Моделирование и прогнозирование по временным рядам
Компоненты динамическою ряда и упрощенные приемы прогнозирования. Прогнозирование в экономике, как правило, связано с анализом временного ряда, который позволяет характеризовать закономерность изменения явления и экстраполировать ее на будущее (период прогноза).
При построении моделей по временным рядам необходимо учитывать компоненты динамического ряда. Уровни динамического ряда формируются под действием разных факторов. Одни из них являются основными на данном этапе исторического развития, а другие – случайными, несущественными с точки зрения содержания динамики. Фактическую величину уровня динамического ряда (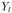 ) можно представить как функцию трех компонент:
) можно представить как функцию трех компонент:
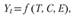 (9.1)
(9.1)
где 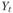 – фактический уровень динамического ряда в период времени t; T – тренд ряда (тенденция); С – периодические колебания (циклические, сезонные); Е – случайная компонента.
– фактический уровень динамического ряда в период времени t; T – тренд ряда (тенденция); С – периодические колебания (циклические, сезонные); Е – случайная компонента.
При анализе временного ряда прежде всего изучается тенденция ряда, определяющая основное направление развития явления за длительный период времени – тренд ряда (T); вместе с тем могут иметь место регулярные периодические колебания (циклические – длительностью в несколько лет, а также сезонные – внутригодичные), вызванные особенностями существования явления в одни периоды по сравнению с другими (С), это должно быть учтено при прогнозировании. Анализ будет не полным, если не исследовать случайные колебания, связанные с действием разного рода второстепенных факторов – случайная компонента (Е).
Названные компоненты временного ряда необязательно присущи каждому временному ряду. Могут быть ряды динамики, в которых отсутствует как тенденция, так и периодические колебания. В этом случае уровни ряда являются функцией случайной компоненты: они колеблются вокруг среднего уровня, что характерно для так называемого стационарного ряда. Прогноз по стационарному ряду основан на предположении о неизменности в будущем среднего уровня динамического ряда и может быть представлен в виде
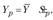 (9.2)
(9.2)
где 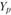 – прогнозное значение;
– прогнозное значение; 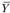 – среднее значение уровня динамического ряда;
– среднее значение уровня динамического ряда;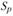 – средняя ошибка прогноза, определяемая как
– средняя ошибка прогноза, определяемая как
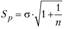 , где
, где 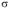 – среднее квадратическое отклонение по временному ряду; п – длина ряда.
– среднее квадратическое отклонение по временному ряду; п – длина ряда.
Для прогноза принято считать предельную ошибку (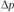 ), вероятность которой обычно не должна превышать 5%:
), вероятность которой обычно не должна превышать 5%:
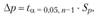
где 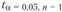 – табличное значение t-критерия Стьюдента при уровне значимости
– табличное значение t-критерия Стьюдента при уровне значимости 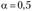 и числе степеней свободы
и числе степеней свободы 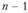 /
/
Рассматривается динамика потребления сахара на душу населения за год по региону, кг:
|
2000 |
2001 |
2002 |
2003 |
2004 |
2005 |
2006 |
2007 |
2008 |
2009 |
2010 |
2011 |
|
32 |
32 |
32 |
30 |
31 |
32 |
32 |
33 |
31 |
33 |
32 |
33 |
Требуется дать прогноз потребления сахара на душу населения в регионе на 2012 г.
В данном ряду динамики нет четко выраженной тенденции и периодических колебаний. Поэтому прогноз можно сделать, исходя из среднего уровня временного ряда. По простой средней арифметической получим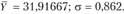 Табличное значение /-критерия Стьюдента при уровне значимости а = 0,05 и числе степеней свободы
Табличное значение /-критерия Стьюдента при уровне значимости а = 0,05 и числе степеней свободы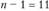 равно 2,201. Тогда предельная ошибка прогноза составит:
равно 2,201. Тогда предельная ошибка прогноза составит: 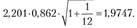
В результате прогноз на 2012 г. окажется равным: 31,9167 ± 1,9747, т.е. в интервале от 29,9 до 33,9 кг.
