадлежащим двум определенным объектам-строкам этой таблицы х и у. В качестве расстояния между категориями используется квадратный корень из значения критерия χ2:
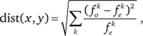 (13.9)
(13.9)
где k - номер клетки в таблице сопряженности; 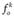 - наблюдаемая частота в k-й клетке (т.е. например, число респондентов, выбравших такое сочетание ответов);
- наблюдаемая частота в k-й клетке (т.е. например, число респондентов, выбравших такое сочетание ответов); 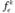 - ожидаемая частота в k-й клетке.
- ожидаемая частота в k-й клетке.
Клетки с более высокими стандартизованными остатками вносят более весомый вклад в численное значение критерия χ2, а следовательно, и в расстояние между двумя объектами-строками таблицы х и у. Таким образом, чем больше больших стандартизованных остатков, тем больше расстояние между строками.
Мера φ2. Здесь при расчете расстояния между двумя строками таблицы сопряженности производится нормализация меры φ2; перед извлечением квадратного корня она делится на общую сумму наблюдаемых частот, т.е. общее число респондентов в двух строках таблицы сопряженности:
 (13.10)
(13.10)
В отличие от меры χ2, которая может принимать сколь угодно большие положительные значения, мера φ2 меняется от нуля до единицы. Заметим, что хотя, вообще говоря, этот критерий рекомендован для таблиц сопряженности из двух строк и двух столбцов, в иерархической кластеризации осмысленные результаты получаются и при большем числе столбцов таблицы сопряженности.
Бинарные переменные
Иерархический кластерный анализ можно использовать для кластеризации не только объектов (например, респондентов), но и переменных. Хотя, как уже говорилось, такое применение SPSS в книге не рассматривается, отметим, что для случая кластеризации бинарных переменных в программном комплексе предусмотрено 27 мер связи, которыми можно пользоваться по усмотрению исследователя.
Рекомендации по обеспечению надежности и достоверности результатов иерархического кластерного анализа. Иерархические методы кластерного анализа (как, впрочем, и метод K-means) предназначены для выявления неоднородностей, существующих в пространстве переменных. Однако такие неоднородности вовсе не обязаны в реальности существовать, тогда как любой метод кластерного анализа дает результат всегда. Если реальных неоднородностей в экспериментальном материале нет, метод обнаружит маленькие случайные неравномерности и на основе этих флуктуаций разделит объекты на кластеры.
Чтобы понять, удалось ли выявить реально существующую структуру объектов или метод закончил работать, потому что иного выхода у него не было, рекомендуется следовать четырем рекомендациям.
1. Выполнить кластерный анализ с использованием различных способов измерения расстояний. Сравнить, насколько совпадают полученные результаты.
2. Выполнить кластерный анализ с использованием различных методов объединения кластеров. Сравнить результаты.
3. Если позволяет размер матрицы данных, разбить набор классифицируемых объектов на две равные части случайным образом. Выполнить кластерный анализ отдельно для каждой половины. Сравнить кластерные центроиды двух подвыборок.
4. Очень важный критерий качества кластеризации - содержательная интерпретация результатов.
Пример 13.10
Использование иерархической кластеризации
Напомним, что назначение этого алгоритма состоит в пошаговом объединении объектов (строк матрицы данных) в кластеры, используя некоторую меру сходства (расстояние) между объектами. Объединение кластеров может осуществляться, например, одним из семи методов, которые рассматривались нами выше. На первом шаге каждый объект помещается в отдельный кластер. Рассмотрим, как работает этот алгоритм, сначала на примере опроса студентов о степени их согласия с каждым из 22 высказываний (см. раздел 13.3). Кластеризацию проведем в пространстве только семи параметров, сильно коррелирующих со "своими" факторами:
q4 - "Люблю развлечься в хорошей компании";
q14 - "Я взрослый человек и должен помогать семье материально";
q16 - "Стараюсь, чтобы у меня все было самое лучшее";
q17 - "Совершенно не выношу очередей, лучше переплатить";
q20 - "Я всегда могу легко объясниться по-английски";
q23 - "Я не выношу, когда мной пытаются командовать";
q24 - "Люблю находить решение, ориентироваться в неопределенной ситуации".
На рис. 13.16 показано, как в англоязычной версии SPSS 14 и в русскоязычной версии SPSS 17 назначать переменные, в пространстве которых будет осуществляться кластеризация. Следует обратить внимание, что в поле "Метить значения (Label Cases by)" введена текстовая переменная Фамилия, чтобы на диаграмме было понятно, какие именно студенты входят в один и тот же кластер.
