Применение математической статистики в экономике
Содержание
Введение………………………………………………………3
1. Основные понятия математической статистики…………4
2. Применение математической статистики в экономике….9
3. Задачи математической статистики……………………...15
Заключение…………………………………………………..18
Список литературы………………………………………….19
Введение
Математическая статистика — наука о математических методах систематизации и использования статистических данных для научных и практических выводов. Во многом математическая статистика опирается на теорию вероятностей, позволяющую оценить надежность и точность выводов, которые делают на основании статистического материала (напр. оценить необходимый объем выборки для получения результатов требуемой точности при выборочном обследовании).
Зарождение статистики было связано с потребностями государственного управления и понималось как государствоведение. Одновременно развивались методы статистики и как разновидность счета нашли применение при организации и анализе результатов хозяйственного учета (подворные переписи, монастырские записи и т.п.), изучении населения, а также в сельском хозяйстве, медицине, биологии, социально-экономических исследованиях. Вместе с методами получили развитие отдельные разделы статистики, например вероятностных методов и актуарных вычислений.
В этой работе показано как по набору значений случайной величины в нескольких опытах можно сделать как можно более точный вывод о ее распределении. Примером такой серии экспериментов может служить социологический опрос набор экономических показателей или, наконец, последовательность гербов и решек при тысячекратном подбрасывании монеты.
Все вышеприведенные факторы обуславливают актуальность и значимость тематики работы на современном этапе направленной на глубокое и всестороннее изучение основных понятий математической статистики и ее основных задач.
В связи с этим целью данной работы является систематизация накопление и закрепление знаний о понятиях математической статистики.
Основные понятия математической статистики
Элементарным событием называется любой элемент пространства элементарных событий.
Пространством элементарных событий называется множество исходов некоторого эксперимента.
Событием называется любое подмножество пространства элементарных событий.
Генеральной совокупностью называется достаточно большое, быть может, бесконечное подмножество элементарных событий.
Случайной величиной называют функцию от элементарного события.
Экспериментом называется функция, принимающая значение на пространстве элементарных событий.
Статистическая моделью называется совокупность законов, которым подчиняется процедура эксперимента.
Случайной выборкой1 или просто выборкой1 объема n называется набор некоторого числа элементов генеральной совокупности, наблюденных при серии из n одинаковых экспериментов.
Статистикой называется любая измеримая функция от выборки.
Функцией правдоподобия называется плотность распределения выборки2, как n-мерной случайной величины.
к-й порядковой статистикой выборки х1,…,хn называется такая случайная величина х(k), что для каждого набора значений выборки х1,…,хn х(k) равна такому хi,для которого найдется ровно i-1 элементов выборки, которые меньше хi.
Если х1,…,хn – независимые, одинаково распределенные случайные величины, что распределение к-й порядковой статистики задается следующей формулой: 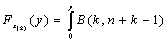 , где B(a,b) – плотность бета распределения.
, где B(a,b) – плотность бета распределения.
Вариационным рядом называется последовательность порядковых статистик x(1),…,x(n).
Выборочным квантилем порядка р называется значение х([np]+1).
Квантилью zp для с.в. х с функцией распределения F(x) называется любой корень уравнения F(zp)=p.
Эмпирическим распределением называется распределение, которое каждому элементу выборки1 х1,…,хn ставит в соответствие вероятность1/n.
Эмпирической функцией распределения называется функция Fn(x)=Á(-¥,x).
Математическое ожидание эмпирической функции распределения M(x) равно среднему арифметическому значений х1,…,хn.
Дисперсия эмпирической функции распределения 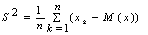 .
.
Выборочным моментом порядка k называется значение 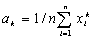 .
.
Теорема.Для эмпирического распределения Án(x) и распределения генеральной совокупности Á (x) при n®¥ 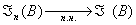 .
.
Условным законом распределения д.с.в. h при заданном значении д.с.в. x=хkназывается набор условных вероятностей 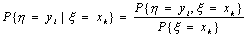 l=1,…,m.
l=1,…,m.
