Тема : Обробка, систематизація і оцінка результатів досліду
Основні питання:
1. Статистична обробка отриманого експериментального матеріалу.
2. Оцінка репрезентативності наслідків дослідження.
3. Співставлення здобутих даних з результатами досліджень інших авторів, взаємозв'язків між ними.
4. Розрахунок очікуваного економічного ефекту від використання науково-технічної продукції.
Рекомендована література:
1. Білуха М. Т. Основи наукових досліджень. - К.: Вища школа, 1997. - 135с.
2. Викторов П. И., Меньків В. К. Методика и организация зоотехнических опытов. -М: Агропромиздат, 1991. - 112с.
3. Горбатенко І. Ю., Іванишина Г. О. - Основи наукових досліджень. Херсон, 2001 -92с.
4. Гятницька - Позднякова I. С. - Основи наукових досліджень у вищій школі. -К.:-2003.- 115с.
5. Дудченко А. А. Дудченко Я. А. Основы научных исследований: Учебное пособие. - К.: «Знания», 2000 - 114с.
6. Мальцев П.М., Емельянова Н.А. Основы научных исследований. - К.: Вища школа, 1982. - 124с.
Запитання для самоперевірки
1. Дисперсійний метод аналізу результатів досліджень
2. Не дисперсійний метод аналізу досліджень
3. Кореляційний та регресійний аналіз
Дисперсійний метод аналізу
Дисперсійний аналіз розробив та ввів у практику досліджень англійський вчений Р. Фішер. Дисперсійний аналіз широко використовується для планування експерименту і статистичної обробки його даних.
При дисперсійному аналізі одночасно обробляють дані декількох вибірок (варіантів), які складають єдиний статистичний комплекс оформлений в вигляді спеціальної робочої таблиці. Структура статичного комплексу і його послідуючий аналіз визначається схемою і методикою експерименту.
Суть дисперсійного аналізу полягає в тому, що розподіляють загальну суму квадратів відхилень та загальне число ступенів свободи на частини - компоненти, які відповідають структурі експерименту та оцінці значимості дії і взаємодії факторів, що вивчаються.
За допомогою дисперсійного аналізу встановлюються вибіркові показники зв'язку факторів і результативних ознак достатніх для розповсюдження отриманих із вибірки висновків на всю генеральну сукупність фактів. Такий аналіз також використовуть для вивчення якісних ознак. Великою перевагою методу є його пристосованість до отримання висновків на обмежених за чисельністю сукупностях.
Загальна мета використання дисперсійного аналізу полягає у вивченні зв'язків між причинами та їхніми наслідками, між факторами і результатами їхньої дії і взаємодії.
В основі дисперсійного аналізу лежить положення, що дослід достовірний лише в тому випадку, якщо розсіювання між варіантами його більше ніж між повтореннями одного варіанту.
Основним завданням дисперсійного аналізу є визначення частки впливу різних факторів окремо і в загальному на зміну вивчаємої ознаки.
В досліді мінливість поділяночних варіантів обумовлена трьома факторами:
1. - дією досліджувального фактора (сорти, гібриди, строки сівби, густота та ін.) - це розсіювання по варіантам;
2. - родючість ґрунту кожного повторення (систематична помилка) - це розсіювання по повторенням;
3. - випадковими причинами (неточність вимірів, неоднорідність родючості ґрунту в межах повторень, індивідуальна мінливість риб) - це залишкове розсіювання.
Після закінчення експерименту отримані дані заносять в таблицю (записують значення по варіантам і по повторенням). Потім визначають суми по повторенням Р, варіантам V та загальну суму спостережень ^ X. Далі
вираховують:
1. Число ступенів свободи: для варіантівVv = 1-1; для повтореньvp = п-1; для похибкиvz = (1-1)*(п-1), де
Vv - число ступенів свободи для варіантів;
V - число ступенів свободи для повторень;
V - число ступенів свободи для похибки. 1 - кількість варіантів;
п - кількість повторень.
2. Загальне число спостережень ;N = 1*п;
3. Корегуючий фактор:С = (^ X)2/^ де С - корегуючий фактор;
^ X - загальна сума спостережень;
N - загальне число спостережень.
