Алгоритм розрахунку тренду
ЛАБОРАТОРНА РОБОТА № 1
АНАЛІЗ ТИМЧАСОВОГО РЯДУ І РОЗРАХУНОК ЛІНІЇ ТРЕНДА
Мета роботи: отримати відомості та навички роботи з основними елементами тимчасового ряду. Навчитися основним прийомам розрахунків тренду, індексів сезонності.
План
1. Розрахунок лінії тренду.
2. Розрахунок сезонної варіації.
3. Побудова лінії тренду та розрахунок прогнозних значень.
Теоретичні відомості.
Основу екстраполяційних методів прогнозування становлять динамічні ряди.
Динамічний ряд (часовий ряд) – це ряд спостережень (наглядів), що проводився регулярно через рівні інтервали часу. За часом, відображеним у динамічних рядах, їх поділяють на моментні та інтервальні. В моментних рядах динаміки рівні відображають величину явища на певну дату, наприклад, залишки готової продукції станом на перше число кожного місяця, вартість основних фондів на початок чи кінець року. В інтервальних рядах вони виражають розміри явищ за проміжок часу, наприклад, випуск продукції за місяць, квартал, рік.
При побудові динамічних рядів слід звернути увагу найперше на порівнянність рівнів ряду, а саме –всі рівні повинні виражатися в однакових одиницях виміру, розраховуватися по єдиній методології, включати єдине коло об’єктів.
При аналізі часового ряду великої тривалості, наприклад, за ряд років, можна помітити циклічні коливання. Це так званий цикл ділової активності, або економічний цикл, що складається з економічного підйому (буму), спаду, депресії та пожвавлення. Цей цикл повторюється регулярно. Важливо зрозуміти, що будь-який бізнес випробовує вплив процесів, що відбуваються в економіці в цілому, і тому їх потрібно враховувати при складанні довгострокового прогнозу. Проте при довгостроковому прогнозуванні можна нехтувати циклічною складовою ряду.
Важливим компонентом часового ряду є залишкова варіація, яка залишається після того, як інші складові ряду відокремлені. Залишкова варіація може бути двох типів:
¨ Аномальна варіація розглядає неприродне велике відхилення тимчасового ряду, яке надає дію на одиничний нагляд (наприклад, побоювання з приводу зараженості продукту харчування можуть призвести до тимчасового скорочення обсягу продажів). Випадкові явища неможливо передбачити наперед, і ми повинні мати на увазі, що подібні події можуть мати місце, і слід також враховувати їх при аналізі діяльності компанії і мати нагоду відповідним чином скорегувати наш прогноз у разі потреби;
¨ Випадкова варіація враховує малі відхилення, які неможливо передбачити і які в довгостроковій перспективі з рівною вірогідністю можуть як понизити, так і збільшити обсяг продажів. Проте ми не можемо пояснити абсолютно всі варіації обсягу продажів в кожному кварталі: в деяких кварталах обсяг продажів може бути трохи нижче, в інших – трохи вище, ніж очікувалося, причому без видимих причин.
В процесі господарської діяльності окремі галузі промисловості, торгівля, сфера послуг стикаються з циклічними коливаннями, викликаними сезонним характером виробництва та споживання товарів та послуг. Сезонні коливання розглядаються, як коливання в ряді динаміки, що обумовлені специфічними умовами виробництва і споживання даного товару чи послуги. Для організації виробництва і реалізації продукції сезонних виробництв надзвичайно важливо вивчити тенденцію сезонних коливань, що склалася, і розробити прогноз на найближчу перспективу, головним чином на наступний рік.
Для вивчення сезонних коливань використовуються показники, які називаються індексами сезонності, а їх сукупність утворює сезонну хвилю.
Для аналізу тенденції на основі динамічних рядів і побудови прогнозу з врахуванням закономірностей використовують рівняння тренда.
Слід мати на увазі, що частіше в роботі розглядаються стохастичні (ймовірні) залежності. У функціональній залежності кожному значенню аргументу відповідає одне єдине значення функції, а в стохастичній закономірності значенню аргументу відповідає не одне, а декілька значень, тобто певний розподіл цих значень. Стохастичні залежності частіше мають місце у реальному житті, і з ряду причин не можуть бути враховані всі фактори. Тому рівняння, що ґрунтується на стохастичних залежностях, складається з двох частин: детермінованої, яка формується під впливом врахованих факторів, і випадкової, яка виникає у результаті випадкових неврахованих факторів.
Тренд відображає усереднені тенденції зміни явища у часі. Припускається, що через фактор часу можна виразити впливи усіх основних факторів, іншими словами, хоча час не являється механізмом прояву закономірностей і тенденцій, він мовби акумулює дії основних факторів і виражає їх у рівнянні тренда. Реальний механізм впливу на значення рівнів динамічного ряду у наявному виді не враховується.
Аналітичне вимірювання тренда – це досить поширений метод прогнозування. Екстраполяція тренда може бути застосована лише у тому випадку, якщо розвиток явища досить добре описується побудованими рівняннями і умови, які визначаються тенденцію розвитку у минулому, не зазнаються значних змін у майбутньому. При дотриманні цих умов екстраполяція здійснюється шляхом підстановки у рівнянні тренда значення незалежної змінної t, яка відповідає величині горизонту прогнозування.
Рівняння тренда може бути описане широким спектром залежностей, зокерма:
¨ лінійна у = a0 + at;
¨ квадратична у = a0 + a1t + a2t2;
¨ степенева у = a0 ta1 ;
¨ показникові у = a0 a1t ;
¨ експоненційна у = a0 la1t ;
¨ експоненційно-степенева у = a0 ta1 la2t ;
¨ логістична у = a0 : (1 + a1la2t) ;
¨ гіперболічна у = a0 + (a1 : t).
Вибір виду рівняння проводять за допомогою зображення динамічного ряду на графіку. По виду графіка можна визначити, чи є показник, що досліджується, монотонно зростаючим, чи має точку перетину, чи є циклічним, чи спостерігається процес насичення і т.д.
При виборі виду рівняння необхідно вирішити два питання. По-перше, чи адекватно рівняння відповідає досліджуваним процесам, а у відношенні часового тренда – наскільки воно відображає закономірність тенденції, що склалася. По-друге, чи відповідає воно статистичним критеріям. Ці два питання повинні дати відповідь – наскільки логічно і статистично відібране рівняння відповідає процесам і явищам, що досліджуються.
Заключним етапом розробки прогнозу є верифікація, яка Є процедурою оцінки достовірності, точності чи обґрунтованості прогнозу. Показники, які використовуються для оцінки точності прогнозу, можна розділити на три групи: абсолютні, порівняльні і якісні.
До абсолютних показників відносяться:
¨ різниця між фактичними і прогнозними значеннями;
¨ середня помилка прогнозу;
¨ відносна помилка прогнозу;
¨ середня відносна помилка прогнозу;
¨ середня квадратична абсолютна помилка прогнозу.
Вибір показників точності прогнозу залежить від об'єкта прогнозування і тих задач, які ставить перед собою дослідник у відношенні точності прогнозу. Збіг точкового прогнозу з фактичними даними малоймовірний. Тому в прогнозуванні використовуються інтервальні значення прогнозу у вигляді „вилки" - максимальна і мінімальна величина. Наявність мінімального і максимального значення прогнозного показника дозволяє по суті розробити альтернативні варіанти стратегії дій підприємства з врахуванням можливих ситуацій на ринку.
Хід роботи
Задача.
