Тема 7.2.1 Багатомірні моделі та сховища даних.
КОНТРОЛЬНІ ПИТАННЯ:
д/з скласти опорний конспект згідно списку та номеру самостійної роботи.
В основе концепции хранилища данных(ХД) лежит идея разделения данных, используемых для оперативной обработки и для решения задач анализа, что позволяет оптимизировать структуры хранения. ХД позволяет интегрировать ранее разъединенные детализированные данные, содержащиеся в исторических архивах, накапливаемых в традиционных OLTP-системах, поступающих из внешних источников, в единую базу данных, осуществляя их предварительное согласование и, возможно, агрегацию.
Основные характеристики хранилищ данных.
- содержит исторические данные;
- хранит подробные сведения, а также частично и полностью обобщенные данные;
- данные в основном являются статическими;
- нерегламентированный, неструктурированный и эвристический способ обработки данных;
- средняя и низкая интенсивность обработки транзакций;
- непредсказуемый способ использования данных;
- предназначено для проведения анализа;
- ориентировано на предметные области;
- поддержка принятия стратегических решений;
- обслуживает относительно малое количество работников руководящего звена.
Подсистема анализа может быть построена на основе:
1. подсистемы информационно-поискового анализа на базе реляционных СУБД и статических запросов с использованием языка SQL;
2. подсистемы оперативного анализа. Для реализации таких подсистем применяется технология оперативной аналитической обработки данных OLAP, использующая концепцию многомерного представления данных;
3. подсистемы интеллектуального анализа, реализующие методы и алгоритмы Data Mining.
В основе OLAP лежит понятие гиперкуба, или многомерного куба данных, в ячейках которого хранятся анализируемые данные.
Куб OLAP - это структура, в которой хранятся совокупности данных, полученные из базы данных OLAP путем всех возможных сочетаний измерений с фактами продаж в таблице фактов.
Оси куба представляют собой измерения, по которым откладывают параметры, относящиеся к анализируемой предметной области, например, названия товаров и названия месяцев года.
На пересечении осей измерений располагаются данные, количественно характеризующие анализируемые факты – меры, например, объемы продаж, выраженные в единицах продукции.
В многомерных БД для описания данных используется понятие многомерного пространства. В отличие от геометрического пространства многомерное пространство дискретно и содержит дискретное количество значений на каждом измерении. Пространство данных может иметь любое количество измерений.
Количество точек в пространстве данных образует теоретическое пространство данных. Размерность теоретического пространства математически определяется перемножением размеров всех измерений. Поскольку каждое измерение дискретно, то пространство является ограниченным (конечным).
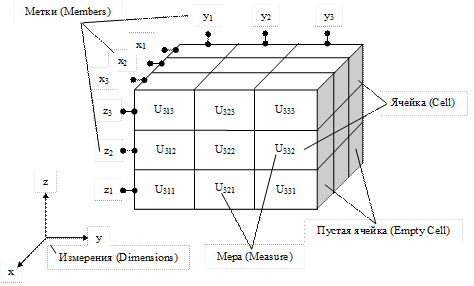
Багатомірна модель передбачає, що дані зберігаються не у вигляді плоских таблиць, як в реляційній БД, а у вигляді гіперкубів - впорядкованих багатомірних масивів. Багатомірне представлення даних тут реалізується фізично. Багатомірна СУБД забезпечує більш швидкий у порівнянні з реляційними системами пошук і читання даних. В цьому випадку немає потреби у багаторазовому з'єднанні таблиць. Такий підхід вимагає більше пам'яті для зберігання даних, при його використанні важко модифікувати структуру даних.
У багатомірній моделі розглядаються такі операції маніпулювання даними:
- переріз, який передбачає формування підмножини
гіперкуба, в якому значення одного або більшої
кількості вимірів є фіксованим;
- обертання, при якому змінюється порядок представлення вимірів;
- згорнення, передбачає заміну одного з вимірів іншим більш високого рівня ієрархії;
- деталізація - це операція зворотна до згорнення і забезпечує перехід від узагальнених даних до деталізованих.
Багатомірна СУБД краще за інші системи виконує складні нерегламентовані запити.