4. Загальну суму квадратів:Су = ^ X2 - С, де
^ X 2 - сума квадратів спостережень; С - корегуючий фактор.
5. Сума квадратів для повторень:Ср = ^ p2/1-С ; де ^p - сума повторень;
1 - кількість варіантів.
6. Сума квадратів для варіантів: ^= ^V2/п - С;^V 2 - сума варіантів.
7. Сума квадратів для похибки:Cz = Су - ^ - Ср.
Діленням певної суми квадратів на число ступенів свободи отримують дисперсію.
Дисперсія - це розсіювання даних і показників на складові частини. Звідси і назва методу - дисперсійний аналіз.
Найбільш застосовують дисперсію варіантів та дисперсію похибки або залишку.
8 у= —, де і — 1
S v - дисперсія для варіантів;
С - сума квадратів для варіантів;
1 -1 - число ступенів свободи для варіантів.
с2 Cz 8 z = , де
z (і — 1) * (П — 1)
S z - дисперсія для похибки;
С - сума квадратів для похибки;
(1-1)*(п-1) - число ступенів свободи для похибки.
Співвідношення цих двох дисперсій є тим основним критерієм, який дає змогу дати загальну оцінку достовірності різниць між середніми арифметичними або загальну оцінку достовірності досліду. Цей критерій називається критерієм Фішера і позначається першою літерою прізвища автора дисперсійного аналізу Фішера, який визначається за формулою:
F = SVS2z, де
F - критерій Фішера;
- дисперсія варіантів; S z - дисперсія похибки.
Обчисливши фактичне значення критерію Фішера ^ф) його порівнюють із теоретичним критерієм на певних рівнях значимості. Якщо Fф<Fт, то достовірність різниць між середніми арифметичними немає і на цьому перевірка результатів досліджень припиняється. А якщо критерій Фішера фактичний дорівнює критерію теоретичному або більший за нього то достовірність різниць між середніми арифметичними доведена. Це означає, що в досліді є одна або декілька пар варіантів, між середніми арифметичними яких є достовірна різниця.
Тому в таких випадках крім обчислення критерію Фішера треба знаходити найменшу істотну різницю (НІР) та оцінку про точність досліду.
Найменша істотна різниця характеризує граничну похибку вибіркових середніх при певному числі ступенів свободи. НІР вираховують за формулою:
НІР05 = НІР01 =
Щоб визначити НІР, необхідно за даними дисперсійного аналізу розрахувати:
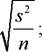
узагальнену похибку досліду s- =
|2/
похибку різниць середніх sd =< . де
V п
Sz - дисперсія похибки;
п - кількість повторень
З цим статистичним показником порівнюють різницю між середніми арифметичними. Якщо d>НІР, то між варіантами доведена достовірність досліду, а якщо навпаки d<НІР, то достовірної різниці немає.
Висновок про точність досліду роблять наприкінці дисперсійного аналізу на основі числового значення відносної похибки досліду, яку визначають за формулою:
&,%=— *100, де
X
Sx% - відносна похибка досліду; Sx - похибка досліду; х- середня арифметична.
2. Не дисперсійні методи аналізу
Не дисперсійні методи статистичної обробки застосовують для дослідів, у яких не використовують рендомізоване розміщення варіантів, це стандартний та систематичний методи. Досліди розміщені стандартним методом, обробляють різницевим методом, а розміщені систематично - дробовим.
Дробовий метод статистичної обробки результатів досліджень має справу з великою кількістю повторних спостережень. Таким умовам часто відповідають результати досліджень більш-менш однорідної сукупності, варіювання об'єктів якої обумовлено випадковими факторами.
Основним методом при не дисперсійному аналізі є різницевий (стандартний) метод. Найчастіше його використовують в дослідах за умов сильного варіювання родючості ґрунту.
Існує декілька способів розрахунків показників стандарту (контроль) для будь якої ділянки дослідного варіанту:
1. В якості показника контролю може застосовуватись середня арифметична двох найближчих стандартів.
