Банк паспортных данных пшеницы (фрагмент)
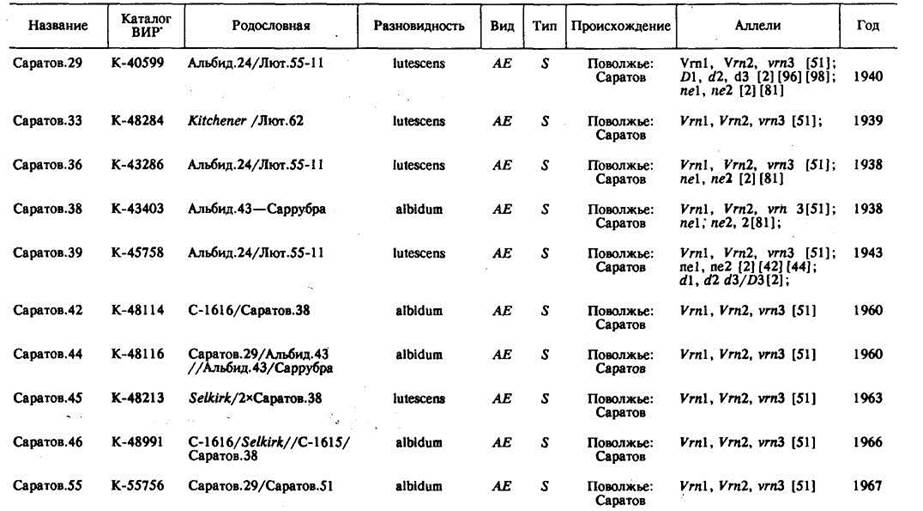
Записьоб образце состоит из названия сорта или линии, номера по каталогу (ВИР), родословной (см. раздел 7.4) или географического происхождения генотипа,признаков (идентифицированных аллелей) и некоторых дополнительных сведений (вид, разновидность, тип развития, год районирования и др.). В табл. 76 приведен фрагмент банка паспортных данных пшеницы, откуда видно, что за исключением вида и типа развития вся информация о сортах представлена в естественном виде. Вид и тип (образ жизни) указаны сокращениями АЕ (Tr.aestivum)— мягкая пшеница и S (Spring)— яровая. Родословные сортов закодированы в специальном виде, удобном для компьютерного представления [4].
Для многих видов культурных растений разработаны единые международные символы генов. Например, по Р. Мак-Интошу, у пшеницы гены обозначают одной или тремя буквами и арабскими цифрами. Для обозначения генов чаще всего используют начальные буквы из названий генов (признаков) на латинском или английском языке. Доминантные аллели принято писать с заглавной буквы, рецессивные — со строчной. Например, гены низкорослости (Reduced height) обозначают символом Rht; реакции на фотопериод (Response to photoperiod) — Ppd. Обозначения всех локализованных генов есть в каталоге. Запись в каталоге содержит названия признака, символ гена, локализацию (хромосома, плечо) и название сорта-эталона, несущего данный аллель. Такая стандартизация записи паспортных данных позволяет упростить ведение БПД и обмен между разными лабораториями.
Пакет программ, обслуживающих БПД, предоставляет следующие возможности:
а — ответы на простые информационные запросы— вывод упорядоченного (по алфавиту) списка названий заданых сортов; выдача полной информации по этому набору сортов (на печать выдаются родословные, происхождение и идентифицированные аллели заданного набора сортов); подсчет общего числа имеющихся в БПД сортов и линий;
б — выборки или группировки— вывести сорта, имеющие в родословной один и/или несколько заданных сортов, или сорта заданного происхождения, или сорта с заданными аллелями. Возможны три варианта: вывод полной информации по сортам, только названий сортов, подсчет общего числа таких сортов. Можно выбрать сорта с заданной комбинацией реквизитов. Эта функция позволяет осуществить многоаспектный поиск сортов и форм, например, с заданными аллелями и происхождением. Данная функция может быть использована для выбора наиболее подходящих сортов-доноров нужного признака;
в — анализ родословных:
- развертывание родословных, т.е. автоматически подставляются родословные родителей и прародителей заданного сорта до тех пор, пока не встретятся предки с неизвестной генеалогией (местные или стародавние сорта);
- вывести дендрограф (дендрограмму)— графическое изображение развернутой родословной вплоть до предков или сортов с неизвестными родословными; подсчитать ожидаемые доли прародителейв геноме заданного сорта;
- подсчитать матрицу коэффициентов родства (см. раздел 7.4) для заданного набора сортов.
