Случайные процессы и функции [1, 2, 25]
Случайный процесс Х(t) представляет собой функцию, которая отличается тем, что принимаемые ею значения в любые произвольные моменты времени по координате t являются случайными. Строго с теоретических позиций, случайный процесс X(t) следует рассматривать как совокупность временных функций xk(t), имеющих определенную общую статистическую закономерность. При регистрации случайного процесса на определенном временном интервале осуществляется фиксирование единичной реализации xk(t) из бесчисленного числа возможных реализаций процесса X(t). Эта единичная реализация называется выборочной функцией случайного процесса X(t). Примеры выборочных функций модельного случайного процесса X(t) приведены на рис. 17.1.1. В дальнейшем без дополнительных пояснений при рассмотрении различных параметров и характеристик случайных процессов для сопровождающих примеров будем использовать данную модель процесса.

Рис. 17.1.1. Выборочные функции случайного процесса.
С практической точки зрения выборочная функция является результатом отдельного эксперимента, после которого данную реализацию xk(t) можно считать детерминированной функцией. Сам случайный процесс в целом должен анализироваться с позиции бесконечной совокупности таких реализаций, образующих статистический ансамбль. Полной статистической характеристикой такой системы является N-мерная плотность вероятностей р(xn;tn). Однако, как экспериментальное определение N-мерных плотностей вероятностей процессов, так и их использование в математическом анализе представляет значительные математические трудности. Поэтому на практике обычно ограничиваются одно- и двумерной плотностью вероятностей процессов.
Функциональные характеристики случайного процесса.
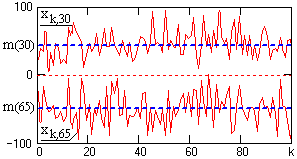 Рис. 17.1.2. Сечения случайного процесса X(t).
Рис. 17.1.2. Сечения случайного процесса X(t).
|
Допустим, что случайный процесс X(t) задан ансамблем реализаций {x1(t), x2(t),… xk(t),…}. В произвольный момент времени t1 зафиксируем зафиксируем значения всех реализаций {x1(t1), x2(t1),… xk(t1),…}. Совокупность этих значений представляет собой случайную величину X(t1) и является одномерным сечением случайного процесса X(t). Примеры сечений по 100 выборкам случайного процесса X(t) в точках t1 и t2 (рис. 17.1.1) приведены на рис. 17.1.2.
Одномерная функция распределения вероятностей (x,ti) определяет вероятность того, что в момент времени ti значение случайной величины X(ti) не превысит значения x:
F(x,ti) = P{X(ti)≤x}.
Очевидно, что в диапазоне значений вероятностей от 0 до 1 функция F(x,t) является неубывающей с предельными значениями F(-¥,t)=0 и F(¥,t)=1. При известной функции F(x,t) вероятность того, что значение X(ti) в выборках будет попадать в определенный интервал значений [a, b] будет определяться выражением:
P{a<X(ti)≤b} = F(b,ti) – F(a,ti).
Одномерная плотность вероятностей p(x,t) случайного процесса Х(t) характеризует распределение вероятностей реализации случайной величины Х(ti) в произвольный момент времени ti. Она представляет собой производную от функции распределения вероятностей:
p(x,ti) = dF(x,ti)/dx.
Моменты времени ti являются сечениями случайного процесса X(t) по пространству возможных состояний и плотность вероятностей p(x,ti) представляет собой плотность вероятностей случайных величин X(ti) данных сечений. Произведение p(x,ti)·dx равно вероятности реализации случайной величины X(ti) в бесконечно малом интервале dx в окрестности значения x, откуда следует, что плотность вероятностей также является неотрицательной величиной.

Рис. 17.1.3. Распределение вероятностей и плотность вероятностей сечения случайного процесса
На рис. 17.1.3 приведены примеры распределения вероятностей и плотности вероятностей сечения случайного процесса X(t) в точке t1 (рис. 17.1.1). Функции вероятностей определены по N=1000 выборок дискретной модели случайного процесса и сопоставлены с теоретическими распределениями при N ® ¥.
При известной функции плотности вероятностей вероятность реализации значения X(ti) в произвольном интервале значений [a, b] вычисляется по формуле:
P(a<X(ti)≤b) =  p(x,ti) dx.
p(x,ti) dx.