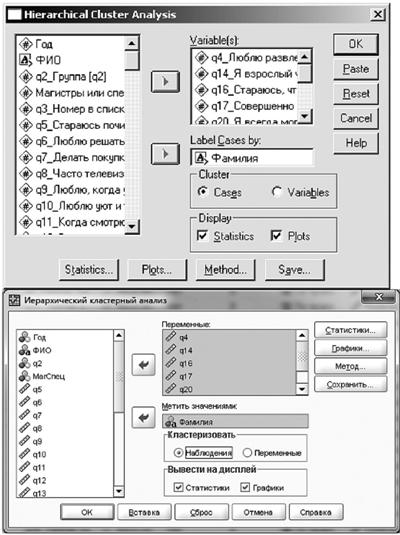
Рис. 13.16. Выбор переменных, в пространстве которых будет осуществляться кластеризация
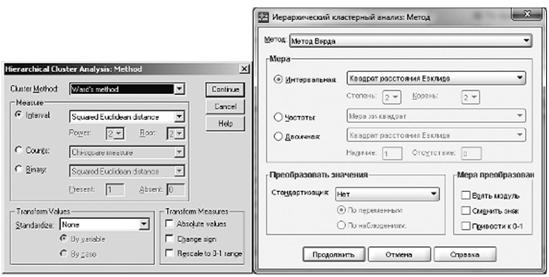
Рис. 13.17. Выбор метода кластеризации и меры связи
Рис. 13.18. Заказ выдачи таблицы последовательности агломерации объектов в кластеры
Рисунок 13.17 иллюстрирует выбор метода кластеризации и меры связи. (Выбран метод Варда, а в качестве меры связи - квадрат евклидового расстояния.) На рис. 13.18 показано, как заказать выдачу таблицы с последовательностью слияния и информацией о динамике прироста показателя качества кластеризации (в данном случае, напомним, это внутрикластерная дисперсия).
На рис. 13.19 показано, как заказать выдачу в качестве результата кластеризации специальной древовидной диаграммы (Dendrogram), которая очень удобна при относительно небольшом (как в данном случае) числе объектов, подвергающихся кластеризации. При большом числе объектов этот график становится необозримым.
Рис. 13.19. Заказ выдачи древовидной диаграммы (Dendrogram)
После общей статистической сводки объектов выводится таблица "Порядок агломерации (Agglomeration schedule)" (табл. 13.6). По этой таблице в принципе можно проследить, в какой очередности осуществлялось слияние кластеров в процессе работы алгоритма.
Таблица 13.6. Таблица "Порядок агломерации (Agglomeration schedule)"
|
Stage |
Cluster Combined |
Coefficients |
Stage Cluster First |
Next Stage |
||
|
Appears |
||||||
|
Cluster 1 |
Cluster 2 |
Cluster 1 |
Cluster 2 |
|||
|
1 |
17 |
19 |
,500 |
0 |
0 |
3 |
|
2 |
12 |
18 |
2,000 |
0 |
0 |
13 |
|
3 |
1 |
17 |
3,500 |
0 |
1 |
14 |
|
4 |
14 |
15 |
5,000 |
0 |
0 |
7 |
|
5 |
3 |
11 |
6,500 |
0 |
0 |
11 |
|
6 |
5 |
7 |
8,000 |
0 |
0 |
11 |
|
7 |
4 |
14 |
9,833 |
0 |
4 |
12 |
|
8 |
9 |
10 |
12,833 |
0 |
0 |
9 |
|
9 |
6 |
9 |
15,833 |
0 |
8 |
13 |
|
10 |
2 |
16 |
19,333 |
0 |
0 |
15 |
|
11 |
3 |
5 |
23,333 |
5 |
6 |
14 |
|
12 |
4 |
8 |
27,750 |
7 |
0 |
16 |
|
13 |
6 |
12 |
33,050 |
9 |
2 |
17 |
|
14 |
1 |
3 |
39,764 |
3 |
11 |
17 |
|
15 |
2 |
20 |
48,931 |
10 |
0 |
18 |
|
16 |
4 |
13 |
59,581 |
12 |
0 |
19 |
|
17 |
1 |
6 |
75,650 |
14 |
13 |
18 |
|
18 |
1 |
2 |
94,667 |
17 |
15 |
19 |
|
19 |
1 |
4 |
124,850 |
18 |
16 |
0 |
Однако, по нашему опыту, наиболее информативен в этой таблице столбец "Коэффициенты (Coefficients)", так как с его помощью можно определить рациональное для данного случая число кластеров. Этот столбец содержит данные о значении критерия кластеризации на каждом шаге алгоритма.
На рис. 13.20 представлен график прироста критерия оптимизации. Напомним, что в нашем случае речь идет о методе Варда и квадрате евклидового расстояния в пространстве исходных (не стандартизованных) переменных. Поэтому коэффициент агломерации на каждом шаге процедуры имеет смысл суммарной внутрикластерной дисперсии полученного разбиения.
Мы видим, что на первом шаге алгоритма (когда каждый объект образует отдельный кластер) внутрикластерная дисперсия, естественно, равна нулю. Затем она постепенно начинает расти, так как алгоритм "склеивает" в один кластер все более удаленные друг от друга объекты.
Оптимальное число кластеров разбиения определяется следующим образом: находится момент, с которого начинается скачкообразное увеличение его значений. Очевидно, что это момент, начиная с которого алгоритм вынужден "соединять несоединимое", собирая в один кластер сильно удаленные относительно компактные множества объектов.