При створенні сховища даних однією з основних задач є визначення оптимальної структури зберігання даних з точки зору забезпечення прийнятного часу відповіді на аналітичні запити і потрібного об'єму пам'яті.
Всі дані в сховищі даних поділяються на такі категорії:
- детальні дані; агреговані дані; метадані.
Детальні дані — дані, які переносяться безпосередньо від оперативних джерел інформації . Вони відповідають елементарним подіям, що фіксуються в звичайних БД. Всі дані поділяються на виміри і факти. Вимірами називаються набори даних, які необхідні для опису подій (студенти, факультети і т.ін.). Вимір є аналогом домену в реляційній моделі. Виміри грають роль індексів для ідентифікації конкретних значень в комірках гіперкуба. Фактами називаються дані, які відображають сутність події (результати екзамену, кількість студентів і т.ін.). Непотрібні детальні дані можуть зберігатися в архівах у стислому вигляді.
Агреговані дані - дані, які отримують агрегуванням детальних даних по певних вимірах. Частина агрегованих даних безпосередньо зберігається в сховищі даних, а не обчислюється при виконанні запитів.
Метадані - це високорівневі засоби відображення інформаційної моделі. Метадані містять таку інформацію: опис структури даних сховища, структури даних, які імпортуються з різних джерел, відомості про періодичність імпортування, методах завантаження і узагальнення даних, засобах доступу і правилах представлення інформації, оцінки витрат часу на отримання відповіді на запит. Метадані знаходяться в репозиторії метаданих.
Метадані виконують такі функції:
- описують властивості інформаційної системи, її механізми й інформаційні ресурси в САSЕ-середовищах;
- використовуються для обміну відомостями між різними інструментами САSЕ і/або застосуваннями інформаційної системи;
- є джерелами відомостей про властивості і зміст інформаційних ресурсів для механізмів управління даними в інформаційних системах;
- забезпечують механізми інтеграції інформаційних ресурсів з різних джерел відомостями про властивості цих ресурсів;
- є джерелом інформації, яка необхідна для перебудови інформаційних систем;
- забезпечують представлення відомостей про систему, її ресурси для різних застосувань і користувачів.
Крім того САSЕ-інструментарій розширює і покращує якість взаємодії між адміністратором БД, прикладними програмістами і користувачами. Адміністратор БД за допомогою САSЕ -інструментарію може перевіряти схеми даних для застосувань, стежити за виконанням умов про найменування, дублювати елементи даних, перевіряти використання правил для елементів даних. САSЕ -засоби дозволяють каскадно передавати виправлення по всій інфраструктурі застосування, що значно спрощує роботу з впровадження системи БД.
Серед інструментальних САSЕ-систем розрізняють інтегровані комплекси інструментальних засобів для автоматизації всіх етапів життєвого циклу інформаційної системи і спеціалізовані інструментальні засоби для виконання окремих функцій
Сучасні САSЕ-системи є або структурними, або об'єктно-орієнтованими.
У структурному підході до аналізу та проектування застосовуються такі види моделей:
- DFD - діаграми потоків даних;
- SADТ - метод структурного аналізу і проектування - моделі і відповідні функціональні діаграми;
- ERD - діаграми "суть-зв'язок".
Діаграми потоків даних є основним засобом моделювання функціональних вимог /до системи, що проектується.
Специфікація процесів представляється у вигляді текстового опису, схем алгоритмів, псевдокодів і т.ін. Словник термінів являє собою короткий опис основних понять, які використовуються при створенні специфікації. Діаграма переходів станів демонструє поведінку системи, що розробляється. Моделювання даних виконується за допомогою ЕR-діаграм. Головна мета такого представлення - продемонструвати, як кожен процес перетворює свої вхідні дані у вихідні, а також виявити зв'язки між цими процесами.
Функціональні моделі SADТ призначені для опису функціональної структури системи, що проектується.
Послідовність проектування сховища даних показана на рис. 12.2.