Функция плотности вероятностей должна быть нормирована к 1, т.к. случайная величина обязана принимать какое-либо значение из числа возможных, образующих полное пространство случайных величин:
 p(x,ti) dx =1.
p(x,ti) dx =1.
По известной плотности распределения вычисляется и функция распределения вероятностей:
F(x,ti) =  p(x,ti) dx.
p(x,ti) dx.
Случайные процессы и их функции характеризуются неслучайными функциями математического ожидания (среднего значения), дисперсии и корреляции:
Математическое ожидание(mean value) представляет собой статистическое усреднение случайной величины X(ti), под которым понимают усреднение по ансамблю реализаций в каком либо фиксированном сечении ti случайного процесса. Соответственно, функция математического ожидания является теоретической оценкой среднего взвешенного значения случайного процесса по временной оси:
mx(t) º M{Х(t)}º  = x p(x;t) dx, (17.1.1)
= x p(x;t) dx, (17.1.1)
Математическое ожидание mx(t) представляет собой неслучайную составляющую случайного процесса X(t). На рис. 17.1.1. и 17.1.2 неслучайные составляющие m(t) модели случайного процесса X(t) выделены пунктиром и соответствуют выборкам N ® ¥.
Функция дисперсии (variance) случайного процесса является теоретической оценкой среднего взвешенного значения разности Х(t)-mx(t), которая называется флюктуационной частью процесса:
Dx(t) = M{[Х(t)-mx(t)]2} = M{X2(t)} - mx2(t) = [xo(t)]2 p(x;t) dx, (17.1.2)
xo(t) = x(t)-mx(t).
Функция среднего квадратического отклонения (standard deviation) служит амплитудной мерой разброса значений случайного процесса по временной оси относительно математического ожидания процесса:
sx(t) =  . (17.1.3)
. (17.1.3)
 Рис. 17.1.4.
Рис. 17.1.4.
|
Учитывая последнее выражение, дисперсия случайной величины обычно обозначается индексом sx2.
На рис. 17.1.4 приведен пример флюктуационной составляющей процесса X(t) (рис. 17.1.1) в одной из реализаций в сопоставлении со средним квадратическим отклонением ±s случайных величин от математического ожидания m(t).
Корреляционные функции случайных процессов. Одномерные законы плотности распределения вероятностей случайных процессов не несут каких-либо характеристик связи между значениями случайных величин для различных значений аргументов.
Двумерная плотность вероятностей p(x1,x2; t1,t2) определяет вероятность совместной реализации значений случайных величин Х(t1) и Х(t2) в произвольные моменты времени t1 и t2 и в какой-то мере уже позволяет оценивать динамику развития процесса. Двумерная плотность вероятностей описывает двумерную случайную величину {X(ti), X(tj)} в виде функции вероятности реализации случайной величины X(ti) в бесконечно малом интервале dxi в окрестностях xi в момент времени ti при условии, что в момент времени tj значение X(tj) будет реализовано в бесконечно малом интервале dxj в окрестностях xj:
p(xi,xj; ti,tj) dxi dxj = P{|X(ti-xi|≤dxi/2, |X(tj-xj|≤dxj/2}.
Характеристикой динамики изменения двумерной случайной величины {X(ti), X(tj)} является корреляционная функция, которая описывает случайный процесс в целом:
RX(ti,tj) = M{X(t1) X(t2)}.
Корреляционная функция представляет собой статистически усредненное произведение значений случайного процесса X(t) в моменты времени ti и tj по всем значениям временных осей ti и tj, а следовательно тоже является двумерной функцией. В терминах теории вероятностей корреляционная функция является вторым начальным моментом случайного процесса.
На рис. 17.1.5 приведены примеры реализаций двух случайных процессов, которые характеризуются одной и той же функцией математического ожидания и дисперсии.
