LINGUISTICS AND ITS STRUCTURE
Linguistics is a science about natural languages. To be more precise, it covers a whole set of different related sciences (see Figure I.1).
General linguistics is a nucleus [18, 36]. It studies the general structure of various natural languages and discovers the universal laws of functioning of natural languages. Many concepts from general linguistics prove to be necessary for any researcher who deals with natural languages. General linguistics is a fundamental science that was developed by many researchers during the last two centuries, and it is largely based on the methods and results of grammarians of older times, beginning from the classical antiquity.
As far as general linguistics is concerned, its most important parts are the following:
· Phonology deals with sounds composing speech, with all their similarities and differences permitting to form and distinguish words.
· Morphology deals with inner structure of individual words and the laws concerning the formation of new words from pieces¾morphs.
· Syntax considers structures of sentences and the ways individual words are connected within them.
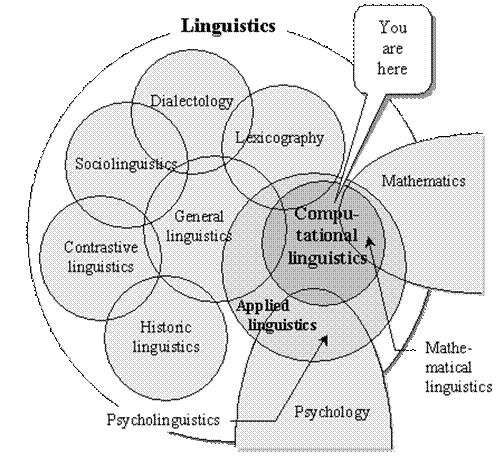 FIGURE I.1. Structure of linguistic science.
FIGURE I.1. Structure of linguistic science.
|
· Semantics and pragmatics are closely related. Semantics deals with the meaning of individual words and entire texts, and pragmatics studies the motivations of people to produce specific sentences or texts in a specific situation.
There are many other, more specialized, components of linguistics as a whole (see Figure I.1).
Historical, or comparative, linguistics studies history of languages by their mutual comparison, i.e., investigating the history of their similarities and differences. The second name is explained by the fact that comparison is the main method in this branch of linguistics. Comparative linguistics is even older than general linguistics, taking its origin from the eighteenth century.
Many useful notions of general linguistics were adopted directly from comparative linguistics.
Historical linguistics discovered, for example, that all Romance languages (Spanish, Italian, French, Portuguese, Romanian, and several others) are descendants of Latin language. All languages of the Germanic family (German, Dutch, English, Swedish, and several others) have their origins in a common language that was spoken when German tribes did not yet have any written history. A similar history was discovered for another large European family of languages, namely, for Slavonic languages (Russian, Polish, Czech, Croatian, Bulgarian, among others).
Comparative study reveals many common words and constructions within each of the mentioned families—Romance, Germanic, and Slavonic—taken separately.
At the same time, it has noticed a number of similar words among these families. This finding has led to the conclusion that the mentioned families form a broader community of languages, which was called Indo-European languages. Several thousand years ago, the ancestors of the people now speaking Romance, Germanic, and Slavonic languages in Europe probably formed a common tribe or related tribes.
At the same time, historic studies permits to explain why English has so many words in common with the Romance family, or why Romanian language has so many Slavonic words (these are referred to as loan words).
Comparative linguistics allows us to predict the elements of one language based on our knowledge of another related language. For example, it is easy to guess the unknown word in the following table of analogy:
| Spanish | English |
| constitución | constitution |
| revolución | revolution |
| investigación | ? |
Based on more complicated phonologic laws, it is possible even to predict the pronunciation of the French word for the Spanish agua (namely [o], eau in the written form), though at the first glance these two words are quite different (actually, both were derived from the Latin word aqua).
As to computational linguistics, it can appeal to diachrony, but usually only for motivation of purely synchronic models. History sometimes gives good suggestions for description of the current state of language, helping the researcher to understand its structure.
Contrastive linguistics, or linguistic typology, classifies a variety of languages according to the similarity of their features, notwithstanding the origin of languages. The following are examples of classification of languages not connected with their origin.
Some languages use articles (like a and the in English) as an auxiliary part of speech to express definite/indefinite use of nouns. (Part of speech is defined as a large group of words having some identical morphologic and syntactic properties.) Romance and Germanic languages use articles, as well as Bulgarian within the Slavonic family. Meantime, many other languages do not have articles (nearly all Slavonic family and Lithuanian, among others). The availability of articles influences some other features of languages.
Some languages have the so-called grammatical cases for several parts of speech (nearly all Slavonic languages, German, etc.), whereas many others do not have them (Romance languages, English—from the Germanic family, Bulgarian—from the Slavonic family, and so on).
Latin had nominative (direct) case and five oblique cases: genitive, dative, accusative, ablative, and vocative. Russian has also six cases, and some of them are rather similar in their functions to those of Latin. Inflected parts of speech, i.e., nouns, adjectives, participles, and pronouns, have different word endings for each case.