Розмірності встановлюють контекст для пошуку відповідей на питання, що стосуються фактів в таблиці фактів. Вдало підібрані розмірності дозволяють зробити магазин даних зрозумілим і легким у використанні. Одна і та ж розмірність в різних магазинах даних повинна бути однаковою, або бути підмножиною іншої розмірності. Всі факти повинні бути визначені на відповідному рівні деталізації.
Існують інші підходи до створення сховища даних. Один з найбільш поширених передбачає декомпозицію проекту сховищ даних на магазини даних з подальшою інтеграцією інформації.
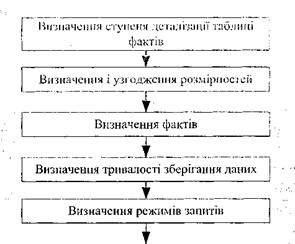
Рис. 12.2. Послідовність проектування сховища даних
При моделюванні сховищ даних використовуються концепції ЕR-моделювання з деякими обмеженнями. Для ER-моделі існує алгоритм однозначного перетворення її в реляційну модель даних. Кожна модель складається з таблиці зі складовим ключем, яка називається таблицею фактів, і набору невеликих таблиць, які називаються таблицями розмірностей, У таблиці фактів розміщуються дані, які найбільш інтенсивно використовуються для аналізу. Запис фактологічної таблиці відповідає комірці гіперкуба. У довідковій таблиці перелічені можливі значення одного з вимірів гіперкуба. Кожен вимір описується своєю власного таблицею.
Кожна таблиця розмірності має простий первинний ключ, який точно відповідає одному з компонентів складового ключа в таблиці фактів. Тобто первинний ключ таблиці фактів складається з декількох зовнішніх ключів. Така централізована структура називається схемою "зірка".
Помимо стандартных компонентов отображения данных в VCL Delphi имеются дополнительные компоненты, которые позволяют представлять данные в виде кросстаба. При этом заставить работать кросстаб с двумя и более полями почти так же просто, как и обычный компонент TDBGrid. Эти компоненты расположены на странице Decision Cube Палитры компонентов.
Кросстабом называется такое табличное представление данных, которое имеет переменную структуру по горизонтали и вертикали. Причем обозначения столбцов по вертикали и строк по горизонтали соответствуют значениям полей набора данных. В ячейках кросстаба содержатся не данные, а суммарные значения для двух полей, которые пересекаются в этой ячейке.
Понятие кросстаба
- для чего необходим кросстаб;
- особенности запросов SQL для многомерного представления;
- компоненты многомерного представления и их взаимосвязь.
Обычная таблица данных имеет строго заданное число столбцов, причем каждый столбец всегда предназначен для представления данных из одного поля. Для кросстаба число и назначение столбцов зависит от значений какого-либо поля. Число строк в кросстабе не равно числу строк в таблице БД, а также зависит от значений какого-либо поля. В ячейках кросстаба всегда располагается суммирующая информация по значениям полей горизонтали и вертикали
Создать подобную двумерную структуру отображения данных при помощи обычных компонентов со страницы Data Controls Палитры компонентов очень непросто и хлопотно.
В общем случае горизонтальную и вертикальную структуры кросстаба могут составлять несколько полей одновременно, которые сгруппированы относительно более общих полей.
Для создания наборов данных, которые можно представить в виде кросстаба, используются запросы SQL с применением группирующего оператора GROUP BY и агрегатных функций. Если обратиться к топологическим аналогиям, то набор данных такого запроса представляет собой многомерный гиперкуб, каждая сторона которого соответствует одному полю набора данных.
Совокупность строк или колонок, имеющих отношение к одному полю набора данных, будем называть размерностью. Размерность представляет собой виртуальную плоскость, которая рассекает многомерный куб данных параллельно какой-либо стороне этого куба. Компоненты многомерного представления данных как раз предназначены для того, чтобы визуализировать это n-мерное сечение.
Переходя от пространственных моделей к наборам данных, можно сказать, что размерность представляет собой совокупность значений какого-либо поля в кросстабе относительно других полей.
