Автоматизация моделей экспоненциального сглаживания
Мы разобрали только основные модели экспоненциального сглаживания и уже успели убедиться в том, что выбор модели значительно влияет на точность прогноза. Очевидно, что для каждого временно́го ряда оптимальной (в смысле точности аппроксимации) будет какая-то своя модель из всех рассмотренных нами. Конечно, это не гарантирует, что при этом мы получим наиболее точный прогноз, но, к сожалению, ни на какие критерии мы больше опираться не можем.
В связи с этим в 2002 г. был предложен алгоритм, позволяющий автоматически выбрать наилучшую из всех ETS-моделей и дать по ней прогноз[1]. Основная идея алгоритма – перепробовать всевозможные модели из табл. 7.6 и 7.7 для аппроксимации ряда данных, после чего выбрать наилучшую из них.
В связи с тем что выбрать между аддитивной и мультипликативной моделями, используя стандартные критерии (такие, как дисперсия ошибки) невозможно, Р. Хайндман и др. предложили использовать критерий максимума функции правдоподобия, который после ряда преобразований сводится к нахождению минимума следующей функции:
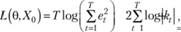 (7.74)
(7.74)
здесь θ – вектор постоянных сглаживания (там же – коэффициент демпфирования), используемых в оцениваемой модели; Х0 – вектор стартовых значений (уровня ряда, угла наклона, сезонных коэффициентов); kt – коэффициент, который равен единице, если рассматривается аддитивная модель и 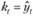 в случае, если рассматривается мультипликативная модель.
в случае, если рассматривается мультипликативная модель.
В (7.74) et представляет собой ошибку на наблюдении t и так же различается в зависимости от используемой формы учета ошибок. Рассчитывается она по формуле 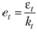 , где
, где 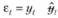 .
.
Чтобы запустить подбор параметров с помощью (7.74), нужно задать определенные стартовые значения постоянных сглаживания и параметров Х0. В данном подходе предлагается следовать следующей схеме:
1) α = β = γ = 0,5;
2) φ = 0,9;
3) для сезонных рядов проводится классическая сезонная декомпозиция с нормализацией полученных сезонных коэффициентов;
4) для оценки трендовой компоненты строится модель линейного тренда но первым 10 наблюдениям (в случае с сезонными рядами – по десезонализированному ряду); l0 принимается равным константе, b0 – равным углу наклона;
5) в случае с мультипликативной трендовой компонентой b0 = 1 + а1 / a0, где а1 – угол наклона построенного линейного тренда; а0 – константа.
Получив такие стартовые оценки для выбранной модели, осуществляется подбор оптимальных Θ и Х0, после чего по полученной модели рассчитывается выбранный информационный критерий, например AIC:
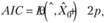 (7.75)
(7.75)
где р – число элементов векторов  и Х0.
и Х0.
Так как информационные критерии были уже рассмотрены в параграфе 2.5, на обсуждении их свойств мы здесь останавливаться не будем.
Рассчитав параметры модели и АIC, переходят к следующей модели. В результате таких расчетов по всем 30 моделям экспоненциального сглаживания выбирается та, у которой AIC наименьший. На основе этой модели даются точечный и интервальный прогнозы.
В программе "R" весь описанный выше алгоритм уже реализован в функции "ets". Рассмотрим, какую модель предложит нам такой подход для рядов № 41 и № 1683.
Для ряда № 41 было построено две модели:
1. С интервалами, выводимыми из свойств ETS, ETS(M,Md,N):
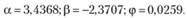
2. С классическими интервалами, ETS(M,A,N):
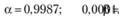
В очередной раз мы обращаем внимание на то, что постоянные сглаживания, полученные в результате подбора параметров в более широких интервалах, не имеют удобной интерпретации "средних величин", а скорее характеризуют степень адаптации различных компонент ETS.
На рис. 7.18 показаны ряд № 41 и прогнозы по нему для двух моделей, подобранных автоматически. В модели слева использовались ограничения, выведенные из свойств модели экспоненциального сглаживания, в модели справа – классические ограничения.
Как видим, модель с более широкими интервалами для постоянной сглаживания в данном случае дала более точный прогноз: sMAPE для нее составила 19,20%, в то время как для модели с классическими интервалами ошибка оказалась выше – 25,44%. Напомним, что более точный прогноз по данному ряду был получен лишь с помощью модели Брауна (параграф 7.2).
Теперь рассмотрим сезонный ряд № 1683. Для него также было построено две модели:
1. С интервалами, выводимыми из свойств ETS, ЕTS(M,A,A):
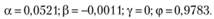
2. С классическими интервалами, ЕТS(M,N,A):

Мы уже сталкивались с ситуацией, когда постоянная сглаживания Р оказывалась близкой к нулю. При автоматическом подборе в первом случае она так же оказалась крайне маленькой, а во втором – вообще была убрана из рассмотрения, так как, судя по всему, вносила слишком малый вклад в аппроксимацию ряда.
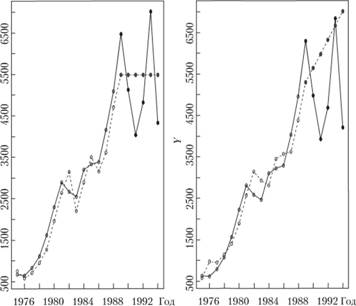
Рис. 7.18. Ряд данных № 41 и его прогноз:
сплошная линия – фактические значения;
прерывистая – расчетные значения
На рис. 7.19 показан этот ряд данных и прогнозы по нему для двух моделей, подобранных автоматически. В модели сверху использовались ограничения, выведенные из свойств модели экспоненциального сглаживания, в модели снизу – классические ограничения.
Можно обратить внимание на то, что вторая модель оказалась несколько завышенной и, не очень точно прогнозируя значения внизу тренда, дала более точный прогноз его пика. Первая же модель в среднем просто чуть лучше справилась с задачей. Это видно и по рассчитанным ошибкам аппроксимации: по первой модели sMAPE = 6,08%, по второй – 6,55%. Прогнозы, полученные автоматически, в данном случае можно назвать сопоставимыми по точности с прогнозами по остальным моделям экспоненциального сглаживания, рассмотренным нами в данном параграфе.
В целом, как видим, такой подход значительно облегчает жизнь прогнозиста и позволяет достаточно быстро получать точные прогнозы по моделям экспоненциального сглаживания.
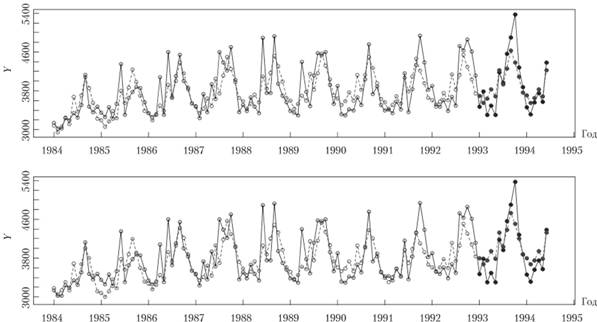
Рис. 7.19 Ряд данных № 1683 и его прогноз:
сплошная линия – фактические значения; прерывистая – расчетные значения