Протокол керування мережами SNMP.
Протокол SNMP был разработан с целью проверки функционирования сетевых маршрутизаторов и мостов. Впоследствии сфера действия протокола охватила и другие сетевые устройства, такие как хабы, шлюзы, терминальные сервера, LAN Manager сервера , машины под управлением Windows NT и т.д. Кроме того, протокол допускает возможность внесения изменений в функционирование указанных устройств.
Основными взаимодействующими лицами протокола являются агенты и системы управления. Если рассматривать эти два понятия на языке "клиент-сервер", то роль сервера выполняют агенты, то есть те самые устройства, для опроса состояния которых и был разработан рассматриваемый нами протокол. Соответственно, роль клиентов отводится системам управления - сетевым приложениям, необходимым для сбора информации о функционировании агентов. Помимо этих двух субъектов в модели протокола можно выделить также еще два: управляющую информацию и сам протокол обмена данными.
SNMP регламентирует пространство имен для управляемых сетевых объектов - SMI (Structure of Management Information), а также правила обмена информацией между управляющим (клиентом) и управляемым (сервером) объектами. Таким образом, клиенту (менеджеру SNMP), предоставляется возможность управлять сервером (агентом SNMP).
SMI имеет древовидную структуру. В корне дерева находится ‘.’ (точка). В узлах - имена (или номера) стандартов, протоколов и т. п. Листьями являются идентификаторы устройств или параметров. Для того чтобы определить полное имя уникального объекта, нужно записать путь по дереву от корня к соответствующему узлу. Идентификатор объекта – OID (Object IDentifier) может быть записан в числовой или символьной нотации, он также может быть полным и относительным.
Структура объектов управления в локальном представлении конкретного устройства или программы называется MIB (Management Information Base).
Демон snmpd настраивается с помощью конфигурационного файла /etc/snmpd.conf. Существует также еще один демон – snmptrapd, его задача – следить на стороне клиента за сообщениями от сервера (они называются ловушками).
Даже если система поставляется с собственным SNMP-сервером, для полноценного администрирования Вам нужно проинсталлировать несколько клиентских утилит пакета UCD (University of California at Davis):
snmpget – получает от агента значение SNMP-переменной.
snmpgetnext – получает значение следующей переменной последовательности.
snmpwalk - выполнить опрос всех объектов MIB, начиная с заданного идентификатора OID.
snmpset – передает агенту значение SNMP-переменной.
snmptrap – генерирует сообщение о прерывании.
snmptable – получает таблицу значений SNMP-переменных.
snmptranslate – осуществляет поиск идентификаторов OID и их описаний в иерархии базы MIB.
11) Архітектура графічної підсистеми X Window.
Изначально графическая система ОС Linux получила название X Window System (X). Впоследствии эта система регулярно изменялась, начиная от версии XFree86 и заканчивая текущей версией X.Org (http://www.x.org/wiki/). Модульная архитектура графической системы ОС Linux изображена на рисунке 2.2 и состоящая из следующих компонентов:
Х-сервер (X server). Является ядром графической системы ОС Linux. Х-сервер отвечает за прорисовку изображений окон и других графических объектов, управляет работой мыши и клавиатуры. Помимо отображения графической среды на локальном дисплее, X-сервер обслуживает подключения с удаленных хостов, а так же все обращения к графическому оборудованию.
диспетчер дисплеев (display manager). Основной задачей диспетчера дисплеев является аутентификация пользователей и запуск Х-сервера. По умолчанию в ОС Linux используется диспетчер дисплеев GNOME Desktop Manager (gdm).
диспетчер окон (window manager). Диспетчер окон позволяет пользователям сворачивать, перемещать, изменять размеры окон и управлять виртуальными рабочими столами.
графическое окружение (desktop environment). Графическое окружение выполняет роль связующего звена между диспетчером окон и конечным пользователем. Оно содержит в себе средства настройки отображения рабочего стола и различные программы, предназначенные для работы в графическом режиме. В ОС Linux включено два графических окружения: GNOME и KDE, первое из которых используется по умолчанию при установке ОС Linux.