 Рис. 17.1.5. Рис. 17.1.5.
|
На рисунке видно, что хотя пространство состояний обоих процессов практически одно и то же, динамика развития процессов в реализациях существенно различается. Единичные реализации коррелированных процессов в произвольный момент времени могут быть такими же случайными, как и некоррелированных, а в пределе, во всех сечениях оба процесса могут иметь один и тот же закон распределения случайных величин. Однако динамика развития по координате t (или любой другой независимой переменной) единичной реализации коррелированного процесса по сравнению с некоррелированным является более плавной, а, следовательно, в коррелированном процессе имеется определенная связь между последовательными значениями случайных величин. Оценка степени статистической зависимости мгновенных значений какого-либо процесса Х(t) в произвольные моменты времени t1 и t2 и производится функцией корреляции. По всему пространству значений случайного процесса X(t) корреляционная функция определяется выражением:
RХ(ti,tj) = x(ti)x(tj) p(xi,tj; xi,tj) dxi dxj, (17.1.4)

Рис. 17.1.6. Двумерная плотность вероятностей и корреляционная функция процесса X(t).
На рис. 17.1.6 приведена форма модельного случайного процесса X(t) в одной выборке со значительной и изменяющейся неслучайной составляющей. Модель задана на интервале 0-Т (Т=100) в дискретной форме с шагом Dt=1. Корреляционная функция вычислена по заданной плотности вероятностей модели
При анализе случайных процессов второй момент времени tj удобно задавать величиной сдвига t относительно первого момента, который при этом может быть задан в виде координатной переменной:
RХ(t,t+t) = M{Х(t)Х(t+t)}. (17.1.4')
Функция, задаваемая этим выражением, обычно называется автокорреляционной функцией случайного процесса.
Ковариационные функции. Частным случаем корреляционной функции является функция автоковариации (ФАК), которая широко используется при анализе сигналов. Она представляет собой статистически усредненное произведение значений центрированной случайной функции X(t)-mx(t) в моменты времени ti и tj и характеризует флюктуационную составляющую процесса:
KХ(ti,tj) = (x(ti)-mx(ti)) (x(tj)-mx(tj)) p(xi,tj; xi,tj) dxi dxj, (17.1.5)
В терминах теории вероятностей ковариационная функция является вторым центральным моментом случайного процесса. Для центрированных случайных процессов ФАК тождественна функции корреляции. При произвольных значениях mx ковариационные и корреляционные функции связаны соотношением:
KX(t,t+t) = RX(t,t+t) - mx2(t).
Нормированная функция автоковариации (функция корреляционных коэффициентов):
rХ(t,t+t) = KХ(t,t+t)/[s(t)s(t+t)]. (17.1.6)
При t = 0 значение rХ равно 1, а ФАК вырождается в дисперсию случайного процесса:
KХ(t) = DХ(t).
Отсюда следует, что для случайных процессов и функций основными характеристиками являются функции математического ожидания и корреляции (ковариации). Особой необходимости в отдельной функции дисперсии не имеется.


Рис. 17.1.7. Реализации и ковариационные функции случайных процессов.
Примеры реализаций двух различных случайных процессов и их нормированных ковариационных функций приведены на рис. 17.1.7.
Свойства функций автоковариации и автокорреляции.
1. Максимум функций наблюдается при t = 0. Это очевидно, т.к. при t = 0 вычисляется степень связи отсчетов с собой же, которая не может быть меньше связи разных отсчетов. Значение максимума функции корреляции равно средней мощности сигнала.
2. Функции автокорреляции и автоковариации являются четными: RX(t) = RX(-t). Последнее также очевидно: X(t)X(t+t) = X(t-t)X(t) при t = t-t. Говоря иначе, моменты двух случайных величин X(t1) и X(t2) не зависят от последовательности, в которой эти величины рассматриваются, и соответственно симметричны относительно своих аргументов: Rx(t1,t2) = Rx(t2,t1), равно как и Kx(t1,t2) = Kx(t2,t1).
3. При t Þ ¥ значения ФАК для сигналов, конечных по энергии, стремятся к нулю, что прямо следует из физического смысла ФАК. Это позволяет ограничивать длину ФАК определенным максимальным значением tmax - радиусом корреляции, за пределами которого отсчеты можно считать независимыми. Интегральной характеристикой времени корреляции случайных величин обычно считают эффективный интервал корреляции, определяемый по формуле:
Tk =2  |rx(t)| dt º (2/Kx(0) |Kx(t)| dt. (17.1.7)
|rx(t)| dt º (2/Kx(0) |Kx(t)| dt. (17.1.7)
Отсчеты (сечения) случайных функций, отстоящие друг от друга на расстояние большее Tk, при инженерных расчетах считают некоррелированными.