Условным математическим ожиданиемд.с.в.h при заданном значении д.с.в. x=хkназывается сумма 
 . Имеет место равенство M[M(x½h)] = Mh. М (Р (h = yl| x=xk)) = P(h = yl).
. Имеет место равенство M[M(x½h)] = Mh. М (Р (h = yl| x=xk)) = P(h = yl).
Достаточные статистики. Теорема Неймана-Фишера (критерий достаточности) СКТ 221.
Достаточной называется такая статистика t(x), что для случайной величины x с распределением p(x,q) условное распределение P(x | t(x) = t0) не зависит от параметра q (то есть через нее можно определить значение параметра q).
Теорема. Статистика t(x) с распределением p(x,q)=g(t(x);q)h(x) является достаточной.
Статистические оценки. Св-ва оценок: состоятельность, несмещенность, эффективность. Задача оптимального статистического оценивания СКТ 215.
Оценкой для независимой выборки (x1,…,xn) называют статистику  ,предназначенную для использования вместо параметра q, в качестве его приближения, однозначно определяемому исходным распределением F из семейства распределений Fq(x).
,предназначенную для использования вместо параметра q, в качестве его приближения, однозначно определяемому исходным распределением F из семейства распределений Fq(x).
Несмещенной называется такая оценка  , что ее мат. ожидание равно q.
, что ее мат. ожидание равно q.
Состоятельнойназывается последовательность оценок  , сходящаяся по вероятности к q.
, сходящаяся по вероятности к q.
Эффективной называется такая оценка что ее дисперсия минимальна среди последовательности оценок  .
.
Улучшение оценок с помощью достаточных статистик. Теорема Колмогорова Блекуэла Рао ВДВ СКТ 222.
Теорема Колмогорова Блекуэла Рао.Пусть t(х) - достаточная статистика семейства распределений p(x,q) , а  - несмещенная оценка параметра q с конечной дисперсией для некоторой выборки (x1,…,xn) . Тогда условное мат. ожидание при фиксированном t(х) будет несмещенной оценкой q с дисперсией не превосходящей дисперсию .
- несмещенная оценка параметра q с конечной дисперсией для некоторой выборки (x1,…,xn) . Тогда условное мат. ожидание при фиксированном t(х) будет несмещенной оценкой q с дисперсией не превосходящей дисперсию .
Эффективностью оценки  с математическим ожиданием g(q)называется отношение
с математическим ожиданием g(q)называется отношение  .
.
Эффективной называется оценка, эффективность которой равна 1.
Методом моментов называют способ нахождения оценокк к=1,…,r, получаемых как решение системы mk0=mk(q1,…,qr), где  , а mk - моменты порядка кдля независимой выборки с плотностью p(x,q1,…,qn).
, а mk - моменты порядка кдля независимой выборки с плотностью p(x,q1,…,qn).
Теорема.Непрерывные оценки  к к=1,…,r, получаемые методом моментов,состоятельны.
к к=1,…,r, получаемые методом моментов,состоятельны.
Асимптотические св-ва статистических оценок. Состоятельность, асимптотическая эффективность, асимптотическая нормальность.
Асимптотически эффективностью оценки n называется конечным предел  .
.
Асимптотически эффективной называется такая оценка, асимптотическая эффективность к-рой равна единице.
Асимптотически нормальной называется оценка, которая в пределе сходится к нормальному распределению.
Состоятельность и асимптотическая нормальность эмпирических моментов и функций от эмпирических характеристик.
Теорема. Пусть F0 – функция распределения генеральной совокупности и g, Snтаковы, что  , где h – дифференцируема в точке
, где h – дифференцируема в точке  ,
,  , то
, то  , где x - н.р.с.в. с параметрами 0 и
, где x - н.р.с.в. с параметрами 0 и  .
.