Х-клиент (X-client). Под Х-клиентом принято понимать специальную программу, общающееся с Х-сервером и посылающее ему запросы, необходимые для работы конкретного графического приложения.
На рисунке пользователь работает на локальной рабочей станции, где запущен Х-сервер. Система X Window работает по принципу клиент-сервер. В качестве клиентов выступают графические приложения, работающие как на локальной рабочей станции, так и на удаленной; в качестве сервера выступает Х-сервер, работающий на локальной рабочей станции. При этом все коммуникации между Х-клиентами и Х-сервером могут осуществляться по защищенномупротоколу SSH.
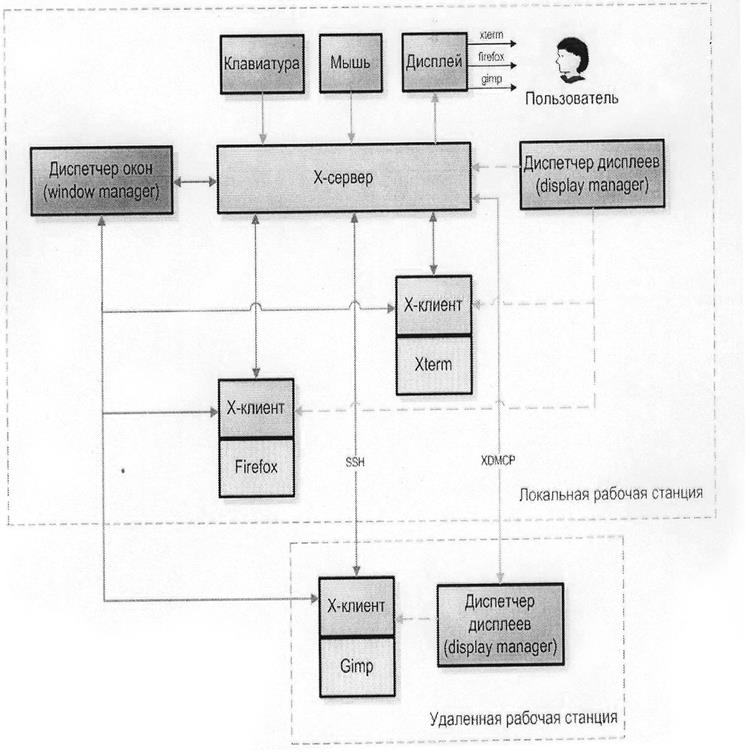
Архитектура системы X Window.
12) Організація захисту програм і даних в ОС UNIX.
Основанием защиты программ и данных есть наличие защищенного режима работы ОС (уровень ОС) и наличие прав доступа к файлам и каталогам (уровень пользователя). В защищенном режиме процессор х86 производит проверки правильности программ при выполнении определённых ситуаций.
Проверка выполняется параллельно с трансляцией адресов:
− проверки границ
− проверка типов
− проверка условий привилегий
− ограничение адресуемого пространства памяти
− ограничение на точки входа в процедуру
− ограничение на точки переключения задач
− ограничение на набор команд
В UNIX поддерживается единообразный механизм контроля доступа к файлам и справочникам файловой системы. Любой процесс может получить доступ к некоторому файлу в том и только в том случае, если права доступа, описанные при файле, соответствуют возможностям данного процесса. Защита файлов от несанкционированного доступа в ОС UNIX основывается на трех фактах. Во-первых, с любым процессом, создающим файл (или справочник), ассоциирован некоторый уникальный в системе идентификатор пользователя, который в дальнейшем можно трактовать как идентификатор владельца вновь созданного файла. Во-вторых, с каждый процессом, пытающимся получить некоторый доступ к файлу, связана пара идентификаторов - действующие идентификаторы пользователя и его группы. В-третьих, каждому файлу однозначно соответствует его описатель - i-узел. Информация i-узла включает идентификаторы текущего владельца. Кроме того, в i-узле файла хранится шкала, в которой отмечено, что может делать с файлом пользователь - его владелец, что могут делать с файлом пользователи, входящие в ту же группу пользователей, что и владелец, и что могут делать с файлом остальные пользователи.
