Вычислительные процедуры
Рассмотрим специфику вычислений, осуществляемых вручную.
Подобно тому, как существуют специальные формулы, облегчающие проведение однофакторного дисперсионного анализа с независимыми данными, разработаны специальные вычислительные процедуры, позволяющие проводить "ручные" вычисления, обеспечивающие однофакторный дисперсионный анализ с повторным измерением. Эти процедуры представлены в табл. 4.4.
Таблица 4.4
Вычислительные процедуры однофакторного дисперсионного анализа с повторными измерениями
|
Элементы формул |
|||||
|
|
|
|
|
||
|
Формулы |
|||||
|
Источник дисперсии |
Принятое обозначение |
Суммарный квадрат |
Степени свободы |
||
|
Между испытуемыми |
between_people |
(4)-(1) |
п – 1 |
||
|
Внутри испытуемых |
within_people |
(2)-(4) |
п(k – 1) |
||
|
Экспериментальное воздействие |
treatment |
(3)-(1) |
k – 1 |
||
|
Остаточный |
residual |
(2)-(3)-(4) + (1) |
(n – 1)(k – 1) |
||
|
Общий |
total |
(2)-(1) |
kп – 1 |
||
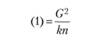
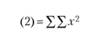
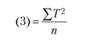
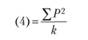
Структура табл. 4.4 аналогична структуре табл. 3.4, где были представлены вычислительные процедуры однофакторного дисперсионного анализа для несвязных выборок. Правда, в отличие от табл. 3.4 данная таблица не воспроизводит структуры однофакторного экспериментального плана с повторным измерением, так как эта информация уже была представлена в табл. 4.1. Верхняя часть табл. 4.4 содержит общие элементы формул, необходимые для дальнейших вычислений суммарных квадратов. Формулы для "ручных" вычислений представлены в нижней части таблицы.
Как видно, по сути вычислений корреляционная модель однофакторного дисперсионного анализа не сильно отличается от модели, рассмотренной нами ранее. Здесь добавляется лишь вычисление сумм по строкам, характеризующих результаты каждого испытуемого в отдельности. Эти суммы необходимы в дальнейшем для оценки среднего квадрата, который дает нам оценку дисперсии, возникающей вследствие интраиндивидуальных вариаций данных и экспериментальной ошибки (остаточной дисперсии). Заметим, что, хотя в табл. 4.4 указаны пять источников дисперсии, при обработке данных практически необходимы лишь два значения: 1) дисперсия, вызванная экспериментальным воздействием, и 2) остаточная дисперсия. На основе этих значений строится /'-отношение, статистическая значимость которого оценивается либо с помощью стандартных таблиц F-распределения (см. приложение 4), либо вычисляется с помощью соответствующих функций MS Excel или его аналогов. При использовании статистических программ величина статистической значимости рассчитывается самой программой обработки. Остальные значения суммарных квадратов и соответствующее им число степеней свободы необходимы лишь для уточнения правильности проведенных вычислений. Напомним, что общий суммарный квадрат SStotal должен складывается из суммарного квадрата между испытуемыми SSbetween_peopk и суммарного квадрата внутри испытуемых SSwithin_people. В свою очередь, суммарный квадрат внутри испытуемых должен складываться из суммарного квадрата, определяющего вариацию данных, вызванную экспериментальным воздействием SStreatment, и остаточного суммарного квадрата SSresidual Эти соотношения также должны непременно выполняться и для степеней свободы, но не для средних квадратов.
Рассмотрим специфику вычислений, осуществляемых с помощью компьютера. Компьютерная реализация однофакторного дисперсионного анализа с повторными измерениями несколько отличается от тех процедур обработки данных, которые мы рассмотрели выше, исследуя возможности использования статистических пакетов обработки данных применительно к методу дисперсионного анализа. Основное и принципиально важное отличие состоит здесь в подготовке данных, а также в том, как структура экспериментального плана будет представлена в самом статистическом модуле.
Если в стандартном варианте дисперсионного анализа требуется создать по меньшей мере две переменные, соответствующие заданным экспериментальным планом независимой и зависимой переменным, то при обработке данных методом дисперсионного анализа с повторными измерениями переменными в самом пакете становятся значения, или уровни, независимой переменной. Таким образом, нужно для начала создать столько переменных, сколько имелось в эксперименте уровней независимой переменной. Каждая из этих переменных может быть обозначена именем соответствующего ей уровня независимой переменной. Так, если мы провели эксперимент, направленный на выяснение того, как испытуемый будет припоминать разные части списка бессмысленных слогов, и реализовали трехуровневый план с повторными измерениями, то необходимо будет создать три переменные, назвав их, к примеру, "начало", "середина" и "конец".
После этого мы переходим в режим работы с данными и вводим их. При этом, как и всегда, каждая строка нашей таблицы будет соответствовать результатам лишь одного испытуемого. Если, например, у нас имеются данные, относящиеся к десяти испытуемым, мы получим таблицу данных размером три столбца на 10 строк.
Если для обработки данных использовать русскую версию статистического пакета IBM SPSS Statistics, то в меню "Анализ" необходимо выбрать раздел "Общие линейные модели", а в нем – "ОЛМ повторные измерения...". Откроется окно определения внутригруппового фактора. В нем необходимо указать имя независимой переменной, например "Позиция", число ее уровней, в нашем случае их три. После этого нажимаем кнопку "Добавить". Независимая переменная будет добавлена в список, при этом в скобках будет указано число ее уровней. Убедившись, что все сделано правильно, нажимаем кнопку "Задать".
Теперь мы попадаем в новое окно, похожее на то, что нам уже знакомо по гл. 3. В этом окне в поле слева перечислены все наши переменные, которые в данном случае соответствуют уровням независимой переменной. Справа от этого поля расположено поле "Внутригрупповые переменные", которые содержат пустые фреймы, соответствующие всем заданным нами уровням независимой переменной, определенной на предыдущем шаге. Вверху мы должны увидеть имя этой переменной. Добавляем в это поле из поля слева переменные, которые соответствуют заданным уровням независимой переменной.
Дальнейшие действия не отличаются от тех, что нам уже известны на примере межгруппового анализа данных, описанного в гл. 3. Можно также отдельно определить априорные контрасты, задать вывод необходимых нам данных по описательной статистике, определить нужные нам графики.
Более детально описанные процедуры обсуждаются в практической части гл. 4.