In English, there is only one oblique case, and it is applicable only to some personal pronouns: me, us, him, her, them.
In Spanish, two oblique cases can be observed for personal pronouns, i.e., dative and accusative: le, les, me, te, nos, las, etc. Grammatical cases give additional mean for exhibiting syntactic dependencies between words in a sentence. Thus, the inflectional languages have common syntactic features.
In a vast family of languages, the main type of sentences contains a syntactic subject (usually it is the agent of an action), a syntactic predicate (usually it denotes the very action), and a syntactic object (usually it is the target or patient of the action). The subject is in a standard form (i.e., in direct, or nominative, case), whereas the object is usually in an oblique case or enters in a prepositional group. This is referred to as non-ergative construction.
Meantime, a multiplicity of languages related to various other families, not being cognate to each other, are classified as ergative languages. In a sentence of an ergative (эргативный падеж –винительный) language, the agent of the action is in a special oblique (called ergative) case, whereas the object is in a standard form. In some approximation, a construction similar to an ergative one can be found in the Spanish sentence Me simpatizan los vecinos, where the real agent (feeler) yo ‘I’ is used in oblique case me, whereas the object of feeling, vecinos, stays in the standard form. All ergative languages are considered typologically similar to each other, though they might not have any common word. The similarity of syntactical structures unites them in a common typological group.
Sociolinguistics describes variations of a language along the social scale. It is well known that various social strata (слой общества) often use different sublanguages within the same common language, wherever the same person uses different sublanguages in different situations. It suffices (этого достаточно) to compare the words and their combinations you use in your own formal documents and in conversations with your friends.
Dialectology compares and describes various dialects, or sublanguages, of a common language, which are used in different areas of the territory where the same language is officially used. It can be said that dialectology describes variations of a language throughout the space axis (while diachrony goes along the time axis). For example, in different Spanish-speaking countries, many words, word combinations, or even grammatical forms are used differently, not to mention significant differences in pronunciation. Gabriel García Márquez, the world-famous Colombian writer, when describing his activity as a professor at the International Workshop of cinematographers in Cuba, said that it was rather difficult to use only the words common to the entire Spanish-speaking world, to be equally understandable to all his pupils from various countries of Latin America. A study of Mexican Spanish, among other variants of Spanish language is a good example of a task in the area of dialectology.
Lexicography studies the lexicon, or the set of all words, of a specific language, with their meanings, grammatical features, pronunciation, etc., as well as the methods of compilation of various dictionaries based on this knowledge. The results of lexicography are very important for many tasks in computational linguistics, since any text consists of words. Any automatic processing of a text starts with retrieving the information on each word from a computer dictionary compiled beforehand.
Psycholinguistics studies the language behavior of human beings by the means of a series of experiments of a psychological type. Among areas of its special interest, psycholinguists studies teaching language to children, links between the language ability in general and the art of speech, as well as other human psychological features connected with natural language and expressed through it. In many theories of natural language processing, data of psycholinguistics are used to justify the introduction of the suggested methods, algorithms, or structures by claiming that humans process language “just in this way.”
Mathematical linguistics. There are two different views on mathematical linguistics. In the narrower view, the term mathematical linguistics is used for the theory of formal grammars of a specific type referred to as generative (порождающая грамматика) grammars. This is one of the first purely mathematical theories devoted to natural language. Alternatively, in the broader view, mathematical linguistics is the intersection between linguistics and mathematics, i.e., the part of mathematics that takes linguistic phenomena and the relationships between them as the objects of its possible applications and interpretations.
Since the theory of generative grammars is nowadays not unique among linguistic applications of mathematics, we will follow the second, broader view on mathematical linguistics.
One of the branches of mathematical linguistics is quantitative linguistic. It studies language by means of determining the frequencies of various words, word combinations, and constructions in texts. Currently, quantitative linguistics mainly means statistical linguistics. It provides the methods of making decisions in text processing on the base of previously gathered statistics.
One type of such decisions is resolution of ambiguity (неопределенность, неясность)in text fragments to be analyzed. Another application of statistical methods is in the deciphering of texts in forgotten languages or unknown writing systems. As an example, deciphering of Mayan glyphs was fulfilled in the 1950’s by Yuri Knorozov [39] taking into account statistics of different glyphs (see Figure I.2).
Applied linguistics develops the methods of using the ideas and notions of general linguistics in broad human practice. Until the middle of the twentieth century, applications of linguistics were limited to developing and improving grammars and dictionaries in a printed form oriented to their broader use by non-specialists, as well as to the rational methods of teaching natural languages, their orthography and stylistics. This was the only purely practical product of linguistics.
 FIGURE I.2. The ancient Mayan writing system was deciphered with statistical methods.
FIGURE I.2. The ancient Mayan writing system was deciphered with statistical methods.
|
In the latter half of the twentieth century, a new branch of applied linguistics arose, namely the computational, or engineering, linguistics. Actually, this is the main topic of this book, and it is discussed in some detail in the next section.