БПД может быть использован в селекции для планирования скрещиваний (определение дивергентности родителей, выбор сортов-доноров, нахождение вероятного генотипа сорта, вовлекаемого в скрещивания). Он постоянно пополняется информацией, взятой из каталогов, монографий, научных публикаций и дает возможность решения целого ряда задач:
- разработка новых подходов к описанию сортообразцов и использованию их в селекции для более целенаправленного подбора родительских пар и оценки материала;
- выявление закономерностей географического распространения идентифицированных аллелей и экологической характеристики ключевых генов с целью подбора наиболее ценных аллелей и их сочетаний для конкретной агроклиматической зоны;
- поиск генетических маркеров адаптивных систем, в частности, выявление генетических систем жаро- и засухоустойчивости.
За рубежом более 10 лет создаются и обновляются международные компьютерные БД по признакам, геномам, гендонорам, коллекциям и т.п. различных видов сельскохозяйственных растений. Всего их более 100. Большинство БД представлено в международной компьютерной сети InterNet. Некоторые из них: GrainGenes – по зерновым культурам, MaizeDB – по кукурузе, RiceGenes – по рису, SolGenes – по семейству Solanaceae. В InterNet доступны различные сайты, где объединены БД различных направлений биологии, генетики, сельского хозяйства и т.д. В частности, сайт «UK CropNet» (адрес http://ukcrop.net/) позволяет проводить поиск в нескольких БД, содержащих сведения о результатах селекционно-генетических исследований различных сельскохозяйственных культур.
В качестве примера рассмотрим возможности одного из этих БД - SolGenes, объединяющего биологическую и, прежде всего, генетическую информацию из научных журналов за последние 50 лет по основным культурам семейства пасленовых. Ниже перечислены некоторые разделы БД (всего их больше 30):
2 point data – 304 записи о парном расположении локусов на отдельных хромосомах различных видов. Они, в частности, связывают положение морфологических маркеров с молекулярными.
Allele – аббревиатуры 441 аллеля, литературные с указанием коллекций, где они имеются.
Autor – 11032 фамилии авторов статей, ссылки на которые есть в БД.
Collection – названия, координаты и фамилии кураторов 10 основных коллекции сортов, мутантных, диких и других форм семейства Solanaceae.
Colleague – 1730 фамилий специалистов по генетике и селекции пасленовых с их координатами.
DNA – 4785 описаний нуклеотидных последовательностей ДНК с указанием расположения в геноме вида. Информация представлена в графическом виде
Environment – описание экспериментов (методика, изученные признаки, литературные ссылки и пр.) с образцами пасленовых, проведенные в 15 научных центрах.
Gene product – описание 1553 клеточных продуктов, которые кодируются конкретными участками ДНК, и определяемых типом, размером кодирующей области и т.п.
Germplasm – описание 8759 образцов пасленовых с указанием коллекций (название, вид, идентифицированные гены образца и пр.).
Image – 322 изображения (фотографии, схемы, рисунки) – результатов генетических и селекционных экспериментов с пасленовыми. Пример на рис. 42.
(РИСУНОК 42)
Introgressed region – 50 карт хромосом томата с указанием положения локусов количественных признаков (QTL – см. раздел 4.1) и зондами для идентификации.
Journal – название 556 научных журналов с информацией, использованной в БД.
Keyword – 5400 ключевых слов и словосочетаний из статей, использованных в БД.
Locus – сведения о 6317 локусах (AFLP, RFLP, морфологических и др.) со ссылками на карты.
Map – 290 генетических и физических (молекулярных) карт различных культур с обозначениями и расстояниями между локусами и литературными ссылками для каждого из них.
MultiMap –40 схем–сопоставлений карт хромосом для двух и более видов с указанием гомологичных участков.
Paper – сведения (включая аннотации) о 7138 статях, использованных в БД.
Pathology – сведения о 23 болезнях, вирусах и других патогенах со ссылками на информацию о генах устойчивости.
Species – краткая информация о 225 видах пасленовых.
Trait – перечислены 70 изученных признаков с указанием видов.
