Вопросы программной реализации БД, организация хранения и доступ
Метод физического доступа – совокупность программных средств, обеспечивающих возможность хранения и выборки данных, расположенных на физических устройствах.
Пользователи стандартных СУБД обычно не проводят проектирование физической БД. Однако в большеразмерных и распределенных СУБД (например, Oracle) ведется распределение областей памяти. В силу этого знание характеристик физического расположения данных полезно.
Выделяют три основных режима работы приложений, связанных с использованием баз данных.
Режим 1. Получить все данные (последовательная обработка).
Режим 2. Получить уникальные данные (например, одну запись), для чего используют произвольный доступ (кэширование, идентификаторы), индексный метод (первичный ключ), произвольный доступ, последовательный доступ (бинарное В-дерево, В+-дерево).
Режим 3. Получить некоторые данные (группу записей), для чего применяют вторичные ключи, мультисписок, инвертированный метод, двусвязное дерево.
К физической модели предъявляются два основных противоречивых требования: 1) высокая скорость доступа к данным; 2) простота обновления данных.
Еще одним относительно новым требованием является объем дополнительно используемой (вторичной) памяти.
Введем необходимые дополнительные термины.
Для ускорения процесса поиска и упорядочения данных создаются индексные файлы. В качестве индексов могут выступать отдельные поля, прежде всего – ключи. Индексный файл меньше по размеру, и потому скорость поиска увеличивается. "Платой" за это является дополнительная, вторичная память. Индекс может быть многоуровневым (В+-деревья). Часто в качестве индексов используют числа.
Если одно и то же поле используется в индексе и для упорядочения записей файла, то индекс называют основным, а файл – индексно-последовательным. В противном случае индекс называют вторичным.
Если используется хотя бы один вторичный индекс, файл называют инвертированным.
Если вторичные индексы существуют для всех возможных полей, файл – полностью инвертированный.
В физической БД следует рассматривать методы размещения (запись и хранение) данных и методы доступа (поиск) к ним.
Основными методами хранения и поиска являются физически последовательный, прямой, индексно-последовательный и индексно-произвольный. Для их сравнительной оценки используем дна критерия [12].
Эффективность хранения – величина, обратная среднему числу байт вторичной памяти, необходимого для хранения одного байта исходной памяти.
Эффективность доступа – величина, обратная среднему числу физических обращений, необходимых для осуществления логического доступа.
Выделяют [9] первичные (физически последовательный и произвольный) и вторичные (мультисписковый, инвертированный файлы, двусвязное дерево) методы доступа.
Применительно к иерархической МД основные методы получили свои названия и аббревиатуры (рис. 9.2):
1) иерархически последовательный метод доступа (Hierarchical Sequential Access Method – HSAM);
2) иерархический прямой метод (Hierarchical Direct Access Method – HDAM);
3) иерархический индексно-последовательный метод (Hierarchical Indexed Sequential Access Method – HISAM);
4) иерархический индексно-произвольный метод (Hierarchical Indexed Direct Access Method – HIDAM).
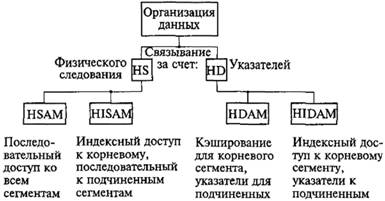
Рис. 9.2. Методы хранения и доступа
Дадим этим методам краткую характеристику [9].
Иерархически последовательный метод
Записи хранятся в логической последовательности, файл имеет постоянный размер, указатели могут отсутствовать. Данные хранятся в главном файле, а обновление требует создания нового главного [4, 10, 11] файла с упорядочением, для чего используется вспомогательный файл. Эффективность использования памяти близка к 100%, эффективность доступа низка.
Метод удобен для режима 1, однако быстродействие в режиме 2 мало: для его повышения необходимо использовать бинарный поиск (В- и В+-деревья). Время включения и удаления записей значительно.
Разновидностью метода является физически связанный (связанно-последовательный) метод, который называют также плотным. Имеются несмежные физические участки данных, используются указатели. Осуществляется динамическое перераспределение памяти: в одной и той же области памяти можно выполнять несколько процессов или работать с данными, обладающими большой изменчивостью. При включении и удалении данных меняется только логика поиска. В режиме 1 время поиска мало, в режиме 2 – большое. Затраты на вторичную память невелики. Применять бинарный поиск здесь нельзя из-за неплотной упаковки файлов и невозможности вычислять адреса.
В организации данных используется целая группа индексных методов, основными из которых являются индексно-последовательный и индексно-произвольный методы.