За представленими щоквартальними обсягами продажів у магазині «Кроха» (таблиця 1.1), необхідно зробити розрахунок прогнозу на 2010 рік. Запропонуйте варіанти стратегії дій магазину з урахуванням можливих ситуацій на ринку.
Таблиця 1.1
Обсяги продажів у магазині дитячого одягу „Кроха", тис.грн.
| Рік | Квартал 1 | Квартал 2 | Квартал 3 | Квартал 4 |
Для вирішення цієї задачі необхідно виконати ряд розрахунків:
¨ розрахунок лінії тренду;
¨ розрахунок сезонної варіації;
¨ побудувати лінію тренда.
Алгоритм розрахунку тренду
1.1. Вводимо дані в клітинки А і В. Вид робочого листа з введеними початковими даними показаний у таблиці 2. Не забудьте ввести в клітинку В2розмірність даного ряду (тис. грн.).
1.2. Вводимо формули для розрахунку чотирьохквартальної ковзної середньої в клітинку С6: = SUМ(В4:В7)/4.
Скопіюйте цю формулу вниз аж до клітинки С18. Відформатуйте стовпець з точністю до другого десяткового знака.
Перша розрахована нами середня показує середній обсяг продажів за перший рік і ми розмістимо її у третьому кварталі 2006 р., оскільки ця величина ближче до даних цього кварталу. Середню за наступні чотири квартали необхідно поставити в четвертий квартал.
1.3. Знаходимо суму двох сусідніх значень. В клітинку D6вводимо формулу: =С6+С7.
1.4. Центруємо набуті значення, в клітинку Е6вводимо формулу: =D6/2 і копіюємо її вниз до клітки Е17.
Центрована середня і є значенням розрахованого нами тренда.
Розрахунки представлені в стовпці Е, округляємо з точністю до одного десяткового знака.
Якщо усереднювання відбувається з розрахунку на парне число періодів часу, наприклад на чотири квартали року або на 12 місяців, необхідне центрування тренда, оскільки чотириквартальна середня або 12-місячна середня потрапляють відповідно посередині між двома кварталами або двома місяцями. Проте, якщо усереднювання проводиться на непарну кількість інтервалів, наприклад, сім днів тижня, то центрування не потрібне, оскільки семиденна середня відповідає одному з днів тижня.
Таблиця 1.2
Розрахунок прогнозу обсягу продажів у магазині
дитячого одягу «Кроха», тис. грн
| А | В | С | D | Е | F |
| Період (рік/квартал) | Обсяг продажів тис. грн. | Ковзна середня за 4 квартали | Сума двох сусідніх значень | Центрована середня, тренд, тис. грн. | Витрати /Тренд * 100 |
| 2006/1 | |||||
| 2006/2 | |||||
| 2006/3 | 94,0 | 189,0 | 94,5 | 84,7 | |
| 2006/4 | 95,0 | 191,3 | 95,6 | 164,2 | |
| 2007/1 | 96,3 | 194,0 | 97,0 | 70,1 | |
| 2007/2 | 97,8 | 199,0 | 99,5 | 80,4 | |
| 2007/3 | 101,3 | 202,5 | 101,3 | 84,9 | |
| 2007/4 | 101,3 | 203,3 | 101,6 | 167,3 | |
| 2008/1 | 102,0 | 205,3 | 102,6 | 67,2 | |
| 2008/2 | 103,3 | 211,0 | 105,5 | 78,7 | |
| 2008/3 | 107,8 | 216,3 | 108,1 | 84,2 | |
| 2008/4 | 108,5 | 217,8 | 108,9 | 172,7 | |
| 2009/1 | 109,3 | 220,0 | 110,0 | 65,5 | |
| 2009/2 | 110,8 | 225,0 | 112,5 | 76,4 | |
| 2009/3 | 114,3 | ||||
| 2009/4 | |||||
| Сезонна варіація | |||||
| Рік | Квартал 1 | Квартал 2 | Квартал 3 | Квартал 4 | |
| 84,7 | 164,2 | ||||
| 70,1 | 80,4 | 84,9 | 167,3 | ||
| 67,2 | 78,7 | 84,2 | 172,7 | ||
| 65,5 | 76,4 | Разом | |||
| Нескоректована середня | 67,6 | 78,5 | 84,6 | 168,0 | 398,7 |
| Скоректована середня | 67,6 | 78,8 | 84,9 | 168,6 | 400,0 |
| Прогноз тренда, тис.грн. | Квартал 1 | Квартал 2 | Квартал 3 | Квартал 4 | |
| 2010 рік | 117,0 | 118,5 | 120,0 | 121,5 | |
| Сезонний чинник, % | 67,6 | 78,8 | 84,9 | 168,6 | |
| Прогноз обсягу продаж на 2010р, тис.грн. | 79,0 | 93,3 | 101,8 | 204,8 |
2. Алгоритм дій по розрахунку сезонної варіації
2.1. В стовпці F розрахуємо значення тимчасового ряду, які очищені від трендової складової, це і є індексом сезонності. Для цього треба виділити клітку F6 і ввести в неї формулу: = В6/Е6х100
Скопіюйте цю формулу вниз до клітки F17. Відформатуйте ці клітки з точністю до одного десяткового знаку.
2.2. Для усереднення сезонних компонентів перейдіть в іншу частину електронної таблиці, скажімо, в клітку А30 і побудуйте нову таблицю для проведення обчислень. Спершу введіть мітки рядків (роки), потім — мітки стовпців (квартали). Замість того щоб вводити всі значення із стовпця F, простіше ввести адреси комірок, так щоб =F6 було надруковано в комірці DЗ1, =F7 — в комірці ЕЗ1, =F8 — в комірці В32, =F9 — в комірці С32 і так далі до комірки F17.
2.3. Знаходимо середні значення по кожному стовпцю. Введемо в комірку В35 формулу: = СРЗНАЧ(В32 : В34).
Ту ж операцію слід повторити для стовпців С, D і Е, слід звернути увагу на те, щоб в кожну середню були включені відповідні дані комірок, оскільки в кожному стовпці розміщення даних неоднакове.
Аналізуємо по черзі дані за кожний квартал і встановлюємо, наскільки вони в середньому більше або менше значення тренда, таким чином розраховуємо нескоректовані середні. При розрахунку враховуємо, що нескоректовані середні містять як сезонну, так і залишкову варіацію. Нас же цікавить тільки сезонна варіація, так що ми повинні скоректувати середні для видалення елемента залишкової варіації. В довгостроковому плані величина перевищення обсягу продажів над трендом у вдалі квартали повинна зрівнюватися з величиною, на яку обсяг продажів нижче за тренд у невдалі квартали, щоб сезонні компоненти в сумі складали б приблизно 400 (за даними цієї задачі).
2.4. В комірку F35 вводимо формулу: = SUM(В35 : Е35).
Ви побачите, що нескоректовані середні в даному прикладі в сумі складають 398,8. Ми повинні помножити кожне середнє значення на коректуючий коефіцієнт, щоб в сумі середні давали 400.
2.5. Сума сезонної варіації, розрахована по кварталах, повинна дорівнювати 400. Для коректування компонентів пересуньтеся в комірку В36 і введіть формулу:
= В35 х 400/$F$35.
2.6. Скопіюйте формулу аж до комірки F36 і перевірте, що значення в комірці F36 тепер дорівнює 400.
Дані в комірках з В36 до Е36 є сезонними варіаціями.
