Лекция 6. ТЕОРИЯ И ПРАКТИКА МАТЕМАТИЧЕСКОГО МОДЕЛИРОВАНИЯ УПРАВЛЕНЧЕСКИХ РЕШЕНИЙ
В результате изучения данной главы студент должен:
знать
• межпредметные связи различных дисциплин, изучаемых в высшей школе, связанные с задачей принятия решений;
• методы и механизмы идентификации моделей при исследовании конкретных социально-экономических объектов и управлении ими;
• возможности применения формализмов теории распознавания образов, игровых, логико-лингвистических, нейронных моделей;
• методы построения признакового пространства исследования сложных СЭС;
• сущность методов коллективной выработки управленческих решений;
уметь
• выявлять условия функционирования исследуемого объекта (системы);
• формировать модель исследуемого процесса (экономического, социального, технологического и т.д.) и модель принятия решения;
• осуществлять масштабирование и нормирование исходных данных для моделирования;
• решать с помощью стандартных пакетов программ задачи корреляционного анализа и идентификации неизвестных зависимостей;
владеть
• методами формализации задачи принятия решения (постановкой ее на языке математики);
• технологиями построения теоретических и эмпирических моделей;
• методами и технологиями идентификации критериев и ограничений оптимизации конкретных экономических и управленческих задач;
• методами регуляризации при построении моделей (метод группового учета аргументов);
• программным обеспечением моделирования экономических процессов и их оптимизации.
Идентификация моделей управляемых процессов и процедур
Под идентификацией модели объекта понимается набор процедур, обеспечивающих выявление и расчет вида и параметров модели. Различают идентификации в широком и в узком смысле. В первом случае определяется и вид модели, и ее параметры. В задаче 5.2 в формуле (5.4) мы постулировали квадратичный вид модели. В основу было положено лишь наше визуальное представление об этой функции на достаточно ограниченном промежутке изменения переменных и и у. Такое представление имеется далеко не всегда. Если вид модели априори известен и построение модели заключается только в расчете ее параметров, то говорят об идентификации в узком смысле. Что и было сделано в рассматриваемом примере.
Идентификация моделей в зависимости от степени неопределенности исходных данных может осуществляться на основе различной по качеству информации: исчерпывающих априорных данных, статистических наблюдений, экспертной информации.
Задача 5.7 параграфа 5.2 иллюстрирует использование экспертной информации. К экспертной информации следует отнести суждения:
• что вид затратной функции предприятия – квадратичный;
• что число классов погодных условий в задаче 5.8 и число классов предприятий в задаче 5.9 равно двум;
• что мера близости, определяющая расстояние между предприятиями, является простой евклидовой (задача 5.9) и т.д.
К технологиям принятия ответственных решений в экономике на основе применения математических методов следует относиться с большой осторожностью. Важно не просто построить модель, удовлетворяющую математическим критериям адекватности, но и правильно интерпретировать полученный результат.
Пример 6.1. Вот показательный тому пример, заимствованный в монографии по менеджменту.
В передаче по центральному телевидению от 13 августа 2006 г. представитель частного бизнеса, оправдывая перед зрителями канала увеличение розничных цен на бензин, приводит следующие аргументы: оптовая цена топлива (цена завода) возросла на 5%, наша (розничная) только на 4%. То есть, по его логике, он и сотоварищи по бизнесу остались еще и в проигрыше. Самое время посочувствовать. Что же есть на самом деле? Представьте следующую молельную ситуацию: оптовая цена 100 усл. ед., розничная – 200. 20%-ное увеличение первой определяет цену в 120 усл. ед., и чтобы получить свою прибыль в 100 усл. ед., реализатор должен поднять розничную цену до 220 усл. ед. Это соответствует лишь 10%-ной надбавке, и проигрыша здесь нет. В том конкретном случае оптовая цена бензина от 10 руб. за литр поднялась до 10,5 руб. Розничная цена, равная 17 руб. и увеличенная на 4%, дала результирующее значение в 17,68 руб. Таким образом, к увеличению цены на 0,5 руб. за счет увеличения цены оптовых поставок добавилось 0,18 руб. от розничных продавцов. Но свою долю увеличения цены они искусно скрывают, перекладывая ответственность на другой уровень бизнес-деятельности.