Все разделы имеют перекрестные ссылки, позволяющие найти всю сопряженную информацию о любом объекте, упомянутом в БД SolGenes. Для этого существуют различные способы поиска информации. Наиболее простой – прямой просмотр в открывающихся окнах с помощью компьютерной мыши. Более сложные - с помощью специальных языков запросов. В основе БД программное обеспечение ACEBD (http://www.acdbe.org/)
Создание подобного БД, например, на основе информации о новой коллекции научного учреждения, это сложный, длительный и дорогостоящий процесс. Он требует участия не только селекционеров и генетиков, но также высококвалифицированных специалистов по разработке БД. В связи с этим на кафедре генетики МСХА предложен новый «кумулятивный» подход к развитию информационного компьютерного обеспечения научных исследований на примере работы с генетической коллекцией томата. Вместо разработки БД предлагается создание и встраивание в давно существующие и постоянно пополняемые БД минимального информационного «фильтра» - упрощенной базы данных о новой коллекции. За счет доступного в InterNet программного обеспечения, например ACEBD, и данных из InterNet БД по той же культуре информацию о новой коллекции можно объединить с обширными сведениями о ее генах, признаках и т.п. В результате возникает возможность автоматизированного получения из объединенного БД сечений информации, сопряженной с данными об образцах новой коллекции. Перед встраиванием “фильтра” в БД последний целиком переносится из InterNet в компьютер пользователя.
Используя этот принцип, была создана упрощенная компьютерная база данных Mutant, содержащая минимальные сведения об 372 образцах идентифицированной маркерной коллекции томата кафедры генетики МСХА. Эта база данных встроена и объединена с InterNet БД SolGenes.
14.2. Подсистема регистрации и документации экспериментального материала
Подсистема регистрации и документации, входящая в систему компьютерного сервиса, представляет собой совокупность экспериментальных данных, хранящихся на магнитных дисках компьютера, и набор прикладных программ обработки этих данных. По существу такая подсистема является БД, который может содержаться информацию по многим культурам (озимая и яровая, мягкая и твердая пшеницы, кукуруза, просо и т.д.) и обслуживать все лаборатории научного центра, т.е. быть интегрированным.
БД хранит данные, получаемые в процессе селекционно-генетических исследований определенного научного центра. Сюда входит информация о характеристиках образцов из коллекций, скрещиваниях, испытании и отборах в гибридных популяциях, результатах изучения отборов (линий) в селекционном и контрольном питомниках, предварительном и конкурсном испытаниях. Информационное содержание такой базы, или концептуальная модель, приведено на рис. 43. Например, метод педигри требует детального изучения семей и такой формы записи данных, которая позволяет прослеживать взаимосвязь родителей и потомков. Здесь оказываются весьма полезными компьютеры, которые способны хранить и быстро перерабатывать огромные массивы информации.
(РИСУНОК 43)
В некоторых селекционных программах США на компьютере осуществляют автоматическое продвижение (т.е. дополнение) родословных для каждого цикла скрещивания и отбора. Компьютеры также широко используют в западных селекционных учреждениях для планирования полевых и лабораторных опытов, печати полевых журналов, деляночных этикеток, записи, хранения, интерпретации данных.
Например, подсистема регистрации и документации селекционного материала, используемая в программе селекции картофеля Фредериктонской опытной станции (Канада), предназначена для подбора родителей и выбора лучших селекционных номеров. Система позволяет хранить информацию о селекционных образцах за неограниченное число лет, пополнять и корректировать имеющиеся данные, выдавать родословные, проводить поиск и выдачу упорядоченного списка образцов, удовлетворяющих выбранному критерию по заданному числу признаков (их может быть более 40) количественных и качественных, измерявшихся в течение четырех лет. Критерий отбора может быть основан на заданной величине признака, средней стандартного сорта, средней отбираемой части популяции. В системе реализован метод селекционных индексов и другие методы отбора по комплексу признаков. Кроме того, система включает пакет программ для статистической обработки данных экспериментов различными методами .