Готовий робочий лист повинен виглядати так, як показано у таблиці 3, в режимі демонстрації формул.
Таблиця 1.3
Вигляд робочого листа в режимі демонстрації формул
| А | В | С | D | Е | F | |
| Період Рік/ Квартал | Обсяг продажі в тис. грн. | 4-квартальна ковзна середня | Сума двох сусідніх значень | Центрована середня (тренд), тис. грн. | Обсяг продажів/ Тренд х 100 | |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 2006/1 | ||||||
| /2 | ||||||
| /3 | = SUM (B4:B7)/4 | = C6+C7 | =D6/2 | =B6/E6*100 | ||
| /4 | = SUM (B5:B8)/4 | = C7+C8 | =D7/2 | =B7/E7*100 | ||
| 2007/1 | = SUM (B6:B9)/4 | = C8+C9 | =D8/2 | =B8/E8*100 | ||
| /2 | = SUM (B7:B10)/4 | = C9+C10 | =D9/2 | =B9/E9*100 | ||
| /3 | = SUM (B8:B11)/4 | =C10+C11 | =D10/2 | =B10/E10*100 | ||
| /4 | = SUM (B9:B12)/4 | =C11+C12 | =D11/2 | =B11/E11*100 | ||
| 2008/1 | = SUM (B10:B13)/4 | =C12+C13 | =D12/2 | =B12/E12*100 | ||
| = SUM (B11:B14)/4 | =C13+C14 | =D13/2 | =B13/E13*100 | |||
| /3 | = SUM (B12:B15)/4 | =C14+C15 | =D14/2 | =B14/E14*100 | ||
| /4 | = SUM (B13:B16)/4 | =C15+C16 | =D15/2 | =B15/E15*100 | ||
| 2009/1 | = SUM (B14:B17)/4 | =C16+C17 | =D16/2 | =B16/E16*100 | ||
| /2 | = SUM (B15:B18)/4 | =C17+C18 | =D17/2 | =B17/E17*100 | ||
| /3 | = SUM (B16:B19)/4 | |||||
| /4 | ||||||
| Рік | Квартал 1 | Квартал 2 | Квартал 3 | Квартал 4 | ||
| = F6 | = F7 | |||||
| = F8 | = F9 | = F10 | = F11 | |||
| = F12 | = F13 | = F14 | = F15 | |||
| = F16 | = F17 | Всього | ||||
| Нескоректо-вана середня | =СРЗНАЧ (B32:B34) | =СРЗНАЧ (C32:C34) | =СРЗНАЧ (D31:D33) | =СРЗНАЧ (E31:E33) | = SUM (B35:E35) | |
| Скоректова-на середня | =B35*400/ $F$35 | =C35*400/$F$35 | =D35*400/ $F$35 | =E35*400/ $F$35 | =F35*400/$F$35 |
За цими прогнозами можна зробити припущення, що динаміка тренда збережеться незмінною у порівнянні з минулими періодами, а при цьому сезонна варіація збереже свою поведінку. Якщо ми допустимо, що це припущення може виявитися невірним, то доведеться внести корективи в прогноз, враховуючи експертну очікувану зміну ситуації. Наприклад, на ринок проникне інший великий роздрібний торговець одягом і зіб'є наші ціни — тренд обсягу продажів зміниться і нам доведеться відповідно змінити наш прогноз.
3. Алгоритм дій із побудови лінії тренда
Виділіть стовпці для побудови діаграми.
3.1.Клацніть на кнопці Мастер диаграмм,розташований на стандартній панелі інструментів, або виберіть команду Вставка - Диаграмма.
3.3. На першому кроці виберіть тип діаграми Графикі клацніть на кнопці Далее.
3.4. На другому кроці роботи засобу Мастер диаграммперевірте правильність посилань на клітки базової лінії. Клацніть Ряд і через функцію Добавитьвведіть ім'я і значення лінії тренда. Для побудови лінії тренда на графіку тимчасового ряду виділіть в стовпці Е клітки з Е4 до Е17. Не дивлячись на відсутність даних в клітках Е4 і Е5, ми повинні їх також виділити, щоб тренд був правильно розміщений на графіку. Клацніть на кнопці Далее.
3.5. На третьому кроці виберіть параметри графіка, що включає як лінії, так і маркери. Клацніть на кнопці Далее.
3.6. На четвертому, кроці роботи майстра необхідно визначити місцеположення діаграми: на окремому або тому ж листі. Клацніть на кнопці Готово.
3.7. На графіку, навівши курсор на побудовану лінію тренда, натискаємо праву кнопку миші, вибираємо «Добавить линию тренда». У вікні «Тип» вибираємо найбільш коректну для задачі функцію, орієнтуючись на величину коефіцієнта детермінації R, ближчу до 1. Для цього у вікні «Параметри» виділяємо «поместить на диаграмме R».
Побудувавши трендову криву, переносимо відомі прогнози тренда на потрібний рік. Далі, використовуючи вищезазначені сезонні чинники, визначаємо скоректований прогноз на наступний рік.
Завдання
Використовуючи описану вище методику прогнозування, за даними таблиці 1.4 і таблиці 1.5 розрахуйте індекси сезонності, побудуйте сезонну хвилю та зробіть прогноз обсягу реалізації продукції відповідно на 6 місяців (для табл.1.4) і на 4 квартали (для табл.1.5) наступного року.
Таблиця 1.4
Обсяг реалізації хлібобулочних виробів, тис. т
| Місяць | Рік | |||
| 5,3+к | 5,7+к | 5,9+к | 6,4+к | |
| 6,4+к | 6,5+к | 6,7+к | 6,8+к | |
| 7,2+к | 6,9+к | 6,9+к | 7,1+к | |
| 7,6+к | 7,8+к | 7,9+к | 7,9+к | |
| 8+к | 8,2+к | 8,5+к | 8,7+к | |
| 7,5+к | 7,7+к | 8+к | 8,2+к | |
| 7+к | 8,0+к | 8,3+к | 8,4+к | |
| 7,5+к | 8,2+к | 8,5+к | 8,9+к | |
| 8,6+к | 9+к | 9,2+к | 9,5+к | |
| 9,1+к | 9,5+к | 9,7+к | 9,9+к | |
| 9,7+к | 9,9+к | 10,1+к | 10,4+к | |
| 10+к | 10,4+к | 10,6+к | 10,8+к |
К- номер непарного варіанта (1; 3; 5; і т.д.)
Таблиця 1.5
Обсяги споживання соку однією сім`єю (в середньому за вибіркою), л
| Рік | Квартал 1 | Квартал 2 | Квартал 3 | Квартал 4 |
| 30+0,7*к | 33+0,7*к | 48+0,7*к | 40+0,7*к | |
| 28+0,7*к | 35+0,7*к | 50+0,7*к | 44+0,7*к | |
| 33+0,7*к | 38+0,7*к | 55+0,7*к | 42+0,7*к | |
| 34+0,7*к | 40+0,7*к | 56+0,7*к | 43+0,7*к |
К- номер парного варіанта (2; 4; 6; і т.д.)
ЛАБОРАТОРНА РОБОТА № 2
РОЗРАХУНОК ПРОГНОЗІВ ІЗ ЗАСТОСУВАННЯМ МЕТОДУ КОВЗНОЇ СЕРЕДНЬОЇ, ЕКСПОНЕНЦІЙНО ЗВАЖЕНОЇ СЕРЕДНЬОЇ ТА ЗА ДОПОМОГОЮ ФУНКЦІЙ РЕГРЕСІЇ EXCEL
Мета роботи: Отримати відомості і навички роботи з основними елементами надбудови Пакет анализа (Скользящее среднее, Экспоненциальное сглаживание), а також навчитися основним прийомам прогнозування за допомогою функцій ТЕНДЕНЦИЯ і РОСТ.
