Реализация уровней изоляции и свойств ACID
Полноценная реализация представляет собой нетривиальную задачу. Обработка поступающих данных приводит к большому количеству маленьких изменений, включая обновление как самих таблиц, так и индексов. Эти изменения потенциально могут потерпеть неудачу: закончилось место на диске, операция занимает слишком много времени (timeout) и т. д. Система должна в случае неудачи корректно вернуть базу данных в состояние до транзакции.
Первые коммерческие СУБД (к примеру, IBM DB2), пользовались исключительно блокировкой доступа к данным для обеспечения свойств ACID. Но большое количество блокировок приводит к существенному уменьшению производительности. Есть два популярных семейства решений этой проблемы, которые снижают количество блокировок:
· журнализация изменений (write ahead logging, WAL);
· механизм теневых страниц (shadow paging).
Одно из основных требований к любой системе управления базами данных состоит в том, что СУБД должна надежно хранить базы данных. Это означает, что СУБД должна поддерживать средства восстановления состояния баз данных после любых возможных сбоев. К таким сбоям относятся индивидуальные сбои транзакций (например, деление на ноль в прикладной программе, инициировавшей выполнение транзакции); сбой процессора при работе СУБД (так называемые мягкие сбои) и сбои (поломки) внешних носителей, на которых расположены базы данных (жесткие сбои).
Ситуации, возникающие при сбоях каждого из отмеченных классов, различны и, вообще говоря, требуют разных подходов к организации восстановления баз данных. Индивидуальные сбои транзакций означают, что все изменения, произведенные в базе данных некоторой транзакцией, незаконны, и их необходимо устранить. Для этого необходимо выполнить индивидуальный откат транзакции.
При возникновении мягкого сбоя системы утрачивается содержимое оперативной памяти. Восстановление состояния базы данных состоит в том, что после его завершения база данных должна содержать все изменения, произведенные транзакциями, закончившимися к моменту сбоя, и не должна содержать ни одного изменения, произведенного транзакциями, которые к моменту сбоя не закончились. Существенным аспектом ситуации является то, что состояние базы данных на внешней памяти не разрушено, что позволяет сделать процесс восстановления не слишком длительным.
Жесткие сбои приводят к полной или частичной потере содержимого баз данных на внешней памяти. Тем не менее цель процесса восстановления та же, что и в случае мягкого сбоя: после завершения этого процесса база данных должна содержать все изменения, произведенные транзакциями, закончившимися к моменту сбоя, и не должна содержать ни одного изменения, произведенного транзакциями, не закончившимися к моменту сбоя. В случае жесткого сбоя единственно возможный подход к восстановлению состояния базы данных может быть основан на использовании ранее произведенной копии базы данных. В общем случае процесс восстановления после жесткого сбоя существенно более накладен, чем после мягкого сбоя.
·
Журнализация транзакций
Реализация в СУБД принципа сохранения промежуточных состояний, подтверждения или отката транзакции обеспечивается специальным механизмом, для поддержки которого создается некоторая системная структура, называемая Журналом транзакций.
В простейшем случае журнализация изменений заключается в последовательной записи во внешнюю память всех изменений, выполняемых в базе данных. Записывается следующая информация:
· порядковый номер, тип и время изменения;
· идентификатор транзакции;
· объект, подвергшийся изменению (номер хранимого файла и номер блока данных в нём, номер строки внутри блока);
· предыдущее состояние объекта и новое состояние объекта.
Журнал изменений может не записываться непосредственно во внешнюю память, а аккумулироваться в оперативной. В случае подтверждения транзакции СУБД дожидается записи оставшейся части журнала на внешнюю память. Таким образом, гарантируется, что все данные, внесённые после сигнала подтверждения, будут перенесены во внешнюю память, не дожидаясь переписи всех измененных блоков из дискового кэша.
В случае логического отказа или сигнала отката одной транзакции журнал сканируется в обратном направлении, и все записи отменяемой транзакции извлекаются из журнала вплоть до отметки начала транзакции. Согласно извлеченной информации выполняются действия, отменяющие действия транзакции, а в журнал записываются компенсирующие записи. Этот процесс называется откат (rollback).
Если ни журнал, ни сама база данных не повреждена, то выполняется процесс прогонки (rollforward). Журнал сканируется в прямом направлении, начиная от предыдущей контрольной точки. Все записи извлекаются вплоть до конца журнала. Извлеченная из журнала информация вносится в блоки данных внешней памяти, у которых отметка номера изменений меньше, чем записанная в журнале. Если в процессе прогонки снова возникает сбой, то сканирование журнала вновь начнется сначала, но фактически восстановление продолжится с той точки, откуда оно прервалось.
Сервер ведёт 2 вида журналов транзакций.
Undo-журналы: используются для отката и ведутся для каждой транзакции отдельно. Как только очередная транзакция зафиксирована или откачена, то информация из соответствующего Undo-журнала удаляется. В Oracle такие журналы иначе называются сегментами отката, они располагаются в отдельном табличном пространстве и содержат полную информацию о каждой транзакции, достаточную для ее успешного отката. Рекомендуемое количество Undo журналов в базе данных, которые должны быть в наличии, равно n/2 (где n - количество одновременно работающих пользователей).
Redo-журнал: необходим для повторного выполнения транзакций при восстановлении данных. Это единый системный журнал, в который записываются результаты всех зафиксированных транзакций. В аварийной ситуации, приведшей к порче данных, они восстанавливаются по резервной копии. Но резервная копия была снята в какой-то момент времени в прошлом. Все транзакции, которые прошли в системе после снятия последней резервной копии, восстанавливаются по Redo- журналу.
Такой механизм полностью гарантирует выполнение правила Надежность из аббревиатуры ACID. Для того чтобы гарантировать возможность безусловного восстановления всех зафиксированных транзакций, принято правило упреждающей записи в журнал транзакций - по команде COMMIT результаты транзакции сначала заносятся в Redo-журнал, а потом (возможно не сразу), записываются в табличное пространство.
Механизм теневых страниц
Теневой механизм используется для обеспечения наличия точек физической согласованности БД.
При открытии файла таблица отображения номеров его логических блоков в адреса физических блоков внешней памяти считывается в оперативную память. При модификации любого блока файла во внешней памяти выделяется новый блок. При этом текущая таблица отображения (в оперативной памяти) изменяется, а теневая сохраняется неизменной. Если во время работы с открытым файлом происходит сбой, во внешней памяти автоматически сохраняется состояние файла до его открытия. Для явного восстановления файла достаточно повторно считать в оперативную память теневую таблицу отображения. Общая идея теневого механизма показана на рис. 1.
|
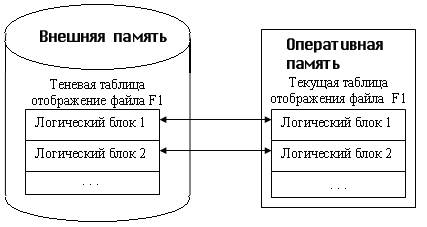
В контексте БД теневой механизм используется следующим образом. Периодически выполняются операции установления точек физической согласованности БД (checkpoints). Для этого все логические операции завершаются, все буферы оперативной памяти, содержимое которых не соответствует содержимому соответствующих страниц внешней памяти, выталкиваются. Теневая таблица отображения файлов БД заменяется на текущую (правильнее сказать, текущая таблица отображения записывается на место теневой).
Восстановление к точкам физической согласованности БД происходит мгновенно: текущая таблица отображения заменяется на теневую (при восстановлении просто считывается теневая таблица отображения). Все проблемы восстановления решаются, но за счет слишком большого перерасхода внешней памяти. В пределе может потребоваться вдвое больше внешней памяти, чем реально нужно для хранения базы данных. Теневой механизм – это надежное, но слишком грубое средство. Обеспечивается согласованное состояние внешней памяти в один общий для всех объектов момент времени. На самом деле достаточно иметь совокупность согласованных наборов страниц, каждому из которых может соответствовать свои временные отсчеты.