Взаимосвязь компонентов многомерного представления данных
При создании в приложении формы для многомерного представления данных следует помнить, что при этом обязательно должны решаться следующие задачи:
- должен быть создан группирующий и суммирующий запрос SQL, обеспечивающий открытие набора данных для кросстаба;
- перед отображением данных необходимо настроить параметры размерностей кросстаба;
- непосредственный показ данных в кросстабе;
- работающий кросстаб должен эффективно управляться на уровне размерностей.
Для этого в форме приложения требуется разместить как минимум пять компонентов со страницы Decision Cube Палитры компонентов.
Для создания запроса SQL можно использовать компонент TDecisionQuery или обычный компонент TQuery.
Запрос должен быть связан с компонентом TDecisionCube, который осуществляет подготовку набора данных запроса к многомерному показу.
Для соединения многомерного набора данных с компонентом отображения данных используется компонент TDecisionSource — полный функциональный аналог TDataSource. Этот компонент, в свою очередь, должен связываться и с набором данных, и с инструментом многомерного представления данных.
Непосредственный показ многомерного набора данных проводится при помощи компонентов TDecisionGrid и TDecisionGraph. Они должны поддерживать соединение с компонентом TDecisionSource.
Наконец, управление многомерным представлением данных реализует компонент TDecisionPivot, он также должен быть связан с компонентом TDecisionSource.
Допустим, что на форме расположены следующие компоненты:
- TDecisionQuery по имени DecisionQuery1;
- TDecisionCube по имени DecisionCubel;
- TDecisionSource по имени DecisionSourcel;
- TDecisionGrid по имени DecisionGrid1;
- TDecisionPivot по имени DecisionPivotl.
Тогда для того, чтобы связать все эти компоненты в единый работающий механизм многомерного представления данных, нужно установить значения для их важнейших свойств. Значения свойств представлены в табл. 30.1.
Таблица 30.1. Как связать компоненты многомерного представления данных
| Свойство | Значение | Описание |
| TBecisionCube | ||
| DataSet | DecisionQuery1 | Определяет компонент доступа к данным, который создает набор данных |
| TDecisionSource | ||
| DecisionCube | DecisionCubel | Указывает на компонент формирования многомерного набора данных |
| TDecisionGrid | ||
| DecisionSource | DecisionSourcel | Ссылается на компонент TDecisionSource |
| TDecisionPivot | ||
| DecisionSource | DecisionSourcel | Ссылается на компонент TDecisionSource |
Если задать текст запроса SQL и открыть набор данных, то вся цепочка заработает, причем ее поведение ничем не отличается от поведения во время выполнения приложения.
Теперь, когда мы узнали, как объединить компоненты многомерного представления данных в единую систему, настало время более подробно изучить возможности каждого компонента.
Подготовка набора данных
Компоненты многомерного представления данных работают со специально созданным и подготовленным набором данных. Эта работа выполняется специальным компонентом доступа к данным — TDecisionQuery. Его непосредственным предком является компонент TQuery.
Набор данных формируется при помощи запроса, который основан на стандартном синтаксисе SQL 92. Для обеспечения работы многомерного представления данных запрос должен удовлетворять ряду требований.
1. В тексте запроса должны присутствовать только те поля, которые разработчик хочет показать в компонентах многомерного представления данных.
2. Поля запроса должны быть сгруппированы при помощи оператора GROUP BY.
3. Запрос должен содержать агрегатные функции, которые определяют вид
информации, отображаемой в ячейках кросстаба.
Компонент TDecisionQuery должен только обеспечить выполнение запроса и создание набора данных, он не имеет никаких дополнительных свойств или методов. Поэтому для создания набора данных можно использовать и обычный компонент TQuery. Преимущество компонента TDecisionQuery состоит в том, что он имеет специализированный редактор для создания текста запроса (рис. 30.2). Он вызывается командой Decision Query Editor из всплывающего меню компонента или двойным щелчком на компоненте. Элементы управления страницы Dimensions/Summaries позволяют создавать текст запроса, манипулируя именами полей таблиц. Псевдоним базы данных выбирается в комбинированном списке Database. После этого в списке Table задается нужная таблица. Если в запросе требуется использовать несколько таблиц, то для их выбора можно воспользоваться утилитой SQL Builder, которая вызывается щелчком на одноименной кнопке.