При входе пользователя в систему login проверяет, что пользователь зарегистрирован в систему и знает пароль, образует новый процесс и запускает в нем требуемый для данного пользователя shell. Но перед этим login устанавливает для вновь созданного процесса идентификаторы пользователя и группы, используя информацию, хранящуюся в файлах /etc/passwd и /etc/group. Процесс может получить доступ к файлу или выполнить его (если файл содержит выполняемую программу) только в том случае, если хранящиеся при файле ограничения доступа позволяют это сделать. Связанные с процессом идентификаторы передаются создаваемым им процессам, распространяя на них те же ограничения. Однако в некоторых случаях процесс может изменить свои права с использованием системных вызовов setuid и setgid, а иногда система может изменить права доступа процесса автоматически.
Пользователи делятся на три категории: владелец ресурса, обычный пользователь и привилегированный пользователь (uid=0 или gid=0). В коде ядра и в индексных дескрипторах файлов заданы права и принадлежность ресурсов, а в файле /etc/passwd задано соответствие имени пользователя номерам uid и gid. Система берет на себя выполнение всех критических с точки зрения защиты операций - авторизация, непосредственный доступ к аппаратуре и т. п. В некоторых случаях права суперпользователя могут быть делегированы обычным пользователям (признак suid, команда sudo), но делается это строго определенным и контролируемым образом.
13) Конфігурація, складання й інсталяція ядра ОС GNU/Linux.
Существуют три метода создания файла конфигурации, используемого при сборке нового ядра:
1 make config
2 make menuconfig
3 make xconfig
make config - это наиболее простой пошаговый сценарий.
make menuconfig - это более удобный метод (требует наличие ncurses).
make xconfig - это графическая утилита для настройки ядра.
Для каждой из представленных опций есть 3 установочных параметра: y,m,n.
y(yes) - Включает или встраивает опцию в ядро. m(module) - Создает для выбранной опции загружаемый в динамическом режиме модуль (без reboot'a). Существует не для всех опций. n(no) - Отключает поддержку опции.
Компиляция ядра и установка модулей.
В свою очередь этот этап делится на шаги:
1) Подготовка
-> make dep
-> make clean
2) Непосредственно сборка ядра
-> make bzImage|bzdisk|bzlilo
3) Сборка и установка модулей
-> make modules
-> make modules_install
Первый из них - make dep и make clean - являются подготовкой. После выполнения make dep создаются файлы зависимостей (.depend), которые рас полаются
в каждом из подкаталогов древа исходных кодов. Если нет нарушений в расположении компонентов древа, то процесс пройдет спокойно. Далее используется команда make clean, которая удалит все лишние (вспомогательные) файлы, созданные от предыдущих процессов компиляции.
Далее идет шаг, при котором необходимо непосредственно собрать ядро. Для сборки ядра придется выбрать одну из 3-х команд: make bzImage, make bzdisk или make bzlilo. Каждая из команд выполняет фактически одну и ту-же операцию, только
две последние выполняют одно дополнительное действие.