Однако большинство динамических рядов в экономике характеризуются тенденцией и случайными колебаниями. В этом случае прогноз можно дать с помощью обобщающих показателей динамики. Предполагая стабильным средний абсолютный прирост, прогноз можно представить в виде следующей экстраполяции:
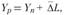
где 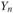 – конечный уровень динамического ряда;
– конечный уровень динамического ряда; 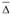 – средний абсолютный прирост уровня ряда в единицу времени;
– средний абсолютный прирост уровня ряда в единицу времени; 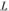 – период упреждения, т.е. на сколько временных интервалов дается экстраполяция.
– период упреждения, т.е. на сколько временных интервалов дается экстраполяция.
Средний абсолютный прирост можно найти по формуле
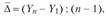 (9.3)
(9.3)
где 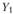 – начальный уровень динамического ряда.
– начальный уровень динамического ряда.
Если конечный уровень динамического ряда не характерен для исследуемого временного промежутка (резких колебаний в уровнях), то для прогноза используется более стабильный уровень (при этом дается его обоснование).
Например: кредиторская задолженность организаций (без субъектов малого предпринимательства) по РФ на начало года составляла (трлн руб.):
|
2005 |
2006 |
2007 |
2008 |
2009 |
2010 |
|
6,4 |
7,7 |
10,7 |
13,4 |
14,9 |
17,7 |
Требуется дать прогноз на 2011 г., т.е. период упреждения равен 1. Абсолютные приросты по данному ряду мало варьируют. Поэтому прогноз на начало 2011 г. можно дать исходя из среднего абсолютного прироста:
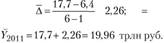
Фактически кредиторская задолженность по РФ на начало 2011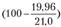 г. составляла 21 трлн руб. Ошибка прогноза равна 5%
г. составляла 21 трлн руб. Ошибка прогноза равна 5%
Прогноз на 2012 г. можно дать как 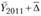 или
или 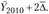 Используя приведенные данные, получаем, что кредиторская задолженность по РФ на начало 2012 г. по прогнозу составляла 17,7 + 2 ∙ 2,26 = 22,22 трлн руб. Фактически на начало 2012 г. задолженность была 23,63 трлн руб., т.е. ошибка прогноза составила 6% (чем больше период упреждения, тем больше ошибка прогноза).
Используя приведенные данные, получаем, что кредиторская задолженность по РФ на начало 2012 г. по прогнозу составляла 17,7 + 2 ∙ 2,26 = 22,22 трлн руб. Фактически на начало 2012 г. задолженность была 23,63 трлн руб., т.е. ошибка прогноза составила 6% (чем больше период упреждения, тем больше ошибка прогноза).
Другим обобщающим показателем динамики для краткосрочного прогноза может служить средний коэффициент роста (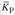 ), определяемый по формуле
), определяемый по формуле
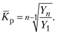
Прогнозное значение тогда может быть получено как 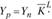 , где L – период упреждения.
, где L – период упреждения.
Для нашего примера средний коэффициент роста составил:
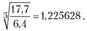
Соответственно, прогноз на 2011 г. окажется равным: 17,7 × × 1,225628 = 21,69 трлн руб. Ошибка прогноза меньше (3,3%), т.е. прогноз по среднему коэффициенту роста ближе подходит к фактическому показателю кредиторской задолженность по РФ на начало 2011 г.
Если примем период упреждения равный 2, то прогноз на 2012 г. составит: 17,7 ∙ 1,2256282 = 26,59 трлн руб. или 21,69 ∙ 1,225628 = = 26,59. Ошибка прогноза окажется 12,5%, что выше, чем при прогнозе по среднему абсолютному приросту. Это естественно, так как с увеличением периода упреждения один и тот же коэффициент роста будет сопровождаться увеличением абсолютного прироста, а такой тенденции в примере не наблюдалось.
Модели тренда. Закономерность изменения уровней динамического ряда выражается в виде модели тенденции, в которой уровни рассматриваются как функция времени у = f(t). Модель тенденции принято называть уравнением тренда. На его основе производится прогнозирование в виде экстраполяции тенденции.
Компьютерные программы анализа временных рядов содержат широкий набор математических функций для построения уравнения тренда. Эти функции можно свести в три группы:
– функции с монотонным характером возрастания (убывания) уровней ряда (линейная, параболы второго и более высокого порядков);
– кривые с насыщением, т.е. устанавливается нижняя или верхняя граница изменения уровней ряда (разного рода гиперболы);
– ..9-образные кривые, т.е. кривые с насыщением, имеющие точку перегиба (логистическая кривая и др.).
