Система повторного исполнения микроопераций
В процессорах архитектуры NetBurst имеется специальная система повторного исполнения МО, которая включается в работу в тех случаях, когда к моменту исполнения МО операнды оказываются не готовы. Такая ситуация может возникнуть, например, если она была отправлена планировщиком в конвейер, исходя из предположения, что операнд должен находиться в кэш данных первого уровня, а на самом деле его там не оказалось.
Как уже отмечалось, основная задача планировщиков состоит в максимально возможной загрузке исполнительных блоков работой. Поскольку конвейер длинный, необходимо формировать очередь из достаточно большого числа МО. При этом они отправляются в конвейер в такой очередности, чтобы к моменту их прихода на исполнительные блоки операнды были готовы. Если длительность исполнения МО (с учетом времени доставки операндов) известна, никаких проблем не возникает.
Пусть, например, идет цепочка МО, в которой результат предыдущей является операндом для последующей. В этом случае, если операнд самой первой операции хранится в регистровом файле, вся цепочка будет выполнена с максимально возможной скоростью. Иная ситуация возникает, если он хранится в ячейке памяти. В этом случае первая операция будет отправлена планировщиком на конвейер из предположения, что операнд находится в кэш данных первого уровня и для его доставки требуется определенное для данного процессора число тактов, т.е. за время исполнения всех МО, стоящих перед ней, операнд будет доставлен в исполнительный блок. Представим, что нужной ячейки памяти в кэше не оказалось. Значит, операнд не будет доставлен и эта МО будет выполнена неправильно. Более того, поскольку приостановить конвейер невозможно, все последующие МО будут также выполнены неправильно.
Для исправления подобных ситуаций в архитектуре NetBurst имеется система повторного исполнения МО (англ. replay – переиграть). Она заключается в том, что параллельно с основными очередями планировщиков в процессоре есть резервные очереди системы повторного исполнения, в точности копирующие основные. МО с выхода планировщика попадает в основную очередь и резервную. В резервной очереди она движется параллельно основной. Если МО из основного конвейера выполнена успешно, ее копия в резервной очереди просто уничтожается. Если же к моменту ее исполнения оказывается, что операнд не был доставлен, копия МО повторно направляется в основной конвейер. МО, поступающая на повторное исполнение, имеет более высокий приоритет перед остальными и помещается в конвейере непосредственно после планировщика. Пройдя по цепочке конвейера, она выполняется еще раз. Такое многократное повторное исполнение может происходить десятки раз – до тех пор, пока операнд не будет получен (например, когда он доставляется из оперативной памяти).
Если эта МО оказалась первой в цепочке взаимозависимых команд, то все последующие МО также будут отправлены на повторное исполнение.
Иногда повторное исполнение взаимозависимых МО вызывает взаимоблокировки, приводящие к многократному повторному исполнению больших участков программы. Для исключения подобных ситуаций предусмотрен аварийный выход. После выполнения нескольких десятков циклов повторного исполнения соответствующие наборы МО отправляются в специальный буфер, чтобы освободить конвейер. При этом конвейер заполняется другими командами, а за время их исполнения в кэш данных первого уровня доставляются необходимые для отложенного участка программы операнды.
Наличие системы повторного исполнения – необходимая плата за стремление максимально загрузить работой исполнительные блоки при длинном конвейере. Хотя повторное исполнение и приводит к снижению производительности, тем не менее это позволяет избежать остановки и сброса конвейера, которые вызвали бы еще более серьезные потери производительности процессора.
Технология Hyper Threading
В некоторых процессорах, реализованных на основе микроархитектуры NetBurst, была введена возможность одновременного параллельного выполнения двух программ, или двух разных участков одной программы. Само название Hyper Threading означает "гиперпоточность", т.е. процессор может одновременно выполнять много потоков команд.
Один физический процессор, поддерживающий технологию Hyper Threading, рассматривается операционной системой компьютера как два разных логических процессора. Каждый из них имеет свой набор логических регистров, включая программный счетчик, которые формируются из группы физических регистров процессора, объединенных в регистровом файле. Так как физический процессор NetBurst имеет большой набор исполнительных узлов, работающих параллельно, включая и два работающих на удвоенной частоте быстрых блока ALU, появляется возможность загружать их командами от двух разных фрагментов программ.
Поскольку многие исполнительные узлы в процессоре имеются только в одном экземпляре, то, безусловно, между двумя потоками команд возможно возникновение конфликтов, когда обоим потокам требуется использовать один и тот же исполнительный узел, однако в целом такая работа позволяет более интенсивно их использовать. Конечно, эффективность такой работы зависит от того, из каких команд состоят потоки программ, т.е. насколько редко в процессе исполнения двух потоков будут поступать команды, одновременно требующие один и тот же исполнительный узел.
Рассмотрим преимущества технологии Hyper Threading на примере. Пусть процессор выполняет две программы, которым соответствуют два потока команд – поток А и поток В. Команды потока А загружают исполнительные блоки процессора так, как показано на рис. 5.4, а, а потока В – на рис. 5.4, б. Как видно, в разные такты оба потока используют разные исполнительные блоки процессора. Если процессор не имеет технологии Hyper Threading, то при параллельном выполнении двух потоков он будет поочередно выполнять их команды (рис. 5.4, в). В общей сложности для этого понадобится 10 тактов. Если же процессор реализует технологию Hyper Threading, то для выполнения обоих потоков понадобится только 5 тактов (рис. 5.4, г).
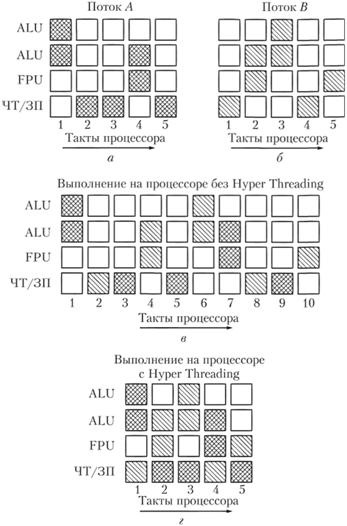
Рис. 5.4. Выполнение двух потоков на процессоре без реализации и с реализацией технологии Hyper Threading:
а – исполнение команд потока А; б – исполнение команд потока В; в – исполнение команд двух потоков без технологии Hyper Threading; г – исполнение команд двух потоков с технологией Hyper Threading