2. В дослідах із розміщенням стандартів через 2-3 дослідні ділянки і більше за показник (контроль) може бути взятий показник інтерполірованого контролю (розрахункового).
3. Кореляційний та регресійний аналіз
У практиці досліджень майже завжди доводиться встановлювати зв'язки між кількісними та якісними ознаками у більшості випадків, які є недостатньо точними і мають лише приблизний характер. Встановлення закономірностей зв'язку між ознаками, що вивчаються, ускладнюються також тим, що кожному значенню досліджуваної ознаки відповідає не одне значення другої, а цілий ряд їх сукупних значень.
У статистичному аналізі ознак існує дві категорії залежностей (зв'язку): функціональні й кореляційні (статистичні). Функціональна залежність між двома або більше ознаками легко визначається будь-яким математичним рівнянням, оскільки кожному значенню однієї змінної величини відповідає відповідне значення другої, тобто зміні аргументу відповідає рівне або приблизне значення функції.
При кореляційному зв'язку залежність між ознаками пов'язана з їх варіацією, яка виявляється відхиленнями від їх середніх значень, при цьому із збільшенням однієї також зростає і друга, або навпаки, зі збільшенням першої ознаки друга зменшується. Тому існує позитивна і від'ємна кореляція.
Кореляційний (статистичний) зв'язок - це зв'язок між ознаками, за яких числовому значенню однієї змінної величини, що вивчається, відповідає певна кількість другої змінної, яка виявляється лише в середньому для всієї сукупності спостережень .
Методи кореляції застосовують для встановлення зв'язків між двома ознаками - простої (парної) кореляції, а при виявленні зв'язків між трьома і більшим числом ознак - множинної кореляції. При простій кореляції зв'язок у більшості випадків має лінійний характер і виражається лінійним рівнянням, а при множинній - криволінійним (параболічним), тобто цей зв'язок виражається будь-яким іншим математичним методом. Тому залежно від форми зв'язку розрізняють лінійну, множинну та криволінійну кореляції. Методи кореляції дозволяють вирішити такі завдання:
- визначити середню змінну залежної величини відносно впливу одного або комплексу факторів;
- встановити ступінь залежності між результативною ознакою й одним із факторів за середнього значення інших;
- встановити міру зміни відносної величини та залежної змінної на одиницю відносної зміни фактора або факторів;
- визначити рівень тісноти зв'язку результативної ознаки з усім комплексом включених до аналізу факторів або з окремим фактором при виключенні впливу інших чинників;
- статистичний аналіз загального об'єму варіації залежної змінної і визначення ролі кожного фактора в цьому варіюванні;
- статистичної оцінки вибіркових показників кореляційного зв'язку, отриманих за вибірковими даними.
Попереднім етапом кореляційного аналізу є встановлення причинних зв'язків у досліджуваних явищах. Глибокий і всебічний розгляд сутності явища повинен визначати основні контури існуючих зв'язків і створювати основу для застосування різних методів кореляції.
Кореляційний аналіз складається з трьох взаємопов'язаних блоків: формування кореляційної моделі зв'язку; розрахунок показників; статистична оцінка отриманої залежності.
Відбір ознак, які будуть включені в аналіз і встановлення форм зв'язку, передусім підбір математичного рівняння, що відображатиме цей зв'язок, складають основу першого і найбільш відповідального етапу кореляційного аналізу. Вибір ознак для включення їх у кореляційну модель ґрунтується на знанні теоретичних основ і практичному досвіді аналізу, що застосовується. За наявності достатньої інформації бажано, щоб кореляційна модель містила фактори, що мають безпосередній вплив на результативні показники, проте небажано включення в одну модель часткових і загальних чинників. Якщо дія одного фактора залежить від іншого, то це свідчить про наявність кореляції, яка може бути прямою і зворотною, або додатною й від'ємною.
При лінійній або криволінійній залежностях коефіцієнт кореляції (г) має додатній, або від'ємний знак, а при прямопропорційній залежності (г) має додатній знак, при зворотнопропорційній - від'ємний знак.