План
1. Складання прогнозів за допомогою надбудов ковзної середньої.
2. Складання прогнозів за допомогою надбудов експоненційно зваженої середньої.
3. Складання лінійних прогнозів: функція ТЕНДЕНЦИЯ.
4. Складання нелінійного прогнозу: функція РОСТ.
Теоретичні відомості
1. При використанні методу ковзного середнього прогноз будь-якого періоду є не що інше, як отримання середнього показника декількох результатів наглядів тимчасового ряду. Наприклад, якщо ви вибрали ковзне середнє за три місяці, прогнозом на травень буде середнє значення показників за лютий, березень і квітень. Якщо ви вибрали метод прогнозування ковзного середнього за чотири місяці, ви зможете оцінити травневий показник як середнє значення показників за січень, лютий, березень і квітень.
Обчислення за допомогою цього методу достатньо точно відбивають зміни основних показників попереднього періоду. Іноді при складанні прогнозу ці методи більш ефективні, ніж методи, засновані на довготривалих наглядах. При використанні ковзного середнього за два останні місяці кожний з показників (за цей часовий період) відповідає за половину значення прогнозу. При 4-місячному ковзковому середньому показники цих же останніх місяців відповідають тільки за четверту частину значення прогнозу.
Таким чином, чим менше число результатів наглядів, на підставі яких обчислене ковзне середнє, тим точніше воно відбиває зміни в рівні базової лінії.
Але, якщо базою для прогнозованого ковзного середнього є всього лише одне або два нагляди, то такий прогноз може стати дуже спрощеним. Зокрема, він відображатиме тенденції в даних, на яких він будується, нітрохи не краще, ніж сама базова лінія.
Щоб визначити, скільки спостережень бажано включити в ковзне середнє, потрібно виходити з попереднього досвіду і наявної інформації про набір даних. Одне відхилення в наборі даних для трьохкомпонентного середнього може змінити весь прогноз. А чим менше компонентів, тим менше ковзне середнє відгукується на зміну ситуації. Немає загального правила, яким слід керуватися в подібному випадку: використовуйте власну думку, засновану на знаннях того набору даних, з яким ви працюєте.
Нижче представлений алгоритм складання прогнозів за допомогою надбудови ковзного середнього.
1. Алгоритм складання прогнозів за допомогою надбудов ковзної середньої
Цей спосіб вживання ковзного середнього використовує надбудову Пакет анализа.
Встановити цю надбудову можна таким чином.
1.1. Виберіть команду Сервис - Надстройка.
1.2. З'явиться діалогове вікно Надстройка. Встановіть прапорець Пакет анализа і клацніть на кнопці ОК.
1.3. При необхідності активізуйте робочий лист, що містить дані про вашу базову лінію.
1.4. В меню Сервис ви знайдете нову команду Анализ данных. Виберіть команду Сервис - Анализ данных.
1.5. З'явиться діалогове вікно Анализ данных, в якому містяться всі доступні функції аналізу даних. Із списку виберіть інструмент аналізу Скользящее среднее і клацніть на кнопці ОК.
1.6. З'явиться діалогове вікно Скользящее среднее.
1.7. В полі Входной интервал введіть дані про вашу базову лінію або вкажіть діапазон в робочому листі, посилання на нього з'явиться в цьому полі.
1.8. В полі Интервал введіть кількість місяців, днів які хочете включити в підрахунок ковзного середнього.
1.9. В полі введення Выходной интервал введіть адресу клітки, у яку поміщають прогнозні дані.
1.10. Клацніть на кнопці ОК.
Excel виконує замість вас роботу по внесенню значень у формулу для обчислення ковзного середнього. Значення ковзного середнього починається із значень #Н/Д, які дорівнюють значенню вказаного вами інтервалу мінус один. Це робиться через недостатню кількість даних для обчислення середнього значення декількох перших результатів наглядів, з інтервалом у 3 періоди.
2.Тип і глибину прогнозування визначає характер бізнесу. Якщо у вас дешевий або швидкопсувний продукт, необхідний швидкий і простий метод прогнозування, за допомогою якого можна регулярно складати прогноз на один звітний період вперед.
Методика, що використовується для подолання проблем, пов'язаних з короткостроковим прогнозуванням, носить назву ЕКСПОНЕНЦІЙНЕ ЗГЛАДЖУВАННЯ» .Більшпізнім даним додається більша вага, ніж більш раннім даним. Цей метод забезпечує швидке отримання прогнозу на один період вперед і автоматично коректує будь-який прогноз в світлі відмінностей між фактичним і спрогнозованим результатами. Цей метод частіше за все застосовується для прогнозування попиту.
Проста модель експоненціального згладжування представлена наступним рівнянням:
Попит на наступний період = Константа згладжування х Фактичний попит в поточному періоді + (1 — Константа згладжування) х Прогноз на поточний період
Цю модель можна представити у вигляді символів:
Ft+1=Dt+(1-)Ft,
де -константа згладжування;
Ft-прогноз на поточний період (на періодt);
Ft+1- прогноз на наступний період (на періодt+1);
Dt— фактичний попит на періодt.
Прогноз на поточний період залежить в деякій мірі від даних минулих періодів і пізніше ми побачимо на конкретному прикладі, як можна визначити його значення.
Константа згладжування — це величина між 0 і 1,яку вибирає укладач прогнозу залежно від специфіки конкретного вживання. Якщо величина константи вибирається рівною нулю, то прогноз на наступний період буде рівний прогнозу на поточний період, тобто прогноз повністю заснований на даних минулого періоду і не враховує найпізніші із наявних фактичних даних.
З іншого боку, якщо константа приймається рівною 1, то даним минулих періодів не приділяється ніякого значення, і прогноз повністю залежить від фактичного попиту на поточний період. Такий підхід приймається, якщо йдеться про відкриття нового супермаркету, - зрозуміло, що в подібному випадку дані минулих періодів для складання прогнозу відсутні.
В цілому в умовах стабільності найбільш часто застосовуються значення константи згладжування від 0,2 до 0,4, проте в деякі періоди року, особливо для періоду передріздвяної торгівлі в супермаркетах, для прогнозування використовуються більш високі значення : від 0,7 до 0,9. Очевидно, що необхідно мати достатній запас для задоволення поточного попиту.
Метод експоненціального згладжування використовується для короткострокового прогнозування шляхом розрахунку зваженої середньої поточних даних і даних минулих періодів. Для кращого віддзеркалення особливостей динаміки даних за минулі періоди вибирається відповідне значення константи згладжування . Мале значення прийнятне для відносно стабільних рядів, а високе значення більш переважне для рядів з великими змінами.
Після встановлення системи прогнозування необхідно здійснювати моніторинг її точності шляхом розрахунку помилки прогнозу і згладжених середніх абсолютних значень відхилення.
Як відомо, згладжування — це спосіб, що забезпечує швидке реагування прогнозу на всі події, що відбуваються протягом певного періоду. Методи, засновані на регресії, такі як функції ТЕНДЕНЦИЯіРОСГзастосовують до всіх точок прогнозу одну і ту жформулу. З цієї причини досягнення швидкої реакції на зсуви в рівні базової лінії значно утрудняє дії. Згладжування є простим способом обійти дану проблему.