Рассмотрим подробнее каждую из команд:
make bzImage - стандартная операция, при которой будет только скомпилировано ядро. Если все прошло без проблем, то созданное в результате компиляции ядро будет расположено в каталоге /usr/src/linux/arch/i386/boot. В этом случае ядру присваивается имя bzImage. Диспетчер загрузки lilo|grub должен найти это ядро и загрузить его.
make bzdisk - этот метод позволяет выполнить практически ту-же задачу, что и bzImage, но после завершения компиляции будет автоматически выполнено копирование нового ядра на дискету. В дальнейшем эту дискету можно будет использовать для загрузки системы.
make bzlilo - это рекомендуемый метод формирования и инсталляции нового ядра, требующий предварительной подготовки lilo. При использовании этого метода map-файл ядра не перемещается в другой каталог. Более того новое ядро может быть записано поверх уже существующего, причем записано с ошибками, поэтому его использование не рекомендуется. Этот метод очень похож на bzImage и отличается только наличием дополнительной операцией, которая выполняется после совершения компиляции ядра. После компиляции ядра происходит копирование файлов созданного ядра в каталог / в качестве vmlinuz (при этом сохраняется резервная копия файла vmlinuz).
Третим шагом является сборка и установка модулей ядра.
Этот процесс выполняется с помощью 2-х команд make modules и make modules_install. Название команды make modules говорит само за себя: при выполнении этой команды происходит сборка модулей, которые соответствуют ядру, созданному на предыдущем этапе. Команда make modules_install, в сою очередь, перемещает созданные модули из исходного древа ядра в каталог /lib/modules/<kernel-version>/kernel/<module-type>. В качестве типа модуля (<module-type>) используется имя категории, к которой относятся созданные модули (Например: block, misk, net, pcmcia, etc...).
14) Архітектура ядра ОС UNIX (Linux).

Ядро - минимальный набор программ, резидентных в оперативной памяти. На диске ядро оформлено как выполняемый файл и загружается в память начальным загрузчиком, начиная с 0-вого адреса.
Ядро состоит из нескольких подсистем:
− управления памятью
− управления процессами
− виртуальной ФС (VFS)
− сетевой поддержки
− интерфейса системных вызовов (syscall API)
− начальной инициализации
− межпроцессного взаимодействия
Большую часть ядра составляют драйверы (устройств, файловых систем, программные), которые могут быть оформлены как встроенные или в виде модулей.
Обращения к операционной системе выглядят так же, как обычные вызовы функций в программах на языке Си, и библиотеки устанавливают соответствие между этими вызовами функций и элементарными системными операциями. При этом программы на ассемблере могут обращаться к операционной системе непосредственно, без использования библиотеки системных вызовов.
Подсистема управления файлами обращается к данным, которые хранятся в файле, используя буферный механизм, управляющий потоком данных между ядром и устройствами внешней памяти.
Буферный механизм, взаимодействуя с драйверами устройств ввода-вывода блоками, инициирует передачу данных к ядру и обратно. Драйверы устройств являются такими модулями в составе ядра, которые управляют работой периферийных устройств.
Подсистема управления процессами отвечает за синхронизацию процессов, взаимодействие процессов, распределение памяти и планирование выполнения процессов.
15) Модифікація вихідного коду ядра ОС GNU/Linux і засоби його відлагодження.
Gdb, DDB
Gdb -k kernel
Хотя gdb -k является отладчиком не реального времени с высокоуровневым пользовательским интерфейсом, есть несколько вещей, которые он сделать не сможет. Самыми важными из них являются точки останова и пошаговое выполнение кода ядра.
Если вам нужно выполнять низкоуровневую отладку вашего ядра, то на этот случай имеется отладчик реального времени, который называется DDB. Он позволяет устанавливать точки останова, выполнять функции ядра по шагам, исследовать и изменять переменные ядра и прочее. Однако он не может использовать исходные тексты ядра и имеет доступ только к глобальным и статическим символам, а не ко всей отладочной информации, как gdb.
Чтобы отконфигурировать ваше ядро для включения DDB, добавьте строчку с параметром
options DDB
в ваш конфигурационный файл, и перестройте ядро.
После того, как ядро с DDB запущено, есть несколько способов войти в DDB. Первый, и самый простой, способ заключается в наборе флага загрузки -d прямо в приглашении загрузчика. Ядро будет запущено в режиме отладки и войдет в DDB до выполнения процедуры распознавания каких бы то ни было устройств. Поэтому вы можете выполнить отладку даже функций распознавания/присоединения устройств.