 Интегрированный БД, включающий информацию об изучении 160 сельскохозяйственных культур на всех государственных сортоиспытательных участках, создан в Госкомиссии РФ по испытанию и охране селекционных достижений. БД содержит данные испытаний, начиная с 1982 г., по урожайности, качеству продукции, устойчивости к болезням, вредителям и другим неблагоприятным факторам — всего около 100 показателей. БД позволяет сравнивать изучаемые сортообразцы со стандартом или лучшим сортом (гибридом), делать всевозможные выборки в разрезе культур, лет испытания, хозяйственных признаков. Он содержит паспортные данные об изучаемом материале, учреждениях-оригинаторах и является мощной информационно-справочной системой.
Интегрированный БД, включающий информацию об изучении 160 сельскохозяйственных культур на всех государственных сортоиспытательных участках, создан в Госкомиссии РФ по испытанию и охране селекционных достижений. БД содержит данные испытаний, начиная с 1982 г., по урожайности, качеству продукции, устойчивости к болезням, вредителям и другим неблагоприятным факторам — всего около 100 показателей. БД позволяет сравнивать изучаемые сортообразцы со стандартом или лучшим сортом (гибридом), делать всевозможные выборки в разрезе культур, лет испытания, хозяйственных признаков. Он содержит паспортные данные об изучаемом материале, учреждениях-оригинаторах и является мощной информационно-справочной системой.
На основе коллекций ВНИИ растениеводства им. Н.И. Вавилова создан интегрированный БД генетических ресурсов, который включает данные о морфологии, происхождении и хозяйственных признаках по десяткам тысяч образцов для каждой из сельскохозяйственных культур.
14.3. Прикладные программы анализа данных
Кроме отдельных компьютерных программ, реализующих конкретные методы анализа экспериментальных или модельных данных, в последние десятилетия созданы пакеты программ, относящиеся к разным предметным областям. Для компьютерного сервиса селекционно-генетических исследований растений особый интерес представляют пакеты генетико-популяционных, биометрико-генетических и селекционно-ориентированных программ.
В частности, сайт «Phylogeny programs» содержит информацию о 217 пакетов и отдельных программ по популяционной и эволюционной генетике, биоинформатике и пр. (http://evolution.genetics.washington.edu/phylip/software.html) Среди них пакет ARLEQUIN, в котором реализован широкий спектр популяционно-генетических методов. Документация этого пакета доступна по адресу http://acasun1.unige.ch/arlequin/.
В ряде НИИ генетического, сельскохозяйственного и биологического профиля России установлен пакет AGROS, разработанный в Твери С.П.Мартыновым. Ориентированный на специфику селекционно-генетических исследований, пакет AGROS включает в себя большое число программ, охватывающих традиционные методы прикладной статистики, а также ряд биометрико-генетических программ, специализированных для обработки результатов селекционно-генетических экспериментов в растениеводстве. Пакет AGROS функционирует в среде MS DOS, выполнен также его перенос в операционную систему Windows 95/98/NT. Такой вариант пакета получил название BIOGEN.
Все программы представляют собой полностью самостоятельные модули, поэтому возможно формирование специализированных комплексов, исходя из специфики экспериментальной работы. Помимо стандартных статистических методов, используемых для обработки селекционно-генетических экспериментов (сортоиспытание с частым контролем, коэффициент наследуемости, кросс-корреляции «родители-потомки» и т.п.) в пакете AGROS имеются реализации большинства биометрико-генетических методов, изложенных в учебнике:
- метод Педерсона,
- евклидово расстояние,
- двукомпонентный метод планирования скрещиваний,
- метод скользящей средней,
- анализ диаллельных скрещиваний по Гриффингу, Хейману, Савченко,
- анализ расщеплений по c2,
- проверка сопряженности качественных признаков,
- дисперсионный анализ качественных признаков,
- построение селекционных индексов и др.
В институте генетики и цитологии Национальной академии наук Беларуси созданы пакеты прикладных программ РИШОН и АБ-СТАТ для планирования и статистического анализа биологических, генетических и селекционных экспериментов. В пакет входят более 60 программ по различным методам анализа:
- традиционные статистические методы параметрической и непараметрической статистики, в т.ч. многомерные и многофакторные;
- генетические методы диаллельного анализа, оценки стабильности генотипов, коэффициентов путей;
- селекционные блок программ для планирования скрещиваний, оценки образцов по комплексу признаков, учета пестроты почвенного плодородия и др.
Имитационное моделирование. Как уже отмечалось во введении, под математической моделью понимают приближенное математическое описание процесса или явления. Имитационное моделирование селекционно-генетических экспериментов включает упрощенное воспроизведение в компьютере этого сложного процесса с последующим анализом множества вариантов его проведения, задаваемых исследователем. В основе имитационной модели лежит описание отдельных этапов и всего процесса языком, воспринимаемым компьютером. Адекватность математической модели определяется тем, что она опирается на весь имеющийся опыт — как экспериментальные данные, так и теоретические представления. Тем не менее, компьютерный эксперимент может не учесть ряда неизвестных исследователю факторов. Поэтому обязательное условие вычислительного имитационного эксперимента — сопоставление получаемых результатов с практикой и в случае необходимости уточнение модели.
Важно отметить, что в реальном эксперименте изучают не объект или процесс в его чистом виде, а весьма запутанное и косвенное проявление этого объекта или процесса. В компьютерном имитационном эксперименте можно оценивать влияние на конечный результат заданных характеристик изучаемого процесса. В полевом эксперименте механизмы такого воздействия могут быть не ясны. Например, в реальной ситуации часто неизвестно, по каким локусам различаются родительские формы.
В компьютерной же модели можно ввести практически любой генетический контроль селекционного признака (число локусов, число аллелей в локусе, эффекты генов, сцепление). Модель опирается на предшествующий опыт, т.е. на частную генетику конкретной сельскохозяйственной культуры. При недостатке информации о наследовании признака моделирование позволяет анализировать различные варианты генетической изменчивости признака. В имитационной модели должно быть предусмотрена возможность задания благоприятных или неблагоприятных аллелей в каждом локусе. Моделируют также случайное объединение пары гамет в зиготы потомка до получения заданного размера популяции. Размеры популяции или выборку из нее при моделировании также можно варьировать, оптимизируя различные этапы селекционно-генетического эксперимента. Средовые модификации количественного признака вводят, например, с помощью конкретных значений коэффициента наследуемости.
Целью имитационного эксперимента может быть, в частности, сравнение эффективности различных методов отбора у самоопыляющихся злаков или подбор схемы генетического эксперимента (минимально необходимые объемы скрещиваний, отборов, количество поколений и т.п.), гарантирующего получение мутантной формы, содержащей новое сочетание генов.
В частности, на кафедре генетики МСХА была создана система программ для имитационного и аналитического моделирования влияния rec-генов, меняющих частоту рекомбинации на маркированных участках хромосом (Смиряев и др., 2000). Цель – подбор схем скрещивания и отбора мутантных форм томата, обеспечивающих достаточную вероятность выделения высокорекомбинантных форм. Рекомендации, полученные в процессе моделирования позволили в реальном многоэтапном эксперименте повысить частоту рекомбинации на маркированном участке II хромосомы томата на 40%.
Заключение. В рамках системы компьютерного сервиса возможно резкое повышение методического уровня и эффективности селекционного процесса от разработки модели и планирования скрещиваний до интегральной оценки линий на заключительном этапе. Применение системы компьютерного сервиса не ограничивается лишь информационным обслуживанием селекционной программы. Она служит средством анализа данных по частной генетике сельскохозяйственных культур и богатейшего опыта селекции, его вторичного использования.
Применение системы компьютерного сервиса повысит эффективность исследований по частной генетике растений и селекционного процесса за счет следующих факторов:
- с помощью БД исследователь будет владеть обширной генетической информацией об имеющемся исходном материале;
- прогноз перспективных гибридных комбинаций до проведения скрещиваний позволит увеличить объемы проработки перспективных кроссов без дополнительных затрат;
- информационно-поисковая система регистрации и документации позволит рационально планировать селекционно-генетические эксперименты, что повысит их достоверность и объективность оценок;
- система программ имитационного моделирования может быть использована в качестве «тренажера селекционера» для оценки различных методов отбора и систем скрещивания на этапе планирования селекционных и генетических программы.
КОНТРОЛЬНЫЕ ВОПРОСЫ И ЗАДАНИЯ
1. В чем отличие БД от экспериментальных или иных данных, записанных на магнитном диске компьютера?
2. Как можно с помощью описанного в этой главе БПД пшеницы или другой культуры выявить закономерности географического распространения тех или иных аллелей?
3. Чем отличается пакет программ от набора программ, используемых в селекции растений?
4. В чем заключаются преимущества и недостатки имитационных экспериментов, выполняемых на компьютере?