Рассмотрим первую группу трендов.
Линейный тренд
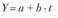
предполагает, что уровни динамического ряда изменяются с одинаковой скоростью, т.е. с равным абсолютным приростом (параметр b). Например, уравнение тренда для индексов потребительских цен за 12 месяцев года составило: 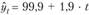 , где
, где 
 I. Из уравнения видно, что ежемесячно цены возрастали в среднем на 1,9 и. п.
I. Из уравнения видно, что ежемесячно цены возрастали в среднем на 1,9 и. п.
Параболу второй степени
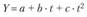
рекомендуется использовать для моделирования тенденции, если временной ряд характеризуется постоянным абсолютным ускорением, т.е. постоянными являются вторые разности (абсолютные приросты). В этой функции (как и в линейной) параметр а означает начальный уровень ряда динамики при t = 0. Параметр b при обозначении t как ряда натуральных чисел, что наиболее распространено при компьютерной обработке, экономически не анализируется. Параметр с характеризует половину абсолютного ускорения динамического ряда.
Например, динамика численности детей в районе в возрасте 7 лет за последние 15 лет характеризуется уравнением тренда
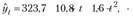
где у – тыс. человек, t = 1,2, ..., 15.
Следовательно, ежегодно численность детей сокращалась в среднем с ускорением в 3,2 тыс. человек.
Парабола третьей степени
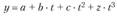
(и более высоких степеней) предполагает длинный динамический ряд: чтобы параметры тренда были статистически надежными, на каждый параметр при t должно приходиться не менее 6–7 временных единиц. Следовательно, парабола уже третьей степени должна основываться на временном ряде, охватывающем не менее 20 лет (если уровни ряда представлены но годам), что не всегда возможно.
Чаще отдают предпочтение функциям с меньшим числом параметров. Среди них широкое применение находит показательная функция
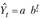
или равносильная ей экспонента
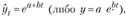
которые характеризуются стабильным коэффициентом (темпом) роста (параметр b).
Например, за ряд лет динамика прибыли характеризуется уравнением вида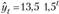 , где
, где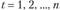 . Следовательно, ежегодно прибыль возрастает в среднем на 50% (коэффициент роста 1,5). Данный тренд в виде экспоненты примет выражение
. Следовательно, ежегодно прибыль возрастает в среднем на 50% (коэффициент роста 1,5). Данный тренд в виде экспоненты примет выражение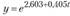 , где
, где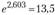 и
и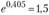 . Рост по экспоненте означает геометрическую прогрессию уровней динамического ряда, что бывает в течение сравнительно небольшого периода времени (например, ввели ограничения на ресурсы, изменения условий рынка).
. Рост по экспоненте означает геометрическую прогрессию уровней динамического ряда, что бывает в течение сравнительно небольшого периода времени (например, ввели ограничения на ресурсы, изменения условий рынка).
При моделировании тенденции используются и другие функции, приводимые к линейному виду. Так, при замедленном росте уровней ряда может использоваться полулогарифмическая кривая
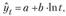
Предполагая разную меру пропорциональности изменений уровней во времени, может быть использована степенная функция
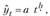
которая приводится к линейному виду путем логарифмирования:
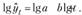
При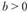 она характеризует непрерывный рост уровней с падающими темпами роста, а при
она характеризует непрерывный рост уровней с падающими темпами роста, а при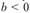 – их ускоренное снижение. Величина
– их ускоренное снижение. Величина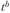 означает базисный коэффициент роста. Поэтому степенная функция сообщает о величине среднего коэффициента роста:
означает базисный коэффициент роста. Поэтому степенная функция сообщает о величине среднего коэффициента роста:
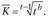
Например, степень износа основных фондов на предприятии за последние 7 лет характеризовалась уравнением вида 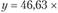
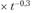 с коэффициентом дифференциации равным
с коэффициентом дифференциации равным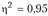 . Следовательно, за весь период износ основных фондов снизился на
. Следовательно, за весь период износ основных фондов снизился на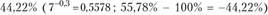 . В среднем ежегодно снижение составляло
. В среднем ежегодно снижение составляло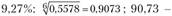

К кривым с насыщением можно отнести равностороннюю гиперболу вида
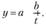
При b> 0 уровни ряда снижаются во времени и асимптотически приближаются к параметру а. Например, индексы потребительских цен (декабрь к декабрю предыдущего года) за 2008–2013 гг. по региону изменялись по гиперболе вида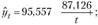 коэффициент дифференциации
коэффициент дифференциации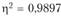 . Уравнение характеризует падающую тенденцию ИПЦ, при которой ИПЦ не может быть меньше 95,6%. Тренд описывает 99% вариации ИПЦ и лишь 1% ее связан с действием случайных факторов.