Основна ідея вживання методу згладжування полягає в тому, що кожний новий прогноз виходить за допомогою переміщення попереднього прогнозу в напрямі, який дав би кращі результати в порівнянні із старим прогнозом. Константа згладжування є величиною, що самокоректується. Іншими словами, кожний новий прогноз є сумою попереднього прогнозу і поправочного коефіцієнту, який і пересуває новий прогноз в такому напрямі, що робить попередній результат більш точним.
Згладжування є дуже корисним в тих випадках, коли в тимчасовому ряду спостерігаються істотні відмінності в рівнях даних. Методи прогнозування під назвою „згладжування" враховують ефекти стрибка функції набагато краще, ніж способи, що використовують регресивний аналіз. Excelбезпосередньо підтримує один з таких методів за допомогою засобу«Экспоненциальное сглаживание»в надбудові«Пакет анализа».
2. Алгоритм обчислення зваженої ковзної середньої, використовуючи інструмент Экспоненциальное сглаживание
1. Обчислення«Экспоненциальное сглаживание»починається з вибору команди«Сервис - Анализ данных».
2. В діалоговому вікні, що відкрилося,«Анализ данных»із списку Інструменти аналізу виберіть пункт«Экспоненциальное сглаживание»і клацніть на кнопці ОК.
Excelвідобразить на екрані діалогове вікно «Экспоненциальное сглаживание».
3. Вкажіть діапазон кліток, в якому містяться початкові дані. Використовуйте для цього текстове поле, позначене написом «Входной інтервал».
Виділіть діапазон з даними. Щоб повідомити, що в першому рядку списку даних містяться назви полів, встановіть прапорець «Метка».
4. Визначте«Сглаживающую константу». Вкажіть значення згладжуючої константи в текстовому полі.
Фактор затухания.Довідкова система Excelпропонує вам вказати значення згладжуючої константи в межах від 0,2 до 0,3. Чинник загасання в діалоговому вікні«Экспоненциальное сглаживание»і константа згладжування, про яку вже згадувалося в попередньому абзаці, зв'язані між собою так:
1 -константа згладжування = чинник загасання
Таким чином, якщо вам відомий чинник загасання, це означає, що можна обчислити константу згладжування, і навпаки. Excelпроводить обчислення за допомогою параметраФактор затухания. Для даної роботи константу згладжування слід прийняти рівною 0,3.
Слід уникати використовування параметраФактор затухания,який менше значення 0,7. В цьому випадку, необхідно скористатися іншими способами прогнозування, а не простим згладжуванням.
5. Повідомте Excel, куди повинні бути поміщені обчислені значення.
Використовуйте текстове поле«Выходной интервал»,щоб вказати діапазон чарунок, в які повинні бути поміщені обчислені значення.
6. Якщо ви хочете побачити графік експоненціально згладженого середнього, вкажіть це за допомогою установки прапорця «Вывод графика».
7. Якщо вам потрібна інформація про значення стандартних погрішностей, дайте вказівку Excelобчислювати ці значення (за потребою).
Обчислення стандартних погрішностей відбувається при активізації опції«Стандартные погрешности».Excelрозмістить значення стандартних погрішностей поряд із значеннями експоненціально згладженого середнього.
8. Після того, як ви визначили, які значення повинні бути обчислені і куди вони повинні бути поміщені, клацніть на кнопці ОК.
3. Просте ковзне середнє є швидким, але досить неточним способом виявлення загальних тенденцій тимчасового ряду. Вони не дають прогнозу, що виходить за межі, в яких дані вже відомі. Пересунути межу оцінки майбутнього по тимчасовій осі можна за допомогою однієї з функцій регресії Excel.
Кожний з методів регресії оцінює взаємозв'язок фактичних даних наглядів і інших параметрів, які часто є показниками того, коли були зроблені ці нагляди. Це можуть бути як числові значення кожного результату нагляду в тимчасовому ряду, так і дата нагляду.
Функція «ТЕНДЕНЦИЯ» обчислює прогнози, засновані на лінійному зв'язку між результатом нагляду і часом, коли цей нагляд був зафіксований. Припустимо, що ви складаєте лінійний графік даних, на вертикальній осі якого відмічаєте результати наглядів, а на горизонтальній фіксуєте тимчасові моменти їх отримання. Якщо цей взаємозв'язок носить лінійний характер, то лінія на графіку буде або прямою, або злегка нахиленою в одну або іншу сторону, або горизонтальною. Це і буде кращою підказкою про те, що взаємозв'язок є лінійним, і тому в даному випадку функція «ТЕНДЕНЦИЯ»-найзручніший спосіб регресивного аналізу.
Проте, якщо лінія різко згинається в одному з напрямів, то це означає, що взаємозв'язок показників носить нелінійний характер. Існує велика кількість типів даних, які змінюються в часі нелінійним способом. Деякими прикладами таких даних є обсяг продажів нової продукції, приріст населення, виплати по основному кредиту і коефіцієнт питомого прибутку. У разі нелінійного взаємозв'язку функція Excel «РОСТ» допоможе вам одержати більш точну картину напряму розвитку вашого бізнесу, ніж функція «ТЕНДЕНЦИЯ».
Рекомендується мати на увазі наступне.
• Якщо дані, що використовуються при створенні графіка змінної, розташовуються поблизу прямої лінії, то для створення прогнозу на майбутнє краще всього скористатися функцією «ТЕНДЕНЦИЯ», без жодних надмірностей.
• Якщо аналізовані дані розташовані уздовж кривої, то, можливо, якнайкращий прогноз дасть функція «РОСТ». Порівняйте результати, одержані за допомогою функції «РОСТ» на даній базовій лінії, з самою базовою лінією. Якщо вони близькі, то використовуйте функцію «РОСТ» для прогнозу на підставі базової лінії.
Регресійний аналіз за допомогою діаграм
У багатьох випадках діаграми Excel дуже корисні при створенні прогнозів. Вони допомагають візуально представити дані. Більш того, деякі методи статистики, що використовуються в прогнозуванні, використовують відхилення, тобто значення, які незвичайно далеко відстоять від середнього значення. Якщо представити дані у вигляді діаграми, то набагато легше визначити, чи впливають відхилення на прогноз.
Іноді виникає необхідність провести регресивний аналіз безпосередньо на графіку, без введення в робочий лист значень для прогнозу. Це можна зробити за допомогою графічної ліній тренда. Цей метод багато в чому схожий з методом отримання прогнозу із застосуванням ковзного середнього на основі графіка, клацнувши мишею на діаграмі, ви дістанете можливість її редагувати.
3. Алгоритм складання лінійних прогнозів: функція «ТЕНДЕНЦИЯ»
1.1.Результати ваших наглядів внесені, наприклад в клітинки А2:А11, а дні місяця розташовані в клітках В2:В11.
1.2.Виділяємо клітки С2:С11 і вводимо наступну формулу, використовуючи формулу масиву: =ТЕНДЕНЦИЯ (А2:А11;В2:В11).
Для введення формули масиву необхідно натискати комбінацію клавіш «Сtrl+Shift» (рис.2.1).
