Лекция 6. СЕЗОННАЯ ДЕКОМПОЗИЦИЯ И ТРЕНД-СЕЗОННЫЕ МОДЕЛИ
В результате освоения данной главы студент должен:
знать
• о влиянии сезонности на точность социально-экономического прогнозирования;
• основные понятия, методы и инструменты количественного и качественного анализа по выделению сезонности социально- экономических процессов;
уметь
• выявлять тип сезонности;
• использовать методы выделения сезонности для прогнозирования;
• строить прогнозные модели с учетом сезонности;
• получать достоверные прогнозы социально-экономических процессов с учетом цикличности их динамики;
владеть
• методами и методиками декомпозиции структуры временных рядов;
• методами и методиками прогнозирования тенденций с учетом цикличности социально-экономических явлений;
• информационными технологиями выявления сезонности для адекватного прогнозирования социально-экономических процессов.
Виды сезонности
В некоторых рядах данных детерминированная компонента может состоять не только из некоторой функции (которая может быть описана, например, одной из моделей, рассмотренных нами в предыдущих параграфах), но и из периодической или, как ее еще обычно называют, "сезонной" составляющей. Причем считается, что элементы ряда могут быть объединены:
1) аддитивно: 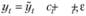 (6.1)
(6.1)
2) мультипликативно: 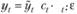 (6.2)
(6.2)
Здесь 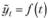 – трендовая компонента; с, – сезонный коэффициент для наблюдения t, повторяющийся каждые $ периодов; s обычно называется лагом сезонности и соответствует числу периодов, через которые происходит повторяемость в ряде данных. Так, если в распоряжении исследователя имеется ряд данных по месячным продажам горных лыж, лаг сезонности будет равен 12: каждый год будут наблюдаться похожие спады и подъемы (например, рост продаж в декабре каждого года).
– трендовая компонента; с, – сезонный коэффициент для наблюдения t, повторяющийся каждые $ периодов; s обычно называется лагом сезонности и соответствует числу периодов, через которые происходит повторяемость в ряде данных. Так, если в распоряжении исследователя имеется ряд данных по месячным продажам горных лыж, лаг сезонности будет равен 12: каждый год будут наблюдаться похожие спады и подъемы (например, рост продаж в декабре каждого года).
Стоит отдельно сказать о трендовой компоненте у,. Во многих источниках она носит название "тренд-циклической компоненты", что указывает на то, что во время декомпозиции сезонного временно́го ряда различные никлы конъюнктуры не отделяются от исходного ряда данных, а считаются входящими в трендовую составляющую. Если у исследователя в распоряжении имеется достаточно большой временно́й ряд обратимого процесса, тогда из такой компоненты можно вычленить циклическую составляющую. Однако стоит признать, что обратимых процессов в экономике крайне мало, а получить большой временно́й ряд часто либо в принципе невозможно, либо крайне затруднительно. Поэтому такое объединение вполне естественно и логично.
Использование модели (6.1) может быть целесообразно в случаях, когда с ростом уровня ряда амплитуда сезонных колебаний не меняется. Если же с ростом уровня ряда амплитуда тоже растет, применяют модель (6.2).
На рис. 6.1 показаны условные ряды данных для обеих тренд- сезонных моделей (ошибки в этих условных примерах отсутствуют).
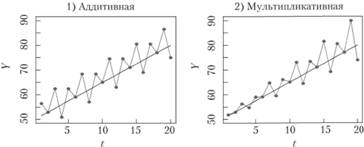
Рис. 6.1. Условные сезонные ряды данных с аддитивной (1) и мультипликативной (2) сезонностью
Как видим, на рис. 6.1 приведена ситуация с квартальной сезонностью и линейной тенденцией к росту. В случае с мультипликативной сезонной составляющей четко видно увеличение амплитуды с ростом значения по тренду.
В модели (6.2), как можно заметить, кроме всего прочего априорно предполагается, что ошибки учитываются мультипликативно, а не аддитивно. Однако данная модель может быть представлена и в аддитивном виде, если мы прологарифмируем ее левую и правую части:
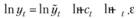 (6.3)
(6.3)
Такое представление позволяет понять, что собой представляет ошибка в модели и как она может быть распределена. Так, если обычно исследователь априорно предполагает, что в модели (6.1) ошибка распределена нормально с нулевым математическим ожиданием и некоторой постоянной дисперсией:
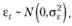 (6.4)
(6.4)
то в модели (6.3) логичным представляется другое априорное предположение: 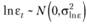
В таком случае сама ошибка 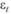 в модели (6.2) будет распределена логнормально с некоторыми математическим ожиданием и постоянной дисперсией:
в модели (6.2) будет распределена логнормально с некоторыми математическим ожиданием и постоянной дисперсией:
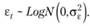 (6.5)
(6.5)
Отметим, что математическое ожидание ошибки в таком случае уже равно не 0 и даже не 1 (что было бы наиболее ожидаемо из равенства:  . Обратим внимание на то, что математическое ожидание в логнормальном распределении будет равно 1 только в случае с крайне малыми значениями дисперсии ошибки. Во всех остальных случаях оно будет меньше 1. Это говорит о том, что в случае с мультипликативной формой модели мы имеем дело со смещенными оценками.