. Уравнение характеризует падающую тенденцию ИПЦ, при которой ИПЦ не может быть меньше 95,6%. Тренд описывает 99% вариации ИПЦ и лишь 1% ее связан с действием случайных факторов.
Если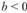 i, то уравнение тренда
i, то уравнение тренда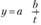 характеризует тенденцию роста уровней ряда с асимптотической границей равной параметру а.
характеризует тенденцию роста уровней ряда с асимптотической границей равной параметру а.
Среди кривых с насыщением широко распространена логистическая кривая, относимая к классу S-образных кривых (например, кривая Гомперца). Тенденция развития явления по этой функции на графике напоминает латинскую букву 5 и охватывает три этапа: вначале довольно медленный рост, который затем убыстряется, далее сменяется уменьшением роста и приближением уровня ряда к предельному значению, т.е. к уровню насыщения.
Логистическая кривая имеет вид
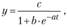
где с – верхняя асимптота; h и а – параметры функции; е – основание натурального логарифма. Довольно часто эта кривая используется для описания инноваций, т.е. развития производства новых товаров.
Г. Тинтнер[1] применил данную функцию для описания тенденции роста численности населения Швеции за 100 лет по десятилетним интервалам с 1850 по 1950 гг.:

Согласно этой кривой верхняя асимптота роста численности населения Швеции составила 10 328 806 человек (справочно: на 28 февраля 2013 г. население Швеции составляло 9,567 млн человек).
Оценка параметров уравнения тренда. При использовании полиномов разных степеней оценка параметров уравнения тренда производится методом наименьших квадратов (МНК), как и оценки параметров уравнения регрессии на основе пространственных данных. В качестве зависимой переменной рассматриваются уровни динамического ряда, а в качестве независимой переменной – фактор времени t, который обычно выражается рядом натуральных чисел: 1, 2, ..., п. Оценка параметров нелинейных функций проводится МНК после линеаризации, т.е. приведения их к линейному виду.
Рассмотрим применение МНК для оценки параметров показательной функции. Этот вопрос не излагался подробно в разделе регрессии. Для оценки параметров показательной кривой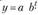 производится логарифмирование функции:
производится логарифмирование функции:
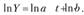
Затем строится система нормальных уравнений:
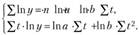 (9.4)
(9.4)
Рассмотрим пример. Доходы консолидированного бюджета Санкт-Петербурга за 2000–2009 гг. (млрд руб.) составляли:
|
2000 |
2001 |
2002 |
2003 |
2004 |
2005 |
2006 |
2007 |
2008 |
2009 |
|
37,9 |
51,8 |
66,6 |
77,2 |
95,3 |
142,7 |
218,1 |
281,3 |
343,1 |
319,8 |
Исходя из графического представления динамики доходов в качестве уравнения тренда была выбрана показательная кривая 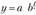 . Для построения системы нормальных уравнений были рассчитаны вспомогательные величины:
. Для построения системы нормальных уравнений были рассчитаны вспомогательные величины:
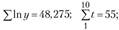
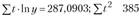 . Построена система нормальных уравнений:
. Построена система нормальных уравнений:
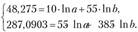
Решая ее, получим: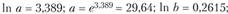
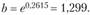
Соответственно, получаем либо показательную кривую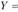
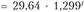 , либо экспоненту
, либо экспоненту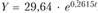 . За период с 2000 по 2009 гг. доходы консолидированного бюджета возрастали в среднем ежегодно на 29,9% (что в известной мере связано с инфляционной составляющей). Экспонента достаточно хорошо описывает тенденцию исходного временного ряда: коэффициент детерминации составил 0,9746. Так что данный тренд объясняет 97,5% колеблемости уровней ряда и лишь 2,5% ее связаны со случайными факторами.