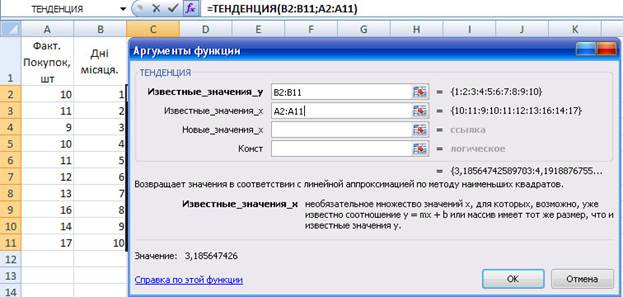
Рис.2.1 Розрахунок лінійних прогнозів за відомими значеннями
Функція «ТЕНДЕНЦИЯ» обчислює прогноз, заснований на зв'язку між фактичними результатами наглядів і числами 1-10, які можуть відображати або перші десять днів місяця, або перші десять місяців року. Excel виражає перший аргумент як аргумент відомі значення-у функції «ТЕНДЕНЦИЯ», а другий — як аргумент функції відомі значення-х.
Якщо ви пропонуєте функції «ТЕНДЕНЦИЯ» тільки перший аргумент— відомі-значення-у, то Excel вважає, що другий аргумент відомі-значення-х - є рядом, що починається з 1 і що закінчується числовим значенням відомі-значення-у, вказаним вами. Якщо прийняти, що числа від 1 до 20 розташовані в клітках В2: В20, то дві нижче наведені формули будуть еквівалентні:
=ТЕНДЕНЦИЯ(А2:А20)=ТЕНДЕНЦИЯ(А2:А20;В2:В20)
Оскільки регресійний аналіз дозволяє проводити перспективну оцінку більш віддаленого майбутнього, а на практиці бажано скласти прогноз хоча б на перший, тому беремо до уваги наступний за цим період тимчасового ряду (тобто той, для якого ще немає результатів спостереження). Розглянемо, як це можна зробити за допомогою функції «ТЕНДЕНЦИЯ».
Застосовуючи дані робочого листа, введіть в клітку В12 число 11, а в клітку ВІЗ — наступне, тоді формула буде:
=ТЕНДЕНЦИЯ(А2:А11;В2:В11;В12). '
Формула фактично відображає наступне: "якщо відомо, яким чином у-значення в діапазоні А2:А11 співвідносяться зі х-значеннями в діапазоні В2:В11, то який результат у-значення ми одержимо, знаючи нове х-значення тимчасового моменту, рівне 11?" Набуте значення є прогнозом на основі фактичних даних на одинадцятий часовий відлік, що поки- що не наступив.
Крім того, існує можливість одночасного прогнозування даних для декількох нових тимчасових моментів. Наприклад, введіть числа від 11 до 19 в чарунки В12:В20, а потім виділіть дані в стовпчику С12:С20 і введіть за допомогою формули масиву наступне (рис.2):
=ТЕНДЕНЦИЯ(А2:А11;В2:В11;В12:В20)
Excel поверне в клітки С12:С20 прогноз на тимчасові моменти з 11 по 19 день. Даний прогноз базуватиметься на зв'язку між даними наглядів базової лінії діапазону А2:А11 і тимчасовими моментами базової лінії з 1 по 10, вказаними в клітках В2:В11 (рис.2.2).
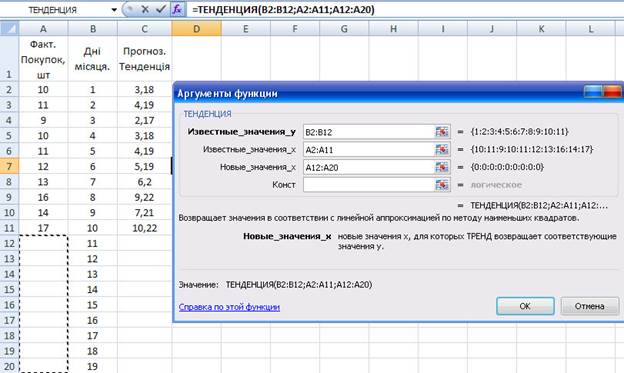
Рис.2.2.Розрахунок перспективного лінійного прогнозy
4. Алгоритм складання нелінійного прогнозу: функція «РОСТ»
4.1. Припустимо, що результати ваших наглядів внесені в клітки А4:А13, а дні місяця розташовані в клітках В4:В13.
4.2. Виділяємо клітки С4:С13 і вводимо наступну формулу, використовуючи формулу масиву: =РОСТ(А4:А13;В4:В13).
Для введення формули масиву необхідно натискати комбінацію клавіш «Ctrl+Shift».
4.3. Будуємо діаграму, і спостерігаємо, яким чином фактичні і прогнозовані дані фіксуються в стандартному лінійному графіку. Оскільки лінія зміни наявних на фірмі товарів різко згинається вгору, менеджер ухвалює рішення скласти прогноз з використанням функції «РОСТ».
4.4. Щоб прогнозувати результати на 11 або 13 день, слід ввести ці числа в клітки В14:В17, а потім за допомогою формули масиву в діапазон клітинок С14:С17 ввести наступне:
=РОСТ(А4:А13;В4:В13;В4:В17).
В клітках С14:С17 будуть приведені значення попередньої оцінки кількості замовлень, яку можна чекати в подальші дні місяця за умови, що поточна тенденція зростання залишиться незмінною. Проте слід враховувати, що такий оптимістичний прогноз на практиці, ймовірно, зазнає певні зміни. Якщо при обчисленні прогнозу кількість планованих замовлень перевищить кількість клієнтів, від нього, швидше за все, слід просто відмовитися.
Завдання
Використовуючи описані вище методики прогнозування, за даними таблиці 2.1 складіть прогнози на наступні періоди, розрахуйте стандартні відхилення показників. Порівняйте результати прогнозування та зробіть оцінку якості прогнозу.
Таблиця 2.1
Обсяг продажу у магазині «Мрія» у 2011 році
| Місяць | Обсяг продажу | Місяць | Обсяг продажу |
| Січень | 56+11к | Липень | 40+10к |
| Лютий | 30+10,5к | Серпень | 27+9к |
| Березень | 47+8,7к | Вересень | 24+10к |
| Квітень | 34+11к | Жовтень | 24+10,6к |
| Травень | 30+12к | Листопад | 29+11к |
| Червень | 45+11,5к | Грудень | 34+12,5к |
К-номер варіанту
ЛАБОРАТОРНА РОБОТА № 3
ПРОГНОЗУВАННЯ НА ОСНОВІ ЗАЛЕЖНОСТІ
МІЖ ДВОМА ЗМІННИМИ
Мета роботи: Одержати навики роботи з інструментами аналізу «РЕГРЕССИЯ» і «КОРРЕЛЯЦИЯ»; визначити незалежну змінну і залежну змінну; зрозуміти відмінність між позитивною і негативною кореляцією; оцінити тісноту лінійної залежності, використовуючи коефіцієнт кореляції, побудувати моделі множинної регресії та провести прогнозування.
План
1.Побудова моделі лінійної регресії.
2.Використання інструменту «КОРРЕЛЯЦИЯ».
3.Побудова моделі множинної регресії.
4.Складання прогнозу
Теоретичні відомості
Для нового підприємства або нового продукту даних минулих періодів просто не існує, значить для прогнозування обсягу продажу необхідні інші підходи. Для будь-якого нового підприємства або нового продукту життєво важливо мати хоча б приблизне уявлення про можливий майбутній обсяг продажу. Тоді ми зможемо хоча б скласти кошторис на основі очікуваних доходів і витрат.