Распределение хи квадрат. Стьюдента, Фишера и их использование в мат. статистике.
| Распределение | Формула плотности | E | s |
| ГеометрическоеxÎQ | p(x)=q(1-q)x | (1-q)/q | (1-q)/q2 |
| Пуассона xÎQ | 
| x | x |
| Нормальное xÎR | 
| a | s2 |
| Гамма x>0 | 
| 
| 
|
| Хи квадрат с k степенями свободы х³0 | 
| ||
| Стьюдента с k степенями свободы xÎR | 
| ||
| Фишера х³0 | 
|
Применение математической статистики в экономике
При анализе больших систем наполнителем каналов связи между элементами, подсистемами и системы в целом могут быть:
· продукция, т. е. реальные, физически ощутимые предметы с заранее заданным способом их количественного и качественного описания;
· деньги, с единственным способом описания — суммой;
· информация, в виде сообщений о событиях в системе и значениях описывающих ее поведение величин.
Начнем с того, что обратим внимание на тесную (системную) связь показателей продукции и денег с информацией об этих показателях. Если рассматривать некоторую физическую величину, скажем — количество проданных за день образцов продукции, то сведения об этой величине после продажи могут быть получены без проблем и достаточно точно или достоверно. Но, уже должно быть ясно, что при системном анализе нас куда больше интересует будущее, т.е. сколько этой продукции будет продано за день.
Итак, без предварительной информации, знаний о количественных показателях в системе нам не обойтись. Величины, которые могут принимать различные значения в зависимости от внешних по отношению к ним условий, принято называть случайными (стохастичными по природе). Так, например: пол встреченного нами человека может быть женским или мужским (дискретная случайная величина); его рост также может быть различным, но это уже непрерывная случайная величина — с тем или иным количеством возможных значений (в зависимости от единицы измерения).
Для случайных величин (далее — СВ) приходится использовать особые, статистические методы их описания. В зависимости от типа самой СВ — дискретная или непрерывная это делается по разному.
Дискретное описание заключается в том, что указываются все возможные значения данной величины (например - 7 цветов обычного спектра) и для каждой из них указывается вероятность или частота наблюдений именного этого значения при бесконечно большом числе всех наблюдений.
Можно доказать (и это давно сделано), что при увеличении числа наблюдений в определенных условиях за значениями некоторой дискретной величины частота повторений данного значения будет все больше приближаться к некоторому фиксированному значению — которое и есть вероятность этого значения.
К понятию вероятности значения дискретной СВ можно подойти и иным путем — через случайные события. Это наиболее простое понятие в теории вероятностей и математической статистике — событие с вероятностью 0.5 или 50% в 50 случаях из 100 может произойти или не произойти, если же его вероятность более 0.5 - оно чаще происходит, чем не происходит. События с вероятностью 1называют достоверными, а с вероятностью 0 — невозможными.
Отсюда простое правило: для случайного события X вероятности P(X) (событие происходит) и P(X) (событие не происходит), в сумме для простого события дают 1.
Если мы наблюдаем за сложным событием — например, выпадением чисел 1..6 на верхней грани игральной кости, то можно считать, что такое событие имеет множество исходов и для каждого из них вероятность составляет 1/6 при симметрии кости.
Если же кость несимметрична, то вероятности отдельных чисел будут разными, но сумма их равна 1.
Стоит только рассматривать итог бросания кости как дискретную случайную величину и мы придем к понятию распределения вероятностей такой величины.
Пусть в результате достаточно большого числа наблюдений за игрой с помощью одной и той же кости мы получили следующие данные:
Подобную таблицу наблюдений за СВ часто называют выборочным распределением, а соответствующую ей картинку (диаграмму) — гистограммой.
Рис. 2.1

Какую же информацию несет такая табличка или соответствующая ей гистограмма?
Прежде всего, всю — так как иногда и таких данных о значениях случайной величины нет и их приходится либо добывать (эксперимент, моделирование), либо считать исходы такого сложного события равновероятными — по на любой из исходов.
С ругой стороны — очень мало, особенно в цифровом, численном описании СВ. Как, например, ответить на вопрос: — а сколько в среднем мы выигрываем за одно бросание кости, если выигрыш соответствует выпавшему числу на грани?