. За период с 2000 по 2009 гг. доходы консолидированного бюджета возрастали в среднем ежегодно на 29,9% (что в известной мере связано с инфляционной составляющей). Экспонента достаточно хорошо описывает тенденцию исходного временного ряда: коэффициент детерминации составил 0,9746. Так что данный тренд объясняет 97,5% колеблемости уровней ряда и лишь 2,5% ее связаны со случайными факторами.
Некоторую специфику имеет оценка параметров логистической кривой. Асимптота с этой функции может быть задана исследователем на основе анализа временного ряда. Другие параметры оцениваются МНК, так как в этом случае функция линеаризуема:
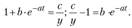
Обозначим через У величину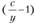 , получим:
, получим:
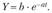
Прологарифмируем и получим линейную функцию:
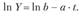
Применяя МНК, оценим параметры а и b. Если асимптота с не задана, то для оценки параметров используются специальные методы оценивания. Обзор этих методов изложен в работе E. М. Четыркина[2].
Выбор наилучшего уравнения тренда при прогнозировании. Для уравнения тренда в компьютерных программах указывается коэффициент детерминации (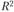 ). Чем выше
). Чем выше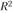 , тем, соответственно, выше вероятность того, что данная модель тренда лучше описывает исходные данные. В нашем примере
, тем, соответственно, выше вероятность того, что данная модель тренда лучше описывает исходные данные. В нашем примере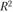 для экспоненты составил 0,9746, а для степенной функции – 0,8906, подтверждая, что экспонента в большей мере подходит для описания тенденции. Однако принято кроме
для экспоненты составил 0,9746, а для степенной функции – 0,8906, подтверждая, что экспонента в большей мере подходит для описания тенденции. Однако принято кроме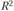 учитывать статистическую значимость параметров уравнения тренда по t-критерию. Если для рассмотренного примера построить параболу пятой степени, то получим уравнение
учитывать статистическую значимость параметров уравнения тренда по t-критерию. Если для рассмотренного примера построить параболу пятой степени, то получим уравнение
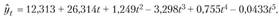
Хотя значение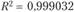 выше ранее полученных, но по ί-критерию Стьюдента на 5%-м уровне значимости все параметры этой кривой оказываются статистически незначимыми. Поэтому эту функцию нельзя считать лучшей формой уравнения тренда.
выше ранее полученных, но по ί-критерию Стьюдента на 5%-м уровне значимости все параметры этой кривой оказываются статистически незначимыми. Поэтому эту функцию нельзя считать лучшей формой уравнения тренда.
Уравнение тренда хорошо описывает тенденцию, если отсутствует автокорреляция в остатках (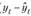 ), т.е. остатки текущего периода не коррелируют с остатками предыдущего периода. Измерить автокорреляцию в остатках можно с помощью коэффициента автокорреляции остатков:
), т.е. остатки текущего периода не коррелируют с остатками предыдущего периода. Измерить автокорреляцию в остатках можно с помощью коэффициента автокорреляции остатков:
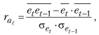 (9.5)
(9.5)
где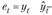 , т.е. остатки текущего периода;
, т.е. остатки текущего периода;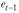 – остатки предыдущего периода;
– остатки предыдущего периода;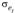 – среднеквадратическое отклонение текущего периода;– среднеквадратическое отклонение предыдущего периода.
– среднеквадратическое отклонение текущего периода;– среднеквадратическое отклонение предыдущего периода.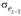
Эта формула основана на формуле линейного коэффициента корреляции. При определении остатков предыдущего периода ((в(-) динамический ряд укорачивается и при расчете коэффициента автокорреляции остатков ряды (и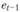 ) берутся одинаковой
) берутся одинаковой 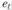 длины (от t = 2 до п).
длины (от t = 2 до п).
