Лекция 18. СТРУКТУРНОЕ МОДЕЛИРОВАНИЕ И ПРОБЛЕМА ПРОПУЩЕННЫХ ДАННЫХ
Главной целью настоящей главы является краткое описание метода структурного моделирования или моделирования структурных уравнений (structural equation modeling, SEM). Впервые описанный нами в конце 1980-х гг. | Корнилова, Шуранова, 1987], этот метод, крайне популярный в психологии, социологии и экономике на Западе, получил признание и в российской психологии, о чем свидетельствует использование его в квалификационных работах студентов и аспирантов, а также растущее применение SEM в научных публикациях (в отечественной периодике — преимущественно в контексте так называемого конфирматорного факторного анализа).
Как и иерархическое линейное моделирование, представленное выше, структурное моделирование формально полагается на идеи, лежащие в основе регрессионного анализа. Принципиальным же отличием структурного моделирования от регрессии является сложная многомерность, т.е. возможность указания в модели множества аналогов зависимых и независимых переменных. Задачей структурного моделирования является проверка пригодности теоретической модели, т.е. ее соответствие наблюдаемым в конкретном исследовании данным. Под данными подразумеваются матрицы ковариации между переменными, интересующими исследователя. Отметим, что хотя структурное моделирование часто нацелено на проверку направленных или каузальных гипотез и именно такая проверка сложных гипотез выделяет структурное моделирование из ряда других методов, правомерность указания на "каузальность" ограничивается типом исследования (например, корреляционное исследование, истинный эксперимент), породившего данные, включенные в модель. Очевидно, что структурное моделирование носит копфирматорный (или подтверждающий), нежели эксплораторный (поисковый), характер, поскольку проверяется пригодность заданной исследователем модели. Экспликация структурных отношений между переменными позволяет более явно представить проверяемую теорию и гипотезы. Таким образом, структурное моделирование является методом проверки сложных систем теоретически обоснованных гипотез в их единстве.
Возможно двуплановое представление структурных моделей: 1) как в качестве наглядных диаграмм или схем, 2) как систем регрессионных уравнений. Любая структурная модель может быть представлена как диаграмма, на которой указаны взаимоотношения между переменными (двунаправленные, т.е. обозначающие ковариацию, или однонаправленные, предполагающие предсказание одной или нескольких переменных исходя из значений других переменных), которая неизбежно (на уровне вычислительных операций) трансформируется в систему регрессионных уравнений. Конвенционально на диаграммах моделей прямоугольниками обозначаются наблюдаемые переменные (НП, не путать с независимой переменной), измеренные исследователем, а овалами — ненаблюдаемые, или латентные переменные (ЛП). Последние представляют наибольший интерес для психолога, изучающего аспекты психологической реальности, прямо не наблюдаемые (например, самооценка, интеллект и т.д.). Наблюдаемые переменные являются "показателями" латентных переменных, которые невозможно прямо измерить. Психологические исследования направлены на проверку гипотез о латентных переменных или факторах, которые предоставляют определенный уровень абстракции, позволяющий описывать отношения между классами событий или переменных, у которых есть что-то общее, нежели делать высококонкретные утверждения, ограниченные отношениями между специфическими переменными.
ЛП служат цели операционализации ЛП, понимаясь как частные случаи манифестации ЛП. Взаимоотношения между ПП и соответствующим им ЛП задаются в рамках так называемых моделей измерения (measurement model), определяющих паттерн нагрузок ПП на соответствующие им факторы, прямо операционализируя ненадежность в терминах ошибок измерений (диагональные стрелки сбоку от НП па рис. 18.1). В общем виде модели измерения представляют собой системы регрессионных уравнений, предсказывающие НП на основе ЛП путем вычислительных методов, описанных далее, и определяющие необъясненную ЛП дисперсию в НП как ошибку измерения. Структурные же модели {structural models, см. рис. 18.1) задают паттерн взаимоотношений между латентными переменными, включая указание на то, какие ЛП являются экзогенными (т.е. независимыми переменными), а какие — эндогенными (зависимыми переменными).
Процесс моделирования можно условно разделить на четыре этапа — спецификация модели, вычисление модели, оценка модели и се модификация. На первом этапе исследователь задает паттерн взаимоотношений между переменными. На втором этапе происходит итеративный подбор значений коэффициентов, соответствующих всем заданным показателям моделей, направленный на минимизацию определенной функции, чаще всего — получения данных в условиях заданной модели (так называемый метод максимального подобия, maximum likelihood, ML). На третьем этапе исследователь оценивает пригодность полученной модели на основании индексов пригодности (fit indices), свидетельствующих о степени расхождения между структурой данных и структурой, заданной моделью. В случае обнаружения несоответствия модели данным исходная модель или отвергается (консервативный подход к моделированию), или модифицируется в соответствии с дополнительными соображениями исследователя, а затем подвергается проверке снова. Важной особенностью SEM является возможность проверки альтернативных моделей при сопоставлении их индексов пригодности, что позволяет проводить прямое сравнение конкурирующих теорий на основе общих данных.
Важными областями применения SEM являются конфирматорный факторный анализ (позволяющий проверять гипотезы о структурах ненаблюдаемых факторов па основе измерений переменных), многоуровневое моделирование и внешняя валидизация моделей, а также анализ лонгитюдных данных (см. гл. 19). Концептуальные и технические вопросы реализации структурного моделирования обсуждаются в специальных работах, раскрывающих основы SEM [Григоренко, 1994; Корнилов, 2012; Savalei, Bentier, 2006].
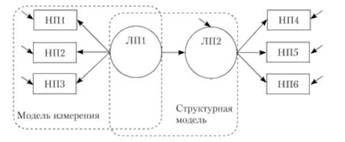
Рис. 18.1. Схема соотношения структурной модели и модели измерения
Структурное моделирование — один из немногих методов анализа, позволяющий строить и визуализировать сложные системы гипотез о связях между переменными, как наблюдаемыми, так и латентными. Среди достоинств метода — возможность работы с данными, не соответствующими нормальному распределению (так называемыми многомерно ненормальными данными) и с пропущенными данными (этому соответствуют, например, пропуски некоторых методик у ряда испытуемых).