Код Хаффмана
ЭФФЕКТИВНОЕ КОДИРОВАНИЕ
В настоящее время для сжатия данных применяется специально разработанные эффективные коды. Простейший из них – код Шеннона-Фано, рассматривался в курсе Теория информации.
Методика кодирования Фано не всегда приводит к однозначному построению кода, поскольку при разбиении на подмножества можно сделать больше по вероятности то одно, то другое подмножество. От этого недостатка свободна методика Хаффмана. Она гарантирует однозначное построение кода, наиболее близкого к оптимальному при заданном распределении вероятностей, т.е. обеспечивает наименьшее возможные значения η среднего числа знаков кода, приходящих на 1 кодируемый символ.
Для двоичного кода методика сводится к следующему:
Символы алфавита выписываются в столбец в порядке невозрастания вероятностей. Два последних символа объединяют в один вспомогательный символ, которому приписывают суммарную вероятность. Вероятности символов, не участвующих в объединении, и полученная суммарная вероятность снова располагаются в порядке невозрастания вероятностей в дополнительном столбце таблицы, и два последних символа снова объединяются. При этом, в соответствие с методом «пузырька», в случае, если полученная суммарная вероятность принимает значение, равное уже имеющемуся в таблице вероятностей, то в новом столбце суммарная вероятность располагается сверху (всплывает вверх). Процесс всплытия пузырьков к вершине группы одинаковых вероятностей дает код с уменьшенной дисперсией длины кодовых слов, при том же как без всплытия значений средней длины кодовых слов.
Снижение дисперсии длины кода принимает вероятность переполнения буфера, обеспечивающее сопряжение равномерного поступления входных кодовых символов и выдачи неравномерной кодовой комбинации на выходе кодов Хаффмана. Процесс продолжается до тех пор, пока не получим единственный вспомогательный символ с вероятностью, равной единице. Так строится таблица.
| Знаки сообщения | Вероят-ности | Вспомогательные столбцы | ||||||
| Z1 | 0.16 | 0.22 | 0.22 | 0ю26 | 0.32 | 0.42 | 0.58 | |
| Z2 | 0.20 | 0.20 | 0.20 | 0.22 | 0.26 | 0.32 | 0.42 | |
| Z3 | 0.16 | 0.16 | 0.16 | 0.20 | 0.22 | 0.26 | ||
| Z4 | 0.16 | 0.16 | 0.16 | 0.16 | 0.20 | |||
| Z5 | 0.1 | 0.1 | 0.16 | 0.16 | ||||
| Z6 | 0.1 | 0.1 | 0.1 | |||||
| Z7 | 0.04 | 0.06 | ||||||
| Z8 | 0.02 |
Затем строится кодовое дерево, в процессе которого и осуществляется кодирование. Верхняя точка дерева соответствует 1. Из неё направляются две ветви. С большей вероятностью ветви присваивается 1, с меньшей – 0. Такое последовательное ветвление продолжается до тех пор, пока не доберется до вершины каждой буквы.
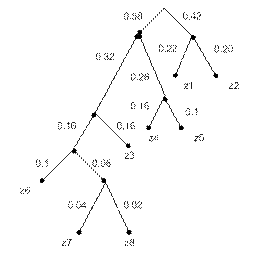
После этого, двигаясь по кодовому дереву сверху вниз, можно записать для каждой буквы соответствующую ей кодовую комбинацию:
Z1 z2 z3 z4 z5 z6 z7 z8
01 00 110 101 100 1111 11101 11100
При кодировании М-ичным кодом процедура остается такой же, только во вспомогательную группу объединяется по m-сообщений.