В примере с показательной кривой Y = 29,64 ■ 1,299' остатки (et и ес-]) составили:
|
|
-0,6 |
1,79 |
1,64 |
-7,17 |
-14,29 |
0,35 |
33,2 |
41,13 |
31,14 |
-85,41 |
|
|
- |
-0,6 |
1,79 |
1,64 |
-7,17 |
-14,29 |
0,35 |
33,2 |
41,13 |
31,14 |

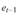
По этим данным коэффициент автокорреляции остатков равен 0,010453. Близость к 0 указывает на отсутствие автокорреляции остатков. Это означает, что уравнение тренда хорошо описывает тенденцию исходного ряда.
Доверительные интервалы прогноза но трендовым моделям. Прогнозирование по уравнению тренда включает нахождение интервалов прогноза. Поскольку модели тенденций по сути есть модели регрессии, в которых в качестве объясняющей переменной используется фактор времени, то интервалы прогноза по трендовым моделям определяются так же, как и по модели регрессии. Это означает, что по уравнению тренда строится точечный прогноз (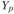 ), и далее определяется ошибка прогноза (
), и далее определяется ошибка прогноза (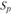 ). Ошибка прогноза зависит от отклонений уровней ряда от тренда (
). Ошибка прогноза зависит от отклонений уровней ряда от тренда (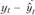 ), а также от длины временного ряда и периода упреждения.
), а также от длины временного ряда и периода упреждения.
Колеблемость уровней ряда измеряется в виде стандартного отклонения (Sy) по формуле
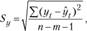 (9.6)
(9.6)
где ijt – фактическое значение уровня временного ряда; yt – расчетное значение уровня временного ряда, найденное по уравнению тренда; п – длина временного ряда; тп – число параметров при факторе времени t (в линейном тренде т = 1).
Чем больше стандартное отклонение (5,Д тем шире будет интервал прогноза для тренда. При прогнозе индивидуального значения уровня временного ряда ошибка прогноза (Sp) определяется как Sp= Sy• Q, где Q –поправочный коэффициент, величина которого зависит от длины временного ряда (п) и периода упреждения. Чем длиннее временной ряд, тем меньше ошибка прогноза (Sp). Чем больше период упреждения (период, на который дастся прогноз), тем больше ошибка прогноза (Sp).
Величина Q зависит также от вида уравнения тренда. Для линейного тренда у = a + b ■ t поправочный коэффициент Q определяется по формуле
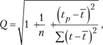 (9.7)
(9.7)
где 1р – порядковый номер прогнозируемого периода (при п = 10 fp = 11); 7 – среднее значение из порядковых номеров фактора времени I.
Рассмотрим пример. За 9 месяцев года расходы на рекламу составляли (тыс. руб.):
|
t |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
Y |
16 |
18 |
21 |
25 |
30 |
33 |
35 |
37 |
38 |
Требуется дать прогноз на октябрь. Ряд хорошо описывается линейным уравнением тренда Y = 13,028+3,0167 Г; К1 = 0,9735.
Подставив в уравнение ί = 10, найдем точечный прогноз: Ур = 43,19. Стандартная ошибка линии тренда составит:
Ошибка прогноза для расходов па рекламу в октябре составит:
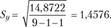
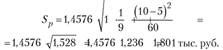
Эта величина рассматривается как средняя ошибка прогноза. Доверительный интервал прогноза принято давать исходя из предельной ошибки: Ар = ta ■ S/„ где ta – табличное значение критерия Стьюдента при а = 0,5 (вероятность ошибки 5%) и числе степеней свободы df=n-m – 1. В примере ¢//=9-1-1 = 7.
В нашем случае ta = 2,365. Отсюда предельная ошибка прогноза составляет: Aj> = 2,365 • 1,801 = 4,26. Тогда интервал прогноза расходов в октябре составляет: 43,19 ± 4,26, от 38,9 до 47,4 тыс. руб.
Аналогично дается прогноз и для нелинейных функций, сводимых при преобразовании к линейному виду. Отличие лишь в том, что в расчетах используются не фактические значения уровня ряда (УД и фактора времени t, а их преобразованные величины (In У, In t, 1 /t). Для степенной, показательной кривой сначала прогнозируется In У, затем, потенцируя, находится прогнозное значение У́. Для полиномов второй и более высоких степеней ошибку прогноза (Sp) определяют матричным методом (рассматривается в учебниках по эконометрике).