. Обратим внимание на то, что математическое ожидание в логнормальном распределении будет равно 1 только в случае с крайне малыми значениями дисперсии ошибки. Во всех остальных случаях оно будет меньше 1. Это говорит о том, что в случае с мультипликативной формой модели мы имеем дело со смещенными оценками.
Сами ошибки, как это следует из формул (6.1) и (6.2), в этих моделях могут быть найдены но следующим формулам:
1) для аддитивной сезонности: 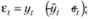 (6.6)
(6.6)
2) для мультипликативной: 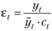 . (6.7)
. (6.7)
Если исследователь неправильно идентифицирует тип сезонности в ряде данных, он получит завышенные ошибки, что в результате скажется на ширине доверительного интервала, который нужно будет построить на их основе.
Одним из критериев для выбора типа модели принято считать норматьность распределения ошибок. Если после построения модели по ряду данных исследователь получил нормально распределенные ошибки, то это указывает на то, что для исходного ряда данных он выбрал наиболее подходящую модель.
Чтобы лучше понять, что собой представляют упомянутые нами компоненты, рассмотрим их на примере ряда № 2568 из базы рядов М3. На рис. 6.2 показан исходный ряд данных, а также его компоненты.
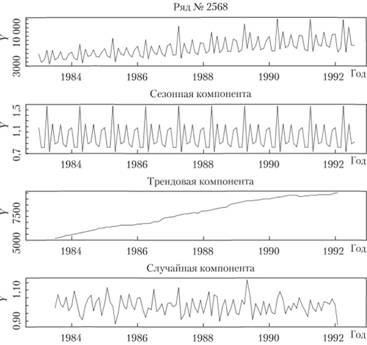
Рис. 6.2. Разложение ряда данных на составляющие (сверху вниз): исходный ряд данных, сезонная компонента, тренд и случайная компонента
Исходный ряд данных представлял собой месячные продажи некоторой продукции. По первому графику виден рост тенденции с одновременным увеличением амплитуды колебаний, поэтому сезонность в данном примере рассматривалась в мультипликативном виде. Второй график демонстрирует динамику сезонной компоненты во времени. Как видим, ее динамика достаточно стабильна и не претерпевает каких-либо серьезных изменений. На третьем графике показана трендовая составляющая. Можно заметить устойчивую тенденцию к росту, которая, однако, периодически то замедляется, то ускоряется. Представленный ряд данных явно имеет эволюционный характер. Последний график представляет собой график мультипликативных ошибок по исходному ряду. Сам по себе он не несет полезной информации и лишь показывает величину тех или иных ошибок в определенные моменты времени. Значительно полезнее для исследователя было бы взглянуть на гистограмму по распределению ошибок (рис. 6.3).
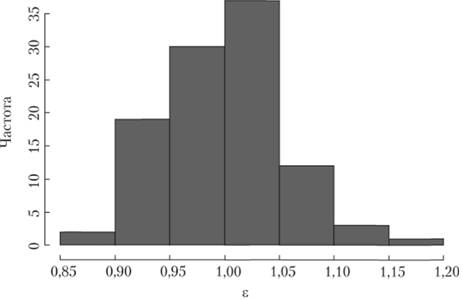
Рис. 6.3. График плотности распределения мультипликативных ошибок по ряду данных № 2568 из базы рядов М3
Как видим, на рис. 6.3 распределение ошибок напоминает логнормальное. Математическое ожидание ряда ошибок оказалось примерно равным 1. Все это косвенно указывает на то, что для исходного ряда данных больше подходит модель с мультипликативной сезонностью.
Если же следовать более формальным процедурам, то нужно провести тест на проверку статистической гипотезы о нормальности распределения логарифмов мультипликативных ошибок (например, тест Шапиро – Уилка). Проведение такого теста дает остаточную вероятность p-value = 0,8879. Это говорит о том, что у нас ни на 5%, ни даже на 10% нет оснований отклонить нулевую гипотезу о нормальности распределения остатков.
Однако если по тому же ряду данных построить модель с аддитивной сезонностью, мы получим ошибки, распределенные следующим образом (рис. 6.4).
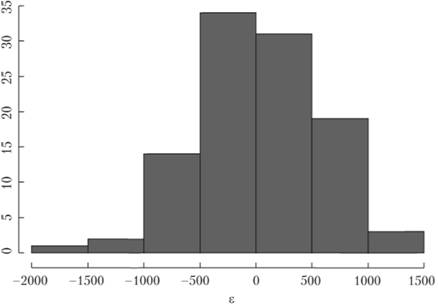
Рис. 6.4. График плотности распределения аддитивных ошибок по ряду данных № 2568 из базы рядов М3
Ошибки на рис. 6.4 также выглядят нормально распределенными. Тест Шапиро – Уилка дает остаточную вероятность p-value = 0,5, что так же, как и в предыдущем случае, говорит о том, что у нас нет оснований отклонить нулевую гипотезу даже на 10%. Получается, что на основе распределения ошибок отдать предпочтение той или иной модели для ряда № 2568 нельзя. Такой результат получен, скорее всего, из-за того, что амплитуда сезонности в ряде данных хоть и растет с увеличением уровня ряда, однако рост этот происходит медленно и незначительно. В таких случаях выбор типа модели сводится к экспертному мнению прогнозиста, который должен решить, что именно будет происходить с сезонностью в будущем.