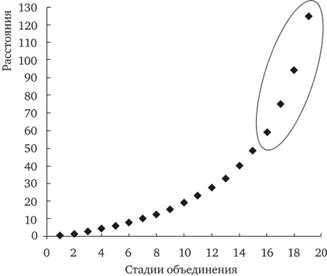
Рис. 13.20. График прироста критерия оптимизации
В данном случае, судя по графику, скачкообразное изменение коэффициентов начинается с 16-й стадии работы алгоритма. Поэтому оптимальным для нашего примера числом кластеров является четыре (20 - 16 = 4).
При значительном размере выборки графики типа представленного на рис. 13.20 можно не строить для всех стадий процесса агломерации. Достаточно проанализировать последние нескольких десятков точек, чтобы понять, с какой из них начинается скачкообразное изменение критерия. Наряду с этим графиком может быть полезен график разностей значений критерия оптимизации между соседними точками.
В SPSS предусмотрены и иные инструменты, призванные облегчить исследователю выбор оптимального числа кластеров. Так, по умолчанию кроме таблицы с результатами формирования кластеров, на основании которой мы определим их рациональное число, SPSS выводит также специальную так называемую сосульчатую гистограмму Icicle, также помогающую, по замыслу создателей программы, определить рациональное количество кластеров; вывод диаграмм осуществляется кнопкой Plots (см. рис. 13.19). Однако анализ этой диаграммы весьма трудоемок даже при сравнительно небольшом файле данных. Поэтому мы не будем приводить в книге эту диаграмму.
Кроме сосульчатой диаграммы, в окне Plots можно выбрать более удобную, на наш взгляд, древовидную диаграмму (Dendrogram) (рис. 13.21). Она представляет собой горизонтальные столбики, наглядно демонстрирующие расстояния между объектами и группами объектов (кластерами). При небольшом (до 50-100) числе респондентов данная диаграмма действительно помогает принять рациональное решение относительно числа кластеров. Однако практически во всех примерах реальных маркетинговых исследований выборки значительно больше, что делает дендрограмму в значительной мере бесполезной.
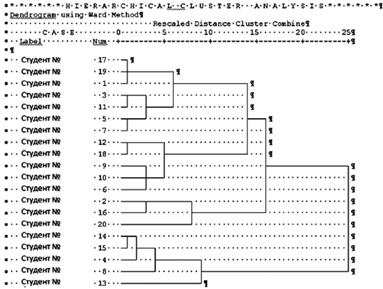
Рис. 13.21. Древовидная диаграмма (Dendrogram) (Фамилии студентов, ответы которых на вопросы анкеты использовались для кластеризации, скрыты.)
Древовидная диаграмма позволяет сделать следующие наблюдения. Три точки, соответствующие студентам № 17, 19 и 1, расположены в пространстве переменных очень близко друг от друга. Близко расположены пара точек № 3 и 11, а также пара точек № 5 и 7. Между этими парами точек расстояние несколько больше. Еще больше расстояние между первыми тремя точками и следующими четырьмя. В то же время эти семь точек в совокупности очень значительно удалены от пяти точек № 12; 18; 9; 10 и 6. Поскольку скачок расстояний тут очень значительный, имеет смысл условно рассечь древовидную диаграмму примерно на уровне 10 пунктов расположенной сверху условной шкалы. Тогда, как легко заметить, будет образовано четыре кластера:
o первый: № 17, 19, 1, 3, 11, 5 и 7;
o второй: № 12, 18, 9, 10 и 6;
o третий: № 2, 16 и 20;
o четвертый: № 14, 15, 4, 8 и 13.
Приведенный пример делает очевидной трудоемкость анализа древовидного графика при "промышленных" размерах выборки порядка многих тысяч респондентов. Поэтому наш опыт свидетельствует в пользу выбора оптимального числа кластеров на основании графиков, построенных в MS Excel, по данным столбца "Коэффициенты" таблицы "Порядок агломерации (Agglomeration schedule)" .
После того как оптимальное число кластеров выбрано, процедура иерархической кластеризации запускается еще раз, но предварительно на вкладке "Сохранение (Save)" заказывается вывод в файл исходных данных результатов кластеризации на признанное рациональным число кластеров (рис. 13.22).

Рис. 13.22. Заказ сохранения столбца с номерами кластеров в файл с исходными данными
После этого в файл будет добавлен столбец, содержащий для каждого респондента номер кластера, к которому он отнесен.
В заключение напомним, что эти методы в отличие от метода К-средних, во-первых, по крайней мере до 18-версии SPSS включительно, не позволяют обрабатывать матрицы исходных данных из более чем 12 тыс. строк и, во-вторых, не позволяют учитывать весовые коэффициенты. Первая проблема обычно преодолевается путем случайного отбора строк, подлежащих анализу. По опыту же авторов, если организовать случайный отбор строк с вероятностью, прямо пропорциональной весовым коэффициентам, то преодолевается и вторая проблема.