Вторым способом является переход в режим отладчика сразу после загрузки системы. Есть два простых способа этого добиться. Если вы хотите перейти в отладчик из командной строки, просто наберите команду:
# sysctl debug.enter_debugger=ddb
Відлагодження модулів в ОС Linux.
− Использование отладочных сообщений - printk([<n>]"message");
− Запись отладочной информации в /proc по запросу – create_proc_read_entry()
− Использование интерфейса ioctl() в отладочных целях
− Отладка с помощью gdb
− Отладка с помощью встроенного в ядро отладчика
16) Концепція віртуальної файлової системи в ОС UNIX.
Виртуальная файловая система (Virtual File System) – это подсистема ядра, реализующая интерфейс пользовательских программ к файловой системе. Все файловые системы зависят от VFS, что позволяет им совместно функционировать.
Подсистема VFS позволяет системным вызовам, таким как open(), read() и write(), работать независимо от файловой системы и физической среды носителя. Общий интерфейс возможен только благодаря тому, что в ядре реализован обобщающий уровень, скрывающий низкоуровневый интерфейс файловых систем: VFS реализует общую файловую модель, представляющую общие функции и особенности работы потенциально возможных файловых систем. Эта файловая модель похожа на файловую систему Unix.
Обобщающий уровень работает путем определения базовых интерфейсов и структур данных, необходимых для поддержки всех файловых систем. Поддержка формирует се концепции работы с файловой системой, такие как "открытие файла", "элемент каталога" и др. Все детали скрываются в коде самой файловой системы. Таким образом, по отношению к остальным частям ядра все файловые системы поддерживают одинаковые функции. Схема работы библиотечный библиотечный вызов write(f, &buf, len) приведена на рисунке ниже:

Реализация подсистемы VFS имеет черты объектно ориентированного подхода. Общая модель представлена в виде структур данных, похожих на объекты: структуры данных содержат указатели на элементы данных и на функции, которые работают с этими данными. Существует четыре основных типа объектов VFS:
− Объект суперблок (superblock), представляющий одну смонтированную файловую систему.
− Объект файловый индекс (inode), представляющий определенный файл.
− Объект элемент каталога (dentry), представляющий определенный элемент каталога. Объект dentry представляет собой фрагмент пути, который может содержать файл.
− Объект файл (file), представляющий открытый файл, связанный с процессом.
Каждый из объектов VFS содержит объект операций, которые описывающие методы, которые ядро может применять для основных объектов:
− Объект super_operations (операции с суперблоком ФС). Содержит методы, которые ядро может вызывать для определенной файловой системы.
− Объект inode_operations (операции с файловыми индексами). Содержит методы, которые ядро вызывать для определенного файла.
− Объект dentry_operations (операции с элементами каталогов). Содержит методы, которые ядро может применять для определенного элемента каталогов.
− Объект file_operations (операции с файлами). Содержит операции, которые ядро может вызывать для открытого файла.
17) Програмний інтерфейс ядра ОС GNU/Linux для керування периферійними пристроями.
В операционных системах семейства Linux для управления периферийными устройствами используют интерфейс файлов устройств.
Пользователь взаимодействует с устройствами через посредничество файловой системы. Каждое устройство имеет имя, похожее на имя файла, и пользователь обращается к нему как к файлу. Специальный файл устройства имеет индекс и занимает место в иерархии каталогов файловой системы. В большинстве своем, физические устройства используются как для вывода, так и для ввода, таким образом необходимо иметь некий механизм для передачи данных от процесса (через модуль ядра) к устройству.
Файл устройства отличается от других файлов типом файла, хранящимся в его индексе, либо "блочный", либо "символьный специальный", в зависимости от устройства, которое этот файл представляет. Если устройство имеет как блочный, так и символьный интерфейс, его представляют два файла: специальный файл устройства ввода-вывода блоками и специальный файл устройства посимвольного ввода-вывода. Системные функции для обычных файлов, такие как open, close, read и write, имеют то же значение и для устройств.