З цією метою використовується підхід, в основі якого лежить спроба встановити, чи існує за аналогічних умов взаємозв'язок між обсягом продаж і значенням інших змінних. Наприклад:
·обсяг продаж продукту може бути пов'язаним з витратами на рекламу цього продукту;
·обсяг продаж крупного супермаркету може бути пов'язаний з чисельністю населенню, що проживає в межах 30-хвилинної їзди від супермаркету.
Такі змінні, як витрати на рекламу, чисельність населення, що проживає на відстані 30-хвилинної їзди, є незалежними змінними, пояснюючими змінними, а ті змінні, які ми намагаємося оцінити, в даному випадку - обсяг продаж - є залежними змінними.
Схема складання прогнозу полягає в зборі даних про значення залежних і незалежних змінних, їх аналізі на предмет наявності зв'язку і, якщо такий зв'язок існує, необхідно оцінити тісноту цього зв'язку - це і є «КОРРЕЛЯЦИЯ». Якщо ми встановимо наявність сильного зв'язку між двома змінними, тоді повинні вивести математичне рівняння, що описує цей зв'язок. Це відповідає поняттю «РЕГРЕССИЯ». Для складання прогнозу поведінки даної змінної в новій ситуації ми повинні знати відповідні цій ситуації значення незалежної змінної, тоді ми зможемо розрахувати значення залежної змінної.
Методики розрахунку кореляції і регресії широко застосовуються на практиці і підходять для дослідження можливого взаємозв'язку між двома змінними в багатьох різних ситуаціях.
Перша стадія кореляційного аналізу - збір даних про значення змінних, які, по нашому припущенню, можуть мати взаємозв'язок. Для отримання більш чіткого уявлення про можливий зв'язок між ними, слід побудувати точкову діаграму.
Коефіцієнт кореляції
Якщо точки на точковій діаграмі показують абсолютну корреляцію, то через них можна провести пряму і вивести рівняння цієї прямої, що допоможе скласти прогноз продажів. Проте в бізнесі рідко можна побачити приклад абсолютного лінійного зв'язку. Якщо точки а діаграмі демонструють сильну кореляцію, можна також спробувати провести пряму, яка в найбільшій мірі відповідає їм, і використовувати її для складання прогнозу, який в середньому дасть достатньо надійні результати. Крім того, нам необхідно переконатися, чи достатньо сильний кореляційний зв'язок, щоб припустити наявність лінійної залежності між двома даними змінними. Наше рішення базується на значенні коефіцієнта кореляції. Це показник розраховується на основі наявних пар значень двох змінних і його значення коливається від (– 1) - у разі абсолютної негативної кореляції - до (+1) - у випадку абсолютної негативної кореляції. У всіх інших випадках коефіцієнт кореляції знаходитиметься в межах від -1 до +1.Чим ближче його значення до +1 або -1, тим більше тісний кореляційний зв'язок. Якщо обчислений нами коефіцієнт кореляції по значенню близький до +1 або -1, то це означає, що між двома змінними існує сильна лінійна залежність.
Отже, для визначення взаємозв’язку між двома змінними використовуємо точкові діаграми, а для оцінки тісноти зв’язку використовується коефіцієнт кореляції. Якщо існує сильна кореляція, то зміна однієї змінної, а саме – незалежної ,може бути використана для прогнозування іншої залежної змінної. Це метод особливо корисний, коли необхідно скласти прогноз продажів для нового підприємства або нового продукту в умовах відсутності даних минулих періодів.
Множинна регресія
Хоча лінійна регресія і дозволяє складати прогнози регресії, в деяких ситуаціях вона не є прийнятною в силу високої динаміки факторів, які визначають причинно-наслідкові зв’язки . В реальності у нас немає підстав вважати, що, наприклад, всі зміни обсяґу продажів пояснюються тільки однією причиною (змінною). Більш вірогідно, що на обсяг продажу впливають безліч різних чинників, таких як розмір торговельної площі, число працівників, число контрольно-касових апаратів, кількість конкуруючих магазинів в даному регіоні, рівень цін, відомість бренду, асортимент товарів та їх модельний ряд і т.д.
Модель лінійної регресії, яку ми використовували, може бути поширена і на ці ситуації, при яких обсяг продажів, як ми вважаємо, залежить від цілого ряду змінних, і це буде множинна регресія.
Варто зазначити, що не завжди моделям множинної регресії віддаватиметься перевага в порівнянні з моделями лінійної регресії. Аналіз множинної регресії зв’язаний з великими витратами часу і засобів для збору початкових даних, а це може створити необґрунтовані затримки часу або неприйнятні додаткові витрати (фінансові, трудові тощо).
Процес аналізу множинної регресії може бути поширений на велику кількість змінних Х. Для виконання подібного аналізу в електронних таблицях ми повинні ввести всі значення змінних Х в рамках аналізу регресії. На практиці часто виявляється, що найкращий шлях – використовувати мінімальне число змінних, необхідних для отримання прийнятого результату. Ви завжди повинні мати логічне обгрунтування для дослідження взаємозв’язків між вибраними чинниками. Спочатку у вас повинні бути конкретні міркування про взаємозв’язок двох чинників, а потім вже, використовуючи регресійний аналіз, ви підтверджуєте або спростовуєте свою первинну гіпотезу.
Хід роботи:
1. Алгоритм використання інструменту «РЕГРЕССИЯ»
Для проведення прогнозу скористаємося інструментом «РЕГРЕССИЯ», який встановлюється разом з надбудовою «ПАКЕТ АНАЛИЗА». Припустимо, наприклад, що ви вже побудували для свого набору даних точкову діаграму і додали до неї лінію тренда, що дозволило вам поверхнево оцінити наявні дані. Тепер треба провести детальне дослідження і одержати більш повну і точну інформацію. Щоб провести регресійний аналіз з використанням можливостей надбудови «ПАКЕТ АНАЛИЗА, виконайте ряд дій:
1.Вибираємо команду «СЕРВИС – АНАЛИЗ ДАННЫХ».
2.В діалоговому вікні, що відкрилося, «АНАЛИЗ ДАННЫХ» в списку «ИНСТРУМЕНТЫ АНАЛИЗА» вибираємо пункт «РЕГРЕССИЯ» і натискаємо на кнопку ОК. На екрані відображаємо діалогове вікно «РЕГРЕССИЯ».
3.Визначте значення Х і У.
В полі «ВХОДНОЙ ИНТЕРВАЛ У» вкажіть посилання на діапазон кліток, в яких міститься набір залежних значень. Потім перейдіть до поля «ВХОДНОЙ ИНТЕРВАЛ Х» і вкажіть посилання на діапазон кліток, в яких міститься набір залежних значень.
Кожний з цих діапазонів повинен бути одиничним стовпцем із значеннями. Наприклад, якщо ви хочете використовувати інструмент «РЕГРЕССИЯ» для вивчення дії реклами на обсяг продаж, введіть в полі «ВХОДНОЙ ИНТЕРВАЛ Х» кількість виходів реклами, а в полі « ВХОДНОЙ ИНТЕРВАЛ У» - обсяг продаж. Якщо вказані клітки містять підписи даних, встановіть прапорець «МЕТКИ».
4.Встановіть прапорець «КОНСТАНТА – НОЛЬ» (за потреби).
Встановіть цей прапорець, якщо лінія регресії повинна перетинати вісь значень в нульовій точці. Іншими словами, якщо необхідно, щоб нульовому значенню незалежної величини відповідало нульове значення залежної змінної величини.
5.Вкажіть, чи потрібно при проведенні регресійного аналізу враховувати рівень надійності.
