Править]Потерянное обновление
Пример транзакции
Пример: необходимо перевести с банковского счёта номер 5 на счёт номер 7 сумму в 10 денежных единиц. Этого можно достичь, к примеру, приведённой последовательностью действий:
Начать транзакцию
прочесть баланс на счету номер 5
уменьшить баланс на 10 денежных единиц
сохранить новый баланс счёта номер 5
прочесть баланс на счету номер 7
увеличить баланс на 10 денежных единиц
сохранить новый баланс счёта номер 7
Окончить транзакцию
Эти действия представляют собой логическую единицу работы «перевод суммы между счетами», и таким образом, являются транзакцией. Если прервать данную транзакцию, к примеру, в середине, и не аннулировать все изменения, легко оставить владельца счёта номер 5 без 10 единиц, тогда как владелец счета номер 7 их не получит.
5. DDl & DМL
Data Definition Language (DDL) (язык описания данных) — это семейство компьютерных языков, используемых в компьютерных программах для описания структуры баз данных.
На текущий момент наиболее популярным языком DDL является SQL, используемый для получения и манипулирования данными в РСУБД, и сочетающий в себе элементы DDL, DML и DCL.
Функции языков DDL определяются первым словом в предложении (часто называемом запросом), которое почти всегда является глаголом. В случае с SQL эти глаголы — «create» («создать»), «alter» («изменить»), «drop» («удалить»). Это превращает природу языка в ряд обязательных утверждений (команд) к базе данных.
Языки DDL могут существенно различаться у различных производителей СУБД. Существует ряд стандартов SQL, установленный ISO/IEC (SQL-89,SQL-92, SQL:1999,SQL:2003, SQL:2008), но производители СУБД часто предлагают свои собственные «расширения» языка и, часто, не поддерживают стандарт полностью.
Это те операторы которые связанны с командами создания, например CREATE TABLE. Результатом выполнения этих операций заноситься в системный каталог, в котором хранятся сведения о таблицах.
DML - Data Manipulation Language. Это язык управления данными, с помощью которого можно извлекать и изменять данные. Есть две разновидности этих языков.
Procedural процедурный
Non Procedural непроцедурный
Разница между ними не такая как кажется на первый взгляд. Для программиста это типа есть процедуры, нет процедур. На самом деле процедурные языки обрабатывают данные последовательно. То есть запись за записью, а непроцедурные оперируют сразу целыми наборами. И разница отсюда видна, что в процедурных языках указывается, как нужно получать данные, а в непроцедурных, что мы хотим получить. Процесс в непроцедурном языке нас не волнует и он скрыт от разработчика. Наиболее распространенный непроцедурный язык это SQL. И тут должно стать понятно, что такое, когда мы указываем не путь, а результат. Оператор SQL типа SELECT * FROM TABLE говорит о результате, который хотим. А в данном случае мы хотим получить все записи и колонки из таблицы. Есть еще один не процедурный язык QBE. Давайте взглянем на это со стороны SQL. Итак, SQL это две части, первая часть для создание объектов в базе данных DDL, а вторая часть для манипуляции с данными в этих объектах DML. Зачем такое разделение? Проектирование базы данных задача далеко не простая и требует серьезной проработки. Есть специальные программы, которые помогают строить структуру данных, проверять связи, устранять противоречия на этапе проектирования. В результате работы этих программ формируется набор команд DDL ( в виде операторов SQL) которые запускаются на сервере баз данных и все структуры готовы к работе. Дальше начинается заполнение использую уже DML, и потом работа, опять используя DML (в виде операторов SQL).
МОДУЛЬ 2
1. Реляционная модель данных является удобной и наиболее привычной формой представления данных в виде таблицы. В отличие от иерархической и сетевой моделей, такой способ представления: 1) понятен пользователю-непрограммисту; 2) позволяет легко изменить схему – присоединять новые элементы данных и записи без изменения соответствующих подсхем; 3) обеспечивает необходимую гибкость при обработке непредвиденных запросов.
Одним из основных преимуществ реляционной модели является ее однородность.
Основными понятиями, с помощью которых определяется реляционная модель, являются следующие: домен, отношение, кортеж, кардинальность, атрибуты, степень, первичный ключ.
Домен – это совокупность значений, из которой берутся значения соответствующих атрибутов определенного отношения. С точки зрения программирования, домен – это тип данных, определяемый системой (стандартный) или пользователем.
Кортеж – таблица.
Кардинальность – количество строк в таблице.
Атрибут – поле, столбец таблицы.
Степень отношения – количество полей, столбцов.
Первичный ключ – это столбец или некоторое подмножество столбцов, которые уникально, т.е. единственным образом определяют строки.
Внешний ключ – это столбец или подмножество одной таблицы, который может служить в качестве первичного ключа для другой таблицы.
Модель предъявляет к таблицам следующие требования:
1.данные в ячейках таблицы должны быть структурно неделимыми;
2.данные в одном столбце должны быть одного типа;
3.каждый столбец должен быть уникальным (недопустимо дублирование столбцов);
4.столбцы размещаются в произвольном порядке;
5.строки размещаются в таблице также в произвольном порядке;
6.столбцы имеют уникальные наименования.
Для загрузки данных в хранилище данных, необходимо организовать реляционную базу данных в виде схемы звезда или снежинка. Как было сказано выше, схема снежинки позволяет уменьшить требования к объему данных, так как повторяющиеся данные выносятся в отдельную таблицу. Поэтому я выбрал именно схему снежинки. Реляционную базу данных я создал в MS Access, так как это более удобное, по сравнению с MS SQL Server, средство для создания и заполнения данными таблиц небольшой реляционной базы данных. Повторяющиеся данные выделены мной в отдельную таблицу Prod_class, в которой хранятся данные о подписных изданиях: название, тип, частота выхода, цена подписки. Измерения Время, Подписчики и Продукты строятся на основании таблиц Time, subscribers, products. Структура этих таблиц представлена в Таблице 3.
Таблица 3.Структура таблиц промежуточной БД
| Time | subscribers | products |
| Week | Name | Number |
| Month | Post_index | Weight |
| Quartal | City | Page_amount |
| Year | Street | Volume |
| Number | ||
| Tel | ||
| Fax | ||
| Tel_code | ||
Структура реляционной базы данных, построенной по схеме снежинки представлена на Рис. 6.1.
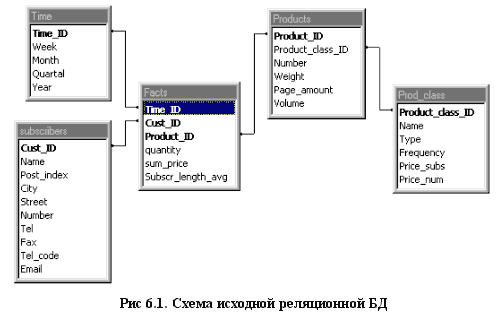
После этого можно приступать к загрузке данных в БД, построенную по схеме снежинки. Сначала заполняется «справочная» таблица, в нашем примере – это Prod_class, далее заполняется данными таблица Products, таблиц subscribers и Time, а потом заполняется данными таблица Facts.
2. сетевая модель данных — логическая модель данных, являющаяся расширением иерархического подхода, строгая математическая теория, описывающая структурный аспект, аспект целостности и аспект обработки данных в сетевых базах данных.
Разница между иерархической моделью данных и сетевой состоит в том, что в иерархических структурах запись-потомок должна иметь в точности одного предка, а в сетевой структуре данных у потомка может иметься любое число предков.
Сетевая БД состоит из набора экземпляров определенного типа записи и набора экземпляров определенного типа связей между этими записями.
Тип связи определяется для двух типов записи: предка и потомка. Экземпляр типа связи состоит из одного экземпляра типа записи предка и упорядоченного набора экземпляров типа записи потомка. Для данного типа связи L с типом записи предка P и типом записи потомка C должны выполняться следующие два условия:
· каждый экземпляр типа записи P является предком только в одном экземпляре типа связи L;
· каждый экземпляр типа записи C является потомком не более чем в одном экземпляре типа связи L.
Примерный набор операций манипулирования данными:
· найти конкретную запись в наборе однотипных записей;
· перейти от предка к первому потомку по некоторой связи;
· перейти к следующему потомку в некоторой связи;
· перейти от потомка к предку по некоторой связи;
· создать новую запись;
· уничтожить запись;
· модифицировать запись;
· включить в связь;
· исключить из связи;
· переставить в другую связь и т. д.
3. Иерархическая модель данных — представление базы данных в виде древовидной (иерархической) структуры, состоящей из объектов (данных) различных уровней.
Между объектами существуют связи, каждый объект может включать в себя несколько объектов более низкого уровня. Такие объекты находятся в отношении предка (объект более близкий к корню) к потомку (объект более низкого уровня), при этом возможна ситуация, когда объект-предок не имеет потомков или имеет их несколько, тогда как у объекта-потомка обязательно только один предок. Объекты, имеющие общего предка, называются близнецами.
Например, если иерархическая база данных содержала информацию о покупателях и их заказах, то будет существовать объект «покупатель» (родитель) и объект«заказ» (дочерний). Объект «покупатель» будет иметь указатели от каждого заказчика к физическому расположению заказов покупателя в объект «заказ».
В этой модели запрос, направленный вниз по иерархии, прост (например: какие заказы принадлежат этому покупателю); однако запрос, направленный вверх по иерархии, более сложен (например, какой покупатель поместил этот заказ). Также, трудно представить не-иерархические данные при использовании этой модели.
Иерархической базой данных является файловая система, состоящая из корневого каталога, в котором имеется иерархия подкаталогов и файлов.
Основными информационными единицами в иерархической модели данных являются сегмент и поле. Поле данных определяется как наименьшая неделимая единица данных, доступная пользователю. Для сегмента определяются тип сегмента и экземпляр сегмента. Экземпляр сегмента образуется из конкретных значений полей данных. Тип сегмента — это поименованная совокупность входящих в него типов полей данных.
Как и сетевая, иерархическая модель данных базируется на графовой форме построения данных, и на концептуальном уровне она является просто частным случаем сетевой модели данных. В иерархической модели данных вершине графа соответствует тип сегмента или просто сегмент, а дугам — типы связей предок — потомок. В иерархических структуpax сегмент — потомок должен иметь в точности одного предка.
Иерархическая модель представляет собой связный неориентированный граф древовидной структуры, объединяющий сегменты. Иерархическая БД состоит из упорядоченного набора деревьев.
В рамках иерархической модели выделяют языковые средства описания данных (ЯОД) и средства манипулирования данными (ЯМД). Каждая физическая база описывается набором операторов, обусловливающих как её логическую структуру, так и структуру хранения БД. При этом способ доступа устанавливает способ организации взаимосвязи физических записей.
Определены следующие способы доступа:
· иерархически последовательный;
· иерархически индексно-последовательный;
· иерархически прямой;
· иерархически индексно-прямой;
· индексный.
Помимо задания имени БД и способа доступа описания должны содержать определения типов сегментов, составляющих БД, в соответствии с иерархией, начиная с корневого сегмента. Каждая физическая БД содержит только один корневой сегмент, но в системе может быть несколько физических БД.
Среди операторов манипулирования данными можно выделить операторы поиска данных, операторы поиска данных с возможностью модификации, операторы модификации данных. Набор операций манипулирования данными в иерархической БД невелик, но вполне достаточен.
6. Уровень изолированности транзакций — значение, определяющее уровень, при котором в транзакции допускаются несогласованные данные, то есть степень изолированности одной транзакции от другой. Более высокий уровень изолированности повышает точность данных, но при этом может снижаться количество параллельно выполняемых транзакций. С другой стороны, более низкий уровень изолированности позволяет выполнять больше параллельных транзакций, но снижает точность данных.
При параллельном выполнении транзакций возможны следующие проблемы:
· потерянное обновление (англ. lost update) — при одновременном изменении одного блока данных разными транзакциями, одно из изменений теряется;
· «грязное» чтение (англ. dirty read) — чтение данных, добавленных или изменённых транзакцией, которая впоследствии не подтвердится (откатится);
· неповторяющееся чтение (англ. non-repeatable read) — при повторном чтении в рамках одной транзакции, ранее прочитанные данные оказываются изменёнными или удалёнными;
· фантомное чтение (англ. phantom reads) — при повторном чтении в рамках одной транзакции прочитаны данные(новые "фантомные" строки), которых при предыдущих чтениях не было, хотя они удовлетворяли условиям отбора предыдущего чтения.
Рассмотрим ситуации, в которых возможно возникновение данных проблем.
править]Потерянное обновление
Предположим, имеются две транзакции, в которых одновременно выполнены следующие SQL-операторы:
| Транзакция 1 | Транзакция 2 |
| UPDATE tbl1 SET f2=f2+20 WHERE f1=1; | UPDATE tbl1 SET f2=f2+25 WHERE f1=1; |
Можно было бы предположить, что одновременное выполнение команд "увеличить текущее значение на 20" и "увеличить текущее значение на 25" может привести к выполнению только одной из этих команд, которая сотрёт результат выполнения другой. Но такого никогда не происходит, при попытках одновременного изменения одного и того же данного СУБД останавливает выполнение одной из команд, чтоб добиться их последовательного выполнения, и в результате, значение увеличивается на 45.
Править]«Грязное» чтение
Предположим, имеются две транзакции, открытые различными приложениями, в которых выполнены следующие SQL-операторы:
| Транзакция 1 | Транзакция 2 |
| SELECT f2 FROM tbl1 WHERE f1=1; | |
| UPDATE tbl1 SET f2=f2+1 WHERE f1=1; | |
| SELECT f2 FROM tbl1 WHERE f1=1; | |
| ROLLBACK WORK; |
В транзакции 1 изменяется значение поля f2, а затем в транзакции 2 выбирается значение этого поля. После этого происходит откат транзакции 1. В результате значение, полученное второй транзакцией, будет отличаться от значения, хранимого в базе данных.