Системная функция ioctl предоставляет процессам возможность управлять устройствами посимвольного ввода-вывода, но не применима в отношении к файлам обычного типа. Тем не менее, драйверам устройств нет необходимости поддерживать полный набор системных функций.
Еще какие-то:
− check_region() - проверка доступности диапазона портов В/В
− request_region() - запрос диапазона портов
− release_region() - освобождение диапазона
− inb()/outb() - чтение/запись в порту побайтно
− inw()/outw() - пословно (16)
− inl()/outl() - пословно (32)
− insb()/outsb() и т. п. - чтение/запись строки байтов или слов
− rmb()/wmb()/mb() - функции, гарантирующие реальное чтение(запись) данных, минуя кэш.
− Аналогичный набор функций существует для работы с памятью устройств (I/O memory) - check_mem_region(), … readb()/writeb(),
#include <linux/sched.h> // захват прерывания#include <linux/interrupt.h> // работа с прерыванием#include <asm/io.h> //ввод и вывод портов#include <linux/ioport.h>// захват портов ввода-вывода#include <linux/kernel.h>// функции для выделения памяти18) Компіляція, встановлення і видалення модулів в ОС GNU/Linux.
Для компиляции модуля достаточно написать только одну строчку в Makefile:
obj-m += hello-1.o
Для того, чтобы запустить процесс сборки модуля, дайте команду make -C /usr/src/linux-`uname -r` SUBDIRS=$PWD modules.
Компиляция отдельного модуля :
gcc -O -Wall -DMODULE -D__KERNEL__ -I/usr/src/linux/include\ -c mymodule.c
Для установки модуля в систему необходимы права суперпользователя root. Сама установка осуществляется командой insmod <файл модуля>.
Удаление модуля (тоже с правами root) – rmmod <имя модуля>.
Просмотреть список загруженных модулей можно командой lsmod, которая в свою очередь обращается за необходимыми сведениями к файлу /proc/modules.
19) Програмний інтерфейс модулів із ядром в ОС GNU/Linux.
Программный интерфейс модулей с ядром ОС Linux представлен набором функций вызываемых в процессе жизненного цикла модуля. Это функции init_module() – вызывается при загрузке модуля в ядро и exit_module() – при выгрузке модуля. Данные функции работают на уровне системных вызовов. Например, при вызове функции ядра sys_init_module сначала выполняется проверка того, имеет ли вызывающий модуль соответствующие разрешения (при помощи функции capable). Затем вызывается функция load_module, которая выполняет механическую работу по размещению модуля в ядре и производит необходимые операции. Функция load_module возвращает ссылку, которая указывает на только что загруженный модуль. Затем он вносится в двусвязный список всех модулей в системе, и все потоки, ожидающие изменения состояния модуля, уведомляются при помощи специального списка. В конце вызывается функция init() и статус модуля обновляется, чтобы указать, что он загружен и доступен.
Также неотъемлемой частью программного интерфейса модулей являются макроопределения MODULE_LICENSE(), MODULE_AUTHOR(DRIVER_AUTHOR), MODULE_DESCRIPTION(DRIVER_DESC).
20) Використання спеціальних файлів в ОС UNIX для доступу до пристроїв.

В операционной системе UNIX большинство внешних устройств доступно пользовательским программам в виде специальных файлов. Эти файлы могут быть, соответственно, двух типов — символьные и блочные. Традиционно, все файлы устройств располагаются в каталоге /dev и имеют имена, соответствующие назначению устройства. Программы могут открывать, читать и записывать данные в файлы устройств как в обычные файлы, при этом операционная система транслирует пользовательские запросы драйверу соответствующего устройства.