Нестационарность, нелинейность, неопределенность СЭС вносят существенные ограничения на используемые математические методы исследования. Чтобы снять возможные ограничения, необходимо:
• перейти к моделям, адекватно отражающим постановку задачи управления социально-экономическими объектами (теория распознавания образов, игровые модели, логико-лингвистические, нейронные);
• отказаться от необоснованных априорных установок, но включить методы регуляризации вычислительных процедур и методы самоорганизации моделей, компенсирующие недостаток информации.
Прокомментируем вышесказанные предложения.
1. При построении модели по статистическим данным мы отказываемся от обычного понятия решения системы линейных алгебраических уравнений и используем понятие обобщенного решения, регуляризующего некорректность системы, связанную с ошибками данных (см. задачу 5.5).
Пусть, например, исследуется временной ряд, но условия для расчета адекватных автокорреляционных моделей не выполняются. В этом случае следует перейти к итерационной процедуре прогноза исследуемого процесса, используя на каждом шаге прогноз ряда не в "точку", предсказывая очередное значение ряда, а в "класс", предсказывая с помощью теории распознавания образов только рост или падение следующего значения. Такая процедура возможна, только если процесс нестационарен. Каждый шаг введенной процедуры осуществляет адаптацию модели.
2. Методы самоорганизации для построения моделей в силу их особой важности рассмотрим подробнее.
Принципы самоорганизации сформулированы английским ученым Д. Габором. В области идентификации (построение моделей) сложных процессов или объектов теория самоорганизации получила свое развитие в работах А. Г. Ивахненко. Идея самоорганизации оказалась весьма плодотворной для создания регрессионных моделей. Обычный регрессионный анализ позволяет построить математическую модель по критерию минимума среднеквадратической ошибки на всех заданных точках. При этом, чем выше порядок уравнения, тем точнее модель, а как только число коэффициентов уравнения превысит число заданных точек, получается бесчисленное множество моделей с нулевой ошибкой. Единственную модель найти нельзя. Для ее выбора (так называемой модели оптимальной сложности) нужно воспользоваться еще одним критерием. Основной недостаток современного математического моделирования состоит именно в неудачном выборе этого второго критерия селекции. Обычно выбирается степень полинома регрессии, число членов регрессионной модели, состав учитываемых признаков и т.д. Выбор второго критерия должен определяться только целью решаемой задачи; так, например, для решаемой задачи прогнозирования – это минимум ошибки предсказания на дополнительной (не участвовавшей в расчете коэффициентов) последовательности данных.
Справка. "Точнее" означает лучшее приближение критерия с точки зрения наименьших квадратов к экспериментальным данным кривой уравнения регрессии.
Сказанное выше можно проиллюстрировать с помощью рис. 6.1.
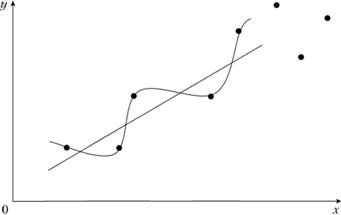
Рис. 6.1. Два возможных варианта подбора зависимости между у и х
Через первые пять точек, изображенных на рис. 6.1, можно провести бесчисленное множество кривых, описываемых полиномом со степенью выше пятой. Все они будут иметь нулевую ошибку по критерию метода наименьших квадратов. Однако практическое применение этих моделей для прогнозирования поведения наблюдаемого процесса или объекта невозможно. Наиболее подходящее уравнение для упомянутых точек – уравнение прямой линии (если судить визуально по представленному на рисунке фрагменту данных – экспертное мнение).
Основными принципами метода самоорганизации, применяемыми при построении моделей процессов или объектов, являются следующие: пошаговая процедура принятия решений, свобода выбора решений, отбор лучших вариантов решений (моделей) на основе внешнего критерия.
Принцип свободы выбора последующих решений заключается в многорядной структуре принятия решений, при которой в каждом из последующих рядов сохраняется возможность выбрать любые из некоторого числа лучших решений предыдущего ряда. Принципы свободы выбора решений и пошаговая (многорядная) процедура принятия решения впервые реализованы в персептроне. Персептроп состоит из нескольких рядов настраиваемых связей. После каждого ряда связей стоит специальное устройство, пропускающее в следующий ряд наиболее вероятные решения. На последнем устройстве принимается единственное и окончательное решение. Критерием выбора оптимальных решений является принцип внешнего дополнения, отражающий конечную цель исследования. Для задачи по построению моделей таким критерием может являться прогнозирующая способность модели на отдельной, проверочной последовательности данных, не участвующих в построении модели.
Указанные принципы самоорганизации определяют селекцию моделей с постепенно усложняющейся структурой. Лучшие из них по некоторому критерию, обладающему свойствами внешнего дополнения, пропускаются в следующий ряд моделирования, худшие – отбрасываются. В конце селекции имеем единственную модель оптимальной сложности.
Общая схема структуры алгоритмов самоорганизации моделей на компьютере представлена на рис. 6.2. Она состоит из генератора моделей (ГМ), на выходе которого (в порядке повышения сложности) получаются варианты моделей, и селектирующего устройства (К), выбирающего (по заданному внешнему критерию, обладающему свойствами внешнего дополнения) лучшую модель (В).
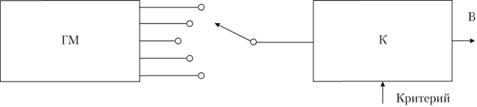
Рис. 6.2. Структурная схема алгоритмов самоорганизации моделей на компьютере
Различают две основные структуры алгоритмов самоорганизации (известны под названием метода группового учета аргументов – МГУА):
• комбинаторные алгоритмы МГУА с занулением коэффициентов (при п < N, где п – число членов уравнения, N – число наблюдений);
• многорядные, непороговые алгоритмы МГУА (при п > N).
При использовании комбинаторного алгоритма предварительно объект или процесс описывается полиномом высокой степени. Частные описания объекта или процесса получаются из предварительного "полного описания" с помощью приравнивания нулю отдельных его коэффициентов. Коэффициенты частного описания находятся при помощи метода наименьших квадратов. Структура модели определяется по внешнему критерию.
При использовании многорядного (порогового) алгоритма МГУА на первом ряду селекции строятся частные описания объекта или процесса, состоящие из двух переменных:
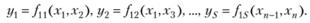
N1 лучших из них по критерию внешнего дополнения отбираются и образуются частные описания второго ряда:
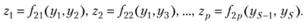
N2 из них используются в третьем ряду и т.д. В конце селекции получаем единственную модель.
Трудности при использовании регрессионного анализа возникают на этапе выбора типа регрессионной модели. Выбор сводится к определению факторов, от которых зависит выходная переменная у, и конечного числа функций этих факторов, включаемых в вектор X. Сказанное выше хорошо иллюстрируется рис. 6.3.
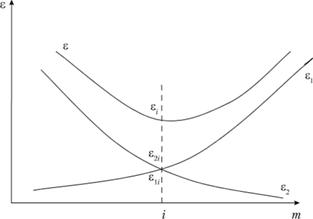
Рис. 6.3. График изменения величины среднеквадратического отклонения (s) линии регрессии от экспериментальных данных в зависимости от числа (те) учтенных в модели факторов:
Ошибки построения модели: εi – общая среднеквадратическая ошибка; ε1i – ошибка, связанная с наличием погрешностей в значениях xi; ε2i – ошибка, связанная с тем, что фактор xi не будет учтен в модели
Здесь на оси абсцисс откладывается "сложность" модели (например, число учитываемых факторов, различные комбинации между ними), а на оси ординат – ошибки построения модели. Каждый введенный фактор вносит в общую ошибку две составляющие – 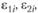 вопрос о включении в модель этого фактора определяется на основе сравнения
вопрос о включении в модель этого фактора определяется на основе сравнения 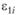 и
и 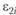 .
.
При решении этой задачи действуют две противоположные тенденции. С одной стороны, необходимо учесть в модели как можно больше факторов, чтобы она полнее отражала реальный процесс. Однако практический расчет и использование переусложненной модели затрудняются из-за сложности получения большого количества информации и сложности расчета. Кроме того, в случае даже небольшого нарушения условий применимости регрессионного анализа (допустим, наличие корреляционной связи между учтенными в модели факторами) адекватность такой модели ухудшается.
Применение слишком простых и переусложненных моделей может привести к большим ошибкам (см. рис. 6.3).
Необходимы модели оптимальной сложности. Единственную модель оптимальной сложности с помощью обычного регрессивного анализа получить нельзя. Ниже представлена обобщенная схема алгоритма построения модели сложного объекта (рис. 6.4).
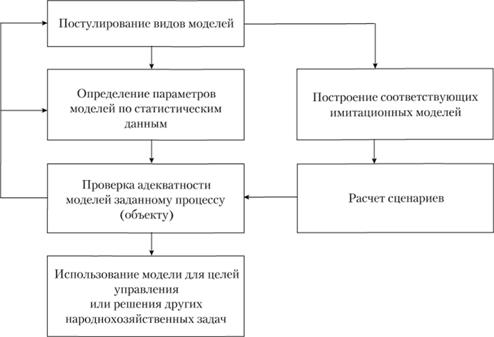
Рис. 6.4. Расширенная блок-схема построения математической модели
На первом этапе на основании известных о системе сведений постулируется вид математической модели. Далее схема имеет ветвления: если об объекте есть достаточная априорная и статистически репрезентативная информация, то на втором шаге, исходя из предполагаемого вида модели и располагая этими эмпирическими данными наблюдений за системой, находятся неизвестные характеристики модели (коэффициенты дифференциального уравнения, весовая функция системы и др.). Третий шаг в этом случае построения модели предполагает проверку адекватности реального объекта построенной модели. В случае удовлетворительного соответствия объекта и модели последняя используется для целей управления или решения других народнохозяйственных задач. В противном случае мы получаем дополнительный материал (в результате обработки данных) о свойствах реального объекта и возвращаемся к первому пункту – постулирование вида модели. Иногда возникают трудности вычислительного характера (некорректно поставленные задачи, см. гл. 5). Они возвращают нас ко второму шагу и требуют искать новых (регуляризованных) методов решения задачи.
Если эмпирических данных недостаточно, то следует пройти по иному "маршруту" схемы (см. рис. 6.4):
• для каждой из моделей-претендентов формируется соответствующая имитационная модель;
• моделируются начальные условия и управляющие воздействия (сценарии);
• проверяются результаты моделирования, и отобранные модели используются для целей управления объектом автоматизации.
Приведенные выше определения не учитывают тот факт, что модель создается не только для управления объектом, а также для идентификации его свойств, прогнозирования развития процесса. Прокомментируем данное замечание на примерах, рассматривающих следующие ситуации.
Пример 6.2. Построение модели идентификации свойств объекта. Рассмотрим случай двух переменных хi и yi. Результаты легко обобщаются, если вход представлен вектором X.
Пусть мы имеем последовательность данных хi и yi, полученных в результате i-го наблюдения, где i = 1, ..., N – номер наблюдения.
Таблица 6.1
Исходные данные для моделирования
|
i |
1 |
2 |
3 |
… |
N |
|
х |
х1 |
х2 |
х3 |
… |
xN |
|
y |
y1 |
y2 |
y3 |
... |
yN |
Чтобы ответить на поставленный вопрос, сначала разобьем нашу последовательность данных на две обучающие выборки:
{хi, yi} – первая обучающая выборка, где i = 1, .... No1;
{хi, yi} – вторая обучающая выборка, где i = 2, ..., N02.
Таким образом, получаем
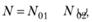
где, например N01 – все нечетные наблюдения; N02 – все четные наблюдения.
Далее, задавая различные типы моделей (как правило, от простых к сложным), построим их одновременно и по первой обучающей выборке N01, и по второй N02. Получим совокупности моделей вида (табл. 6.2).
Таблица 6.2
Совокупности сравниваемых моделей
|
Тип модели |
По первой выборке N01 |
По второй выборке N02 |
|
1 |
|
|
|
2 |
|
|
|
… |
… |
… |
|
п |
|
|
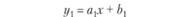
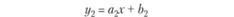
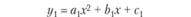
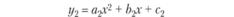
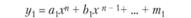
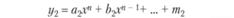
Сравниваем полученные модели по параметрам а, b, с, т и т.д., например, с помощью критерия
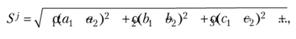 (6.1)
(6.1)
где α1, α2, α3 – некоторые весовые коэффициенты, отражающие значимость членов модели и выравнивающие их размерность; j – номер модели.
Отбираем адекватную модель, исходя из минимальной степени различия параметров, т.е.
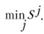 (6.2)
(6.2)
Пример 6.3. Построение модели прогноза развития процесса. Как и в предыдущем примере, разобьем нашу последовательность данных на две выборки, только теперь рассмотрим их как обучающую Nо и прогнозную Nn выборки данных 
По обучающей выборке Nо, как и в предыдущем случае, построим различные типы моделей – уj, j = 1, 2, ..., п. По этим моделям для входных данных прогнозной выборки делаем прогнозы. Получим табл. 6.3.
Таблица 6.3
Сравнение моделей по результатам прогноза
|
x |
x1 |
х2 |
… |
xi |
… |
хк |
|
yн |
|
|
… |
|
… |
|
|
y1 |
|
|
|
|
||
|
… |
||||||
|
yj |
|
|
|
|
||
|
… |
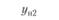
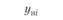
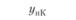
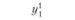
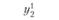
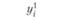
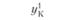
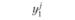
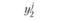
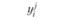
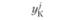
В первой строке табл. 6.3 указаны значения входной величины проверочной последовательности. Во второй строке стоят наблюдаемые значения выхода, соответствующие заданным входам. В последующих строках поставлены соответствующие расчетные значения выходов по построенным моделям.
Оценим качество j-й модели, например, по среднеквадратическому критерию:
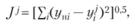 (6.3)
(6.3)
где yнi – наблюденные значения переменной у в i-м наблюдении: 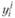 – прогнозируемые значения переменной у в i-м наблюдении j-й модели.
– прогнозируемые значения переменной у в i-м наблюдении j-й модели.
Отбираем наиболее адекватную модель согласно критерию 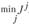 . На рис. 6.3 первые пять точек представляют собой обучающую последовательность, последние три точки – проверочную. По данным обучающей последовательности построено две модели: первой и пятой степени. Их качество легко сравнить по последним трем точкам. Очевидно, что линейная модель обладает лучшими прогнозными свойствами.
. На рис. 6.3 первые пять точек представляют собой обучающую последовательность, последние три точки – проверочную. По данным обучающей последовательности построено две модели: первой и пятой степени. Их качество легко сравнить по последним трем точкам. Очевидно, что линейная модель обладает лучшими прогнозными свойствами.
Пример 6.4. Построение модели для управления объектом. Особенность этой модели состоит в том, что она, в отличие от ранее рассмотренных, предназначена не для выявления экономической сущности явления, не для прогноза будущего, а для нахождения необходимого входного воздействия, приводящего к заданному выходному. Таким образом, процедура состоит в следующем:
• по имеющимся данным строится искомая модель
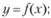 (6.4)
(6.4)
• задается желаемое значение у = уж;
• решается уравнение
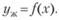 (6.5)
(6.5)
На последнем этане могут возникнуть вычислительные проблемы. Нахождение обратного оператора f-–1(x) не всегда устойчиво. Этому вопросу посвящен параграф 7.3.
Кроме того, на результаты расчетов влияют ошибки в исходных данных. Вот простой иллюстративный пример.
Пример 6.5. Пусть нам известен истинный закон взаимодействия входной переменной х и выходной у, описываемый следующей моделью:
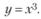 (6.6)
(6.6)
Пусть также в некотором конкретном наблюдении точное значение переменной хт = 5, тогда переменная у согласно формуле (6.6) принимает значение у(хт) = 125.
Рассмотрим ситуацию, когда нам известно неточное значение переменной х, а приближенное хп = 4. Ошибка по входу в данном случае составляет 20% (ε = 20%). Прогнозируемое значение переменной у по модели (6.6) равно у(хп) = 64, что составляет ошибку, равную почти половине истинного значения переменной у (ε = 50%). Для уменьшения ошибки в прогнозе у(хп) на некотором промежутке данных рассмотрим не истинную зависимость переменных х и у, а, например, линейную:
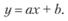 (6.7)
(6.7)
При линейной форме связи переменных ошибка в прогнозе значения переменной у(хп) составляет уже менее 20%. Действительно, ошибка в выражении ах составляет те же 20%, а свободный член b от ошибки во входной переменной х не зависит.
Таким образом, для обеспечения эффективного (более точного) управления объектом в данном случае необходимо подобрать соответствующую модель. Идея предложения состоит в том, что при построении модели, не имея точных данных, мы переходим от истинной модели объекта к той, которая даст наименьшую ошибку в прогнозе.