Заметим, что для некоррелированных процессов при t Þ ¥ значение Tk стремится к 2, что несколько противоречит физическому смыслу радиуса корреляции, который в этом случае должен был бы стремиться к 1. С учетом последнего эффективный интервал корреляции целесообразно определять по формуле:
Tk =2 |rx(t)| dt - 1 º (2/Kx(0) |Kx(t)| dt - 1. (17.1.7')
4. Если к случайной функции X(t) прибавить неслучайную функцию f(t), то ковариационная функция не изменяется.
Обозначим новую случайную функцию как Y(t)=X(t)+f(t). Функция математического ожидания новой величины:  =
=  + f(t). Отсюда следует, что Y(t) - = X(t) - , и соответственно Ky(t1,t2) = Kx(t1,t2).
+ f(t). Отсюда следует, что Y(t) - = X(t) - , и соответственно Ky(t1,t2) = Kx(t1,t2).
5. Если случайную функцию X(t) умножить на неслучайную функцию f(t), то ее корреляционная функция Rx(t1,t2) умножится на f(t1)×f(t2). Обоснование данного свойства проводится по методике, аналогичной предыдущему пункту.
6. При умножении функции случайного процесса на постоянное значение С значения ФАК увеличиваются в С2 раз.
Взаимные моменты случайных процессов второго порядка дают возможность оценить совместные свойства двух случайных процессов X(t) и Y(t) путем анализа произвольной пары выборочных функций xk(t) и yk(t).
Мера связи между двумя случайными процессами X(t) и Y(t) также устанавливается корреляционными функциями, а именно - функциями взаимной корреляции и взаимной ковариации. В общем случае, для произвольных фиксированных моментов времени t1 = t и t2 = t+t:
RXY(t,t+t) = M{(X(t)(Y(t+t)}. (17.1.8)
KXY(t,t+t) = M{(X(t)-mx(t))(Y(t+t)-my(t+t))}. (17.1.9)
Взаимные функции являются произвольными функциями (не обладают свойствами четности или нечетности), и удовлетворяют следующим соотношениям:
Rxy(-t) = Ryx(t), (17.1.10)
|Rxy(t)|2 £ Rx(0)Ry(0).
Если один из процессов центрированный, то имеет место Rxy(t) = Kxy(t).
Нормированная взаимная ковариационная функция (коэффициент корреляции двух процессов), которая характеризует степень линейной зависимости между случайными процессами при данном сдвиге t одного процесса по отношению ко второму, определяется выражением:
rxy(t) = Kxy(t)/(sxsy). (17.1.11)
Статистическая независимость случайных процессовопределяет отсутствие связи между значениями двух случайных величин X и Y. Это означает, что плотность вероятности одной случайной величины не зависит от того, какие значения принимает вторая случайная величина. Двумерная плотность вероятностей при этом должна представлять собой произведения одномерных плотностей вероятностей этих двух величин:
p(x,y) = p(x) p(y).
Это условие является обязательным условием статистической независимости случайных величин. В противном случае между случайными величинами может существовать определенная статистическая связь. Как линейная, так и нелинейная. Мерой линейной статистической связи является коэффициент корреляции:
rxy = [M{X·Y} – M{X)·M{Y}]/  .
.
Значений rxy могут изменяться в пределах от -1 до +1. В частном случае, если случайные величины связаны линейным соотношением x=ay+b, коэффициент корреляции равен ±1 в зависимости от знака константы а. Случайные величины некоррелированны при rxy=0, при этом из выражения для rxy следует:
M{X·Y} = M{X)·M{Y}.
Из статистической независимости величин следует их некоррелированность. Обратное не очевидно. Так, например, случайные величины x=cos j и y=sin j, где j - случайная величина с равномерным распределением в интервале 0…2p, имеют нулевой коэффициент корреляции, и вместе с тем их зависимость очевидна.
Классификация случайных процессов. Случайные процессы различают по степени однородности их протекания во времени (по аргументу).
Нестационарные процессы. В общем случае значения функций математического ожидания, дисперсии и корреляции могут быть зависимыми от момента времени t, т.е. изменяться во времени. Такие процессы составляют класс нестационарных процессов.
Стационарные процессы. Процесс называют стационарным, если плотность вероятностей процесса не зависит от начала отсчета времени и если на интервале его существования выполняются условия постоянства математического ожидания и дисперсии, а корреляционная функция является функцией только разности аргументов t = t2-t1, т.e.:
mХ(t1) = mХ(t2) = mХ = const, (17.1.12)
DХ(t1) = DХ(t2) = DХ = const,
RХ(t1,t1+t) º Rx(t2-t,t2) = RХ(t) º RХ(-t),
rx(t) = Rx(t)/Dx, rx(0) = 1, |rx(t)| ≤ 1, rx(-t) = rx(t).
Последние выражения свидетельствует о четности корреляционной (а равно и ковариационной) функции и функции корреляционных коэффициентов. Из него вытекает также еще одно свойство смешанных моментов стационарных процессов:
|Rx(t)| £ Rx(0), |Kx(t)| £ Kx(0) º Dx.
Чем медленнее по мере увеличения значений t убывают функции Rx(t) и rx(t), тем больше эффективный интервал корреляции случайного процесса, и тем медленнее изменяются во времени его реализации.
Среди стационарных процессов выделяют строго стационарные процессы, для которых постоянны во времени не только математическое ожидание, дисперсия и корреляция, но и все остальные моменты высших порядков (в частности, асимметрия и эксцесс).
Стационарные случайные процессы наиболее часто встречаются при решении физических и технических задач. Теория стационарных случайных функций разработана наиболее полно и для ее использования обычно достаточно определения стационарности в широком смысле: случайная функция считается стационарной, если ее математическое ожидание постоянно, а корреляционная функция зависит только от одного аргумента. Случайные процессы, удовлетворяющие условиям стационарности на ограниченных, интересующих нас интервалах, также обычно относят к числу стационарных в широком смысле и называют квазистационарными.
Эргодические процессы. Строго корректно характеристики случайных процессов оцениваются путем усреднения по ансамблю реализаций в определенные моменты времени (по сечениям процессов). Но большинство стационарных случайных процессов обладает эргодическим свойством. Сущность его заключается в том, что по одной достаточно длинной реализации процесса можно судить о всех его статистических свойствах так же, как по любому количеству реализаций. Другими словами, закон распределения случайных величин в таком процессе может быть одним и тем же как по сечению для ансамбля реализаций, так и по координате развития. Такие процессы получили название эргодических (ergodic). Для эргодических процессов имеет место:
mX(t) = M{x(t)} = 
 x(t) dt, (17.1.13)
x(t) dt, (17.1.13)
DХ(t) = M{x(t) - mХ(t)]2} = (x(t) - mХ(t))2 dt, (17.1.14)
RХ(t) = M{x(t)x(t+t)} = x(t)x(t+t) dt. (17.1.15)
Эргодичность является очень важным свойством случайных стационарных, и только стационарных процессов. Математическое ожидание эргодического случайного процесса равно постоянной составляющей любой его реализации, а дисперсия является мощностью его флюктуационной составляющей. Так как определение функций производится по ограниченным статистическим данным одной реализации и является только определенным приближением к соответствующим фактическим функциям процессов, целесообразно называть эти функции статистическими. Заметим, что, как это следует из (17.1.15), вычисление корреляционной функции подобно свертке (с делением на интервал реализации) и может записываться символически:
RХ(t) = (1/T) x(t) * x(t+t).
Свойства эргодичности могут проявляться только по отношению к двум первым моментам случайного процесса, что вполне достаточно для использования соответствующих методик исследования процессов. Практическая проверка эргодичности процесса обычно производится проверкой выполнения условия Слуцкого:
K(t) dt = 0. (17.1.16)
Если ковариационная функция процесса стремится к нулю при возрастании значения аргумента (t), то процесс относится к числу эргодических, по крайней мере относительно моментов первого и второго порядков.
Пример.Случайная функция задана выражением Z(t)=X(t)+Y, где X(t) - стационарная эргодичная функция, Y- случайная величина, некоррелированная с X(t). Эргодична ли функция Z(t)?
mz(t) = mz(x)+my, Kz(t) = Kx(t)+Dy.
Функция Z(t) стационарна, но не эргодична, так как при t Þ ¥ имеет место Kz(t) Þ Dy.