Нетрудно сосчитать:
1•0.140+2•0.080+3•0.200+4•0.400+5•0.100+6•0.080= 3.48
То, что мы вычислили, называется средним значением случайной величины, если нас интересует прошлое.
Если же мы поставим вопрос иначе — оценить по этим данным наш будущий выигрыш, то ответ 3.48 принято называть математическим ожиданием случайной величины, которое в общем случае определяется какMx = å Xi · P(Xi); {2 - 1}
где P(Xi) — вероятность того, что X примет свое i-е очередное значение.
Таким образом, математическое ожидание случайной величины (как дискретной, так и непрерывной)— это то, к чему стремится ее среднее значение при достаточно большом числе наблюдений.
Обращаясь к нашему примеру, можно заметить, что кость несимметрична, в противном случае вероятности составляли бы по 1/6 каждая, а среднее и математическое ожидание составило бы 3.5
Поэтому уместен следующий вопрос - а какова степень асимметрии кости - как ее оценить по итогам наблюдений?
Для этой цели используется специальная величина — мера рассеяния — так же как "усредняли" допустимые значения СВ, можно усреднить ее отклонения от среднего. Но так как разности (Xi - Mx) всегда будут компенсировать друг друга, то приходится усреднять не отклонения от среднего, а квадраты этих отклонений. Величину
{2 - 2}
принято называть дисперсией случайной величины X.
Вычисление дисперсии намного упрощается, если воспользоваться выражением
{2 - 3}
т. е. вычислять дисперсию случайной величины через усредненную разность квадратов ее значений и квадрат ее среднего значения.
Таким образом, дисперсия составит 14.04 - (3.48)2 = 1.930. Заметим, что размерность дисперсии не совпадает с размерностью самой СВ и это не позволяет оценить величину разброса. Поэтому чаще всего вместо дисперсии используется квадратный корень из ее значения — т. н. среднеквадратичное отклонение или отклонение от среднего значения: {2 - 4}
составляющее в нашем случае = 1.389.
В случае наблюдения только одного из возможных значений (разброса нет) среднее было бы равно именно этому значению, а дисперсия составила бы 0. И наоборот - если бы все значения наблюдались одинаково часто (были бы равновероятными), то среднее значение составило бы (1+2+3+4+5+6) / 6 = 3.500; усредненный квадрат отклонения — (1 + 4 + 9 + 16 + 25 + 36) / 6 =15.167; а дисперсия 15.167-12.25 = 2.917.
Таким образом, наибольшее рассеяние значений СВ имеет место при ее равновероятном или равномерном распределении.
Отметим, что значения Mx и SX являются размерными и их абсолютные значения мало что говорят. Поэтому часто для грубой оценки "случайности" данной СВ используют т. н. коэффициент вариации или отношение корня квадратного из дисперсии к величине математического ожидания:
Vx = SX/MX . {2 - 5}
В нашем примере эта величина составит 1.389/3.48=0.399.
Итак, запомним, что неслучайная, детерминированная величина имеет математическое ожидание равное ей самой, нулевую дисперсию и нулевой коэффициент вариации, в то время как равномерно распределенная СВ имеет максимальную дисперсию и максимальный коэффициент вариации.
В ряде ситуаций приходится иметь дело с непрерывно распределенными СВ - весами, расстояниями и т. п. Для них идея оценки среднего значения (математического ожидания) и меры рассеяния (дисперсии) остается той же, что и для дискретных СВ. Приходится только вместо соответствующих сумм вычислять интегралы. Второе отличие — для непрерывной СВ: вероятность принятия ею конкретного значения обычно не имеет смысла — как проверить, что вес товара составляет точно 242 кг - не больше и не меньше.
Для всех СВ — дискретных и непрерывно распределенных, имеет очень большой смысл вопрос о диапазоне значений. В самом деле, иногда знание вероятности того события, что случайная величина не превзойдет заданный рубеж, является единственным способом использовать имеющуюся информацию для системного анализа и системного подхода к управлению. Правило определения вероятности попадания в диапазон очень просто — надо просуммировать вероятности отдельных дискретных значений диапазона или проинтегрировать кривую распределения на этом диапазоне.