Для цього встановіть прапорець «УРОВЕНЬ НАДЕЖНОСТИ» і в розташованому справа текстовому полі задайте значення цього рівня.
6. Вкажіть місце, куди повинні бути роміщені результати проведеного регресійного аналізу.
Використовуйте перемикачі «ПАРАМЕТРЫ ВЫВОДОВ», щоб вказати EXCEL, де повинен бути розміщений звіт про одержані результати. Наприклад, щоб помістити цей звіт на тому ж листі, де розташовані початкові дані, виберіть перемикач «ВЫХОДНОЙ ИНТЕРВАЛ» і в полі, праворуч від нього, вкажіть адресу кліток, які повинні містити результати проведеного дослідження. Щоб помістити звіт в іншому місці, виберіть один з двох інших перемикачів.
7. Визначте, які саме значення повинні бути обчислені. Використовуйте прапорці групи «ОСТАТКИ», щоб визначити, інформація якого роду про залишки повинна бути включена у звіт про проведений регресійний аналіз.
Також встановіть прапорець «ГРАФИК НОРМАЛЬНОЙ ВЕРОЯТНОСТИ», щоб додати в звіт інформацію про залишки, які відповідають нормальній вірогідності, і відобразити графік нормальної вірогідності.
8.Клацніть на кнопку ОК. Excel виконає всі необхідні обчислення і відобразить звіт.
Цей звіт містить значення деяких ключових статистичних регресійних показників, включаючи значення R-квадрат, значення стандартної помилки і кількість наглядів. Далі йдуть дані дисперсійного аналізу, включаючи інформацію про кількість спостережень. Далі слідують дані дисперсійного аналізу, включаючи інформацію про кількість ступенів свободи, суми квадратів. Нижче розміщені дані про побудовану лінію регресії, включаючи показники коефіцієнтів- стандартної помилки, t-статистики, показники вірогідності, а також деякі дані про незалежну змінну, яка в даному прикладі є кількістю виходів рекламних роликів.
2. Алгоритм використання інструменту «КОРРЕЛЯЦИЯ»
Інструмент аналізу «КОРРЕЛЯЦИЯ» (який також встановлюється разом з надбудовою «ПАКЕТ АНАЛИЗА») використовується для оцінки ступеня залежності між двома наборами даних. Наприклад, ви можете також використовувати цей інструмент для оцінки впливу розміру коштів, витрачених на рекламу, на обсяг продажів рекламного продукту. Щоб застосувати інструмент «КОРРЕЛЯЦИЯ», виконайте ряд дій.
1.Виберіть команду «СЕРВИС-АНАЛИЗ ДАННЫХ»
2.В діалоговому вікні, що відкрилося, «АНАЛИЗ ДАННЫХ» в списку «ИНСТРУМЕНТЫ АНАЛИЗА» виберіть пункт «КОРРЕЛЯЦИЯ» і клацніть на кнопку ОК.
Excel відобразить на екрані діалогове вікно «КОРРЕЛЯЦИЯ».
3.Визначте значення Х і У, яку повинні бути проаналізовані. Наприклад, якщо ви хочете взнати, як кількість виходів рекламних роликів впливає на обсяги продаж рекламованого товару, в полі «ВХОДНОЙ ИНТЕРВАЛ» вкажіть посилання на клітки. Якщо цей діапазон містить підписи даних, встановіть прапорець «МЕТКИ» в першому рядку. Перевірте, чи правильно вибраний перемикач «ГРУППИРОВАНИЕ», що визначає спосіб організації даних у виділеному діапазоні кліток.
4.Вкажіть місце, куди повинні бути поміщені результати обчислення.
Використовуйте перемикачі групи «ПАРАМЕТРЫ ВЫВОДОВ», щоб вказати EXCEL, де повинен бути розміщений звіт про одержані результати. Наприклад, щоб помістити цей звіт на тому ж листі, де розташовані початкові дані, виберіть перемикач «ВЫХОДНОЙ ИНТЕРВАЛ» і в полі, праворуч від нього, вкажіть адресу кліток, які повинні містити обчислені значення. Щоб помістити звіт в іншому місці, виберіть один з двох інших перемикачів.
5.Клацніть на кнопку ОК. Excel обчислить коефіцієнт кореляції для вказаних вами даних і помістить його в задане місце.
3. Побудова моделі множинної регресії
1.Вибираємо команду «СЕРВИС - АНАЛИЗ ДАННЫХ - ИНСТРУМЕНТЫ АНАЛИЗА – РЕГРЕССИЯ».
2.Визначте значення Х і У. В полі «ВХОДНОЙ ИНТЕРВАЛ У» вкажіть посилання на діапазон осередків, в яких міститься набір залежних значень (обсяг продаж). Потім перейдіть до поля «ВХОДНОЙ ИНТЕРВАЛ Х». Переконайтеся, наприклад, що дані про розміри торговельної площі і чисельність персоналу розташовуються в сусідніх колонках. Помітьте блок, що складається з цих обох колонок, як значення Х. В цьому і полягає єдина відмінність введення даних для лінійного і множинного регресійного аналізу. Потім аналіз проводиться аналогічно попередньому, але коли з’являються його результати, ми бачимо два коефіцієнти при Х.
В результаті застосування інструменту «РЕГРЕССИЯ» отримуємо таблиці з результатами розрахунків.
В таблиці Регресійна статистика виводяться такі результати розрахунків:
Ø багатофакторний коефіцієнт кореляції R;
Ø коефіцієнт детермінації R-квадрат  ;
;
Ø нормований R-квадрат  , який розраховується за формулою
, який розраховується за формулою
 ,
,
де  - кількість параметрів;
- кількість параметрів;
Ø стандартна похибка, тобто виправлене середнє квадратичне відхилення залишків;
Ø спостереження, тобто кількість періодів спостережень.
В таблицях Дисперсійного аналізу показуються наступні результати.
Перша таблиця:
Ø в першій колонці df означає ступені свободи для суми квадратів відхилень, відповідно для
· регресійної df=m-1;
· залишкової df=n-m;
· загальної df=n-1;
Ø в другій колонці SS означає суму квадратів відхилень, відповідно
· регресійну  ;
;
· залишкову  ;
;
· загальну  ;
;
Ø в третій колонці MS означає відповідні суми квадратів відхилень з врахуванням числа ступенів свободи MS=SS/df, тобто в цій колонці наводяться значення виправлених дисперсій;
Ø в четвертій колонці наведено значення F-критерію Фішера з 95% рівнем довіри;
Ø в п`ятій колонці наведена «значущість F», яка показує, що якщо наведений показник менше 0,05, то побудована регресійна модель відповідає дійсності.
Друга таблиця:
Ø в першій колонці Коефіцієнти наведено значення оцінок параметрів рівняння регресії (зверху-вниз)  ,
,  ,
,  ;
;
Ø в другій колонці Стандартна похибка середньоквадратичні відхилення параметрів моделі, тобто стандартні похибки параметрів;
Ø в тертій колонці t-статистика наводяться стандартизовані параметри рівняння регресії, які знаходяться шляхом ділення значень параметрів  з першої колонки на відповідні стандартні похибки з другої колонки;
з першої колонки на відповідні стандартні похибки з другої колонки;
Ø в червертій колонці Р-значення знаходяться значення функції, які показують, чи достовірні оцінки параметрів  ,
,  ,
,  . Якщо Р<0,05, то оцінки параметрів достовірні;
. Якщо Р<0,05, то оцінки параметрів достовірні;