Числовий показник простої лінійної кореляції, який вказує на силу та напрямок зв'язку Х із У називається коефіцієнтом кореляції. Ця величина немає одиниць вимірювання, змінюється в межах від - 1 до + 1. Коефіцієнт кореляції розраховують за формулою:
г = ^ (Х-х)(У-у)/^ ^ (Х-х)2^ (у-У)2
Якщо коефіцієнт кореляції менше 0,3, то кореляційна залежність між ознаками слабка. Якщо він знаходиться в межах від 0,3 до 0,7, то кореляційна залежність середня, а якщо більше 0,7 - сильна.
Для оцінки надійності коефіцієнта кореляції вираховують його похибку та критерій достовірності.
Похибка коефіцієнта кореляції: Sr = 1-г2/п-2,
де: г - коефіцієнт кореляції;
п-2 - число ступенів свободи.
Критерій достовірності коефіцієнта кореляції:
1Г = г/8г,
де: Sг - похибка коефіцієнта кореляції
Якщо ^-ф^гг, то кореляційний зв'язок суттєвий, а коли - то не суттєвий
У статистичному аналізі поряд із встановленням залежності між мінливістю двох будь-яких ознак (х і у), тобто шляхом проведення кореляційного аналізу, широкого розповсюдження набув і регресійний аналіз. Коефіцієнт кореляції визначає лише певну ступінь зв'язку варіювання між будь-якими змінними величинами, а метод регресійного аналізу дозволяє встановити, як кількісно змінюється одна величина при зміні на будь-яку частину другої. Поряд з цим при вивченні багатьох існуючих методів встановлення зв'язку між будь-якими ознаками значення кореляції і регресії часто збігається в можливості описувати одні й ті ж явища, проте у більшості випадків дещо по-різному. Регресійний аналіз використовується з метою прогнозування зміни показників однієї величини пропорційно змінам інших. Проста лінійна регресія відображається у вигляді тренду, який краще всього відповідає аналізованим даним і розраховується за відповідним математичним рівнянням. У подальшому ці лінійні рівняння можна використовувати для прогнозування показників їх даних як у прямому, так і зворотному напрямах.
Найбільш яскраве застосування регресійного аналізу є графічне відображення взаємозв'язку показників у прямокутній системі координат, оскільки їх узагальнене зображення використовується для побудови закономірностей між досліджуваними показниками. Відображення отриманих даних у вигляді точок з подальшим проведенням прямої лінії дає можливість встановити вплив більшості даних, що вивчаються, і підсумовує загальну тенденцію відповідно системи координат та дозволяє виявити існуючі погрішності регресійного аналізу.
Для проведення прогнозування необхідно дослідити розподіл порівнюваних даних, в яких лінійний або поліномінальний регресивний аналіз суттєво спростовує оцінку в системах з їх багатогранним прогнозуванням.
Регресійний аналіз визначається трьома способами: шляхом визначення рівняння регресії, побудови емпіричних ліній регресії та визначення коефіцієнта регресії.
Теоретична та емпірична лінія регресії - це вирівняні лінії, які відображають найбільш точні прогнозні показники досліджуваних даних, тобто розрахункові похибки між вертикальною відстанню кожної точки даних до лінії регресії, які є найменшими.
При статистичній обробці експериментальних даних найбільш часто бувають випадки, коли регресія має нелінійний (криволінійний) характер. Тому множинна регресія при аналізі декількох чинників дозволяє обчислити дані, на які впливають більше одного контрольованого параметра.
Найбільш бажаною є встановлення функції (кривої) з мінімальним відхиленням від усіх точок рядів даних, оскільки ця функція краще за все відображає взаємозалежність зміни показників, яку одержують методом найменших квадратів, який припускає, що найбільш доречна крива даного типу - це крива, яка має мінімальну суму відхилень квадратів найменшої квадратичної похибки серед отриманого набору даних.
Число, яке показує в якому напрямку та на яку величину в середньому ознака У змінюється при зміні ознаки Х на одиницю вимірювання називається коефіцієнтом регресії. Коефіцієнт регресії розраховують за формулою:
вуХ = ^ (Х-х)(У-у)/ ^ (Х-х)2
ЛЕКЦІЯ № 10