Специальные файлы не хранят данные. Они обеспечивают механизм отображения физических внешних устройств в имена файлов файловой системы. Каждому устройству, поддерживаемому системой, соответствует, по меньшей мере, один специальный файл. в UNIX все устройства принято рассматривать как СФ. Эти файлы размещаются в каталоге /dev. Каждое внешнее устройство связано по крайней мере с одним именем в каталоге /dev. Связь имени файла с конкретным внешним устройством осуществляется через ИД, в поле di_mode которого установлены биты. Символьные специальные файлы ассоциируются с внешними устройствами, которые не обязательно требуют обмена блоками данных равного размера. Примерами таких устройств являются терминалы. При обмене данными с блочным устройством система буферизует данные во внутреннем системном кеше. ИД, описывающий специальный файл в поле di_addr содержит следующую структуру данных, позволяющую определить тип и номер устройства, к которому выполняется обращение: struct {char di_minor; char di_major;};
Тип устройства di_major определяет выбор драйвера ввода/вывода, а номер устройства di_minor передается драйверу в качестве параметра. Параметр позволяет выбрать одно из нескольких однотипных устройств или задать какие-то дополнительные функции обработки.
Первое число называют "Старшим номером" устройства. Второе -- "Младшим номером". Старший номер говорит о том, какой драйвер используется для обслуживания аппаратного обеспечения. Каждый драйвер имеет свой уникальный старший номер. Все файлы устройств с одинаковым старшим номером управляются одним и тем же драйвером. Младший номер используется драйвером, для различения аппаратных средств, которыми он управляет.
Основное различие блочных и символьных устройств состоит в том, что обмен данными с блочным устройством производится порциями байт -- блоками. Они имеют внутренний буфер, благодаря чему повышается скорость обмена. В большинстве Unix-систем размер одного блока равен 1 килобайту или другому числу, являющемуся степенью числа 2. Символьные же устройства -- это лишь каналы передачи информации, по которым данные следуют последовательно, байт за байтом. Большинство устройств относятся к классу символьных, поскольку они не ограничены размером блока и не нуждаются в буферизации.
21) Керування потоком обміну та шириною полоси пропускання в ОС GNU/Linux.
Управлением потоком обмена и шириной полосы пропускания в ОС Linux занимается пакет утилит iproute2.
iproute2 — это набор утилит для управления параметрами сетевых устройств в ядре Linux. Эти утилиты были разработаны в качестве унифицированного интерфейса к ядру Linux, которое непосредственно управляет сетевым трафиком. iproute2 бессилен изменить параметры, если их не поддерживает ядро.
iproute2 заменил полный набор классических сетевых утилит UNIX, которые ранее использовались для настройки сетевых интерфейсов, таблиц маршрутизации и управления arp‐таблицами: ifconfig, route, arp, netstat.
Набор утилит включает в себя три основные программы:
− ip — утилита для просмотра параметров и конфигурирования сетевых интерфейсов, сетевых адресов, таблиц маршрутизации, правил маршрутизации, arp‐таблиц, IP‐туннелей, адресов multicast рассылки, маршрутизацией multicast пакетов.
− tc — утилита для просмотра и конфигурирования параметров управления трафиком (tc — аббревиатура от traffic control). Позволяет управлять классификацией трафика, дисциплинами управления очередями для различных классов трафика либо целиком для сетевого интерфейса (корневые дисциплины), что, в свою очередь, позволяет реализовать QoS в нужном для системы объеме:
− разделение разных типов трафика по классам (не только по битам ToS в IP‐пакете, но и по другим данным из заголовка IP‐пакета)
− назначение разных дисциплин обработки очередей трафика с разным приоритетом, механизмами прохождения очереди, ограничениями по скорости и т. п.
− ss —утилита для просмотра текущих соединений и открытых портов. Аналог традиционной утилиты netstat.
Автором iproute2 является Алексей Кузнецов (Alexey Kuznetsov).
tc может управлять несколькими сетевыми объектами. Их собственно три: