Триггерная обработка
Триггерные процедуры выполняются в случае наступления события по модификации данных, которое выражается в добавлении, изменении или удалении данных из таблицы. По своей сути триггерная процедура абсолютно идентична хранимой процедуре, но не может быть запущена пользователем, не может принимать исходные данные и возвращать результат обработки.
Таким образом, моделирование триггера сводится к обработке данных, полученных при выполнении операции добавления, изменения или удаления данных. Соответственно структура входных данных представляется структурой таблицы, модификация данных которой инициировала выполнение триггерной процедуры. При этом если выполняется действие изменения данных в таблице, то входящих потоков может быть два: один поток отражает сведения, которые были внесены в таблицы, а второй поток данные, которые были в таблице до внесения новых сведений. Обработке же в триггере подлежат только записи, которые были задействованы в операции модификации данных, а все остальные записи изменяемой инициирующей таблицы остаются невидимыми для триггера и могут быть получены только в виде результата запроса к этой таблице.
Пример
Предположим, что требуется изменить значение общего количества товара на указанном складе, увеличив его на количество поступившего товара. Выполнение операции осуществляется триггером на основе добавления новой записи в таблицу поступления товаров на склад. Операция инициируется после выполнения добавления данных и использует внесенные в новую запись данные.
Как и для хранимой процедуры, в модели триггерной операции определяются исходные данные и начальные и конечные операции (рис. 5.75).
|
Рис. 5.75. Подготовка процесса для моделирования триггера |

Поскольку триггер не может ни принимать, ни возвращать данные, то начальным и конечным элементами данных является структура таблицы, которая инициировала его выполнение. В рассматриваемом случае входные данные отражают новые данные, которые были добавлены в таблицу поступления товаров. Это отражается названием первой задачи "Получение добавленной записи". Именно эти данные и будут обрабатываться в процедуре. Стоит заметить, что начальная операция может быть представлена в виде проверки целесообразности выполнения триггерной обработки.
Дальнейшая работа процедуры сводится к проверке существования записи в таблице хранилища общего количества товаров на складах и в соответствии с полученным результатом добавлению новой записи или изменению имеющегося значения.
Для начала необходимо определить выборку для проверки наличия записи (рис. 5.76), что в этот раз будет описано непосредственно в процедуре, а не в глобальном процессе.
|
Рис. 5.76. Добавление проверки существования записи в хранилище |
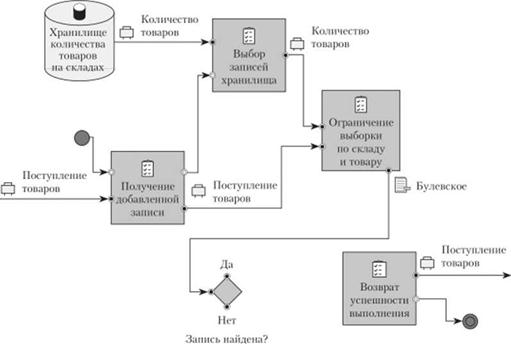
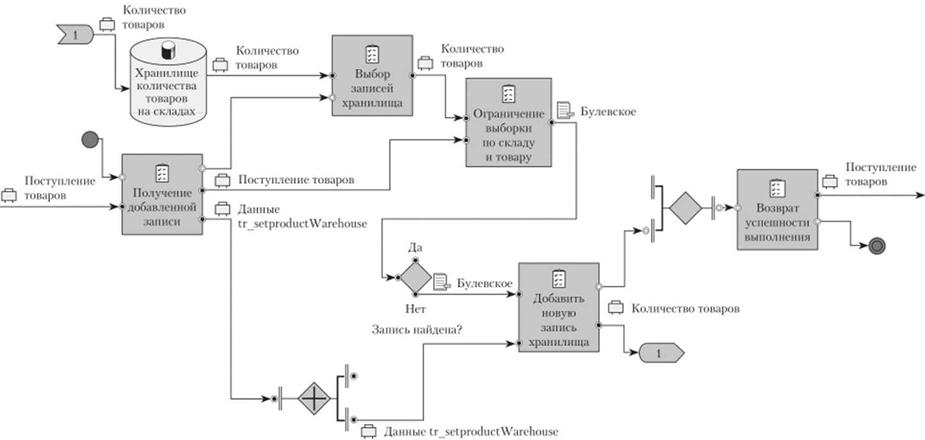
Результатом операции является возвращение признака успешности поиска. Если запись нс найдена, то генерируется комбинация значений для добавления данных и выполняется операция добавления (рис. 5.77).
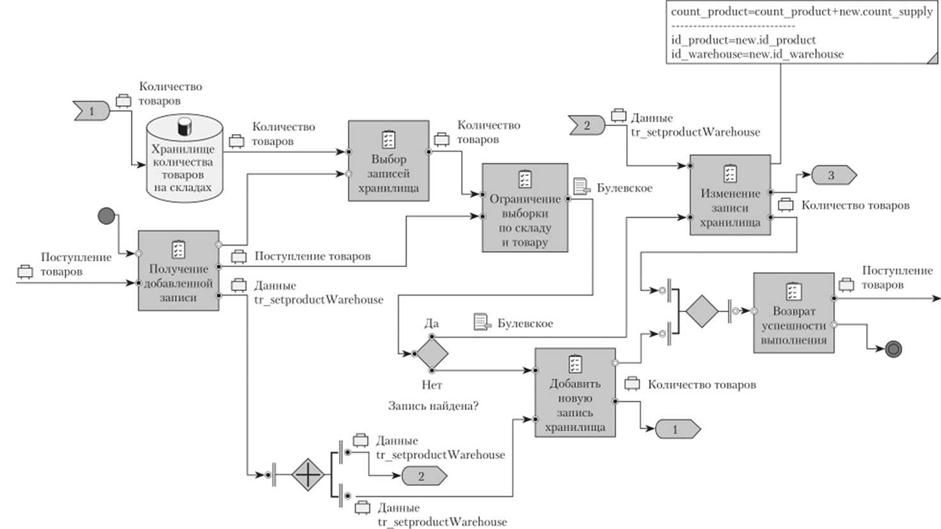
В случае, когда запись в хранилище существует, необходимо внести изменения, что выполняется другой задачей (рис. 5.78).
Выполнение операции изменения данных в хранилище сопряжено с необходимостью не только выполнить присвоение данных, но и выбрать нужную запись. Поскольку в рассматриваемом случае нет необходимости использовать другие таблицы, кроме хранилища, то выборка представляется простой и описывается только правилами ограничений. В случае, когда нужно использовать дополнительные таблицы, рекомендуется сформировать специальный процесс но ограничению записей в изменяемой таблице, а потом использовать результат в качестве условий ограничения.
В модели для указания правил изменения и ограничения вводится комментарий к операции изменения, где указываются операции присвоения и через разграничительную линию — операции ограничения.
В результате получается полная модель триггерного действия, которая может быть реализована в СУБД.
|
Рис. 5.77. Добавление операции внесения новых данных в хранилище |
|
Рис. 5.78. Добавление операции изменения хранилища |