По данным публикаций периодической печати, интернета и т.д. выбрать достаточную информацию для анализа и провести его с объяснением, сделать вывод
Основу программы SPSS составляет SPSS Base (базовый модуль), предоставляющий разнообразные возможности доступа к данным и управления данными. Он содержит методы анализа, которые применяются чаще всего. SPSS Base включает все процедуры ввода, отбора и корректировки данных, а также большинство предлагаемых в SPSS статистических методов. Наряду с простыми методиками статистического анализа, такими как частотный анализ, расчет статистических характеристик, таблиц сопряженности, корреляций, построения графиков, этот модуль включает t-тесты и большое количество других непараметрических тестов, а также усложненные методы, такие как многомерный линейный регрессионный анализ, дискриминантный анализ, факторный анализ, кластерный анализ, дисперсионный анализ, анализ пригодности (анализ надежности) и многомерное шкалирование [1].
В данном пособии содержится базовая информация об основных методах компьютерной обработки данных.
Анализ данных с применением компьютера включает в себя несколько этапов.
1. Подготовительный этап: определение структуры данных.
2. Ввод данных в компьютер в соответствии с их структурой и требованиями программы.
3. Задание метода обработки данных в соответствии с задачами исследования.
4. Интерпретация результатов обработки.
При работе с данными используются два основополагающих понятия: единица анализа и переменная. Единица анализа – это элементарная, единичная часть объекта исследования. Единица анализа чаще всего совпадает с единицей наблюдения, в социологии, как правило, этой единицей является отдельный респондент. Следовательно, единицей анализа, становится информация, содержащаяся в анкете, чаще всего заполняемой одним респондентом.
Переменная - элементарный показатель, признак, характеризующий одно из изучаемых свойств единицы анализа. Простейшие переменные – вопросы анкеты, к примеру, пол и возраст респондента. Значения переменных – варианты анкеты, выбранные респондентами в качестве ответа.
Например, необходимо провести опрос, и выяснить электоральные предпочтения избирателей в отношении политических партий. Анкета может выглядеть следующим образом, представленном на рисунке 1.

Рисунок 1. Анкета: электоральные предпочтения избирателей в отношении политических партий.
Если проведен опрос 30 респондентов, то единицами анализа в данном случае будут все данные опроса – 30 анкет, заполненных респондентами. Одна анкета – одна единица анализа. Переменными каждой единицы анализа будут вопросы анкеты, значения переменных – ответы респондентов – отмеченные варианты вопроса анкеты (если применяется номинальное шкалирование), числовые значения (например, возраст респондента), или буквенные значения (текстовая информация, например, населенный пункт).
Кодирование и кодировочная таблица
Для того чтобы полученные данные можно было обработать, прежде всего, следует создать кодировочную таблицу. Кодировочная таблица устанавливает соответствие между отдельными вопросам анкеты и переменными, используемыми при компьютерной обработке данных.
Например, вопросу анкеты «За какую партию Вы проголосовали бы, если бы выборы состоялись в ближайшее воскресенье?» может соответствовать имя переменной var1, или party. В версии 13.0 SPSS имя переменной нужно задавать латинскими буквами, цифрами, без пробелов, до 8 символов, причем первым символом имени должна быть буква. Переменные могут принимать различные значения. Например, переменная «пол» может иметь два возможных значения: «женский» и «мужской».
Кодировочная таблица определяет кодовые числа, соответствующие отдельным значениям переменных; например, значению «женский» может соответствовать цифра «1», а значению «мужской» — «2». Для нашей анкеты мы можем составить следующую кодировочную таблицу. Она приводится в самой анкете.
Предположим, что 10 анкет были заполнены следующим образом, представленным в таблице 1.
Таблица 1
Матрица данных
| number | Var1 | Var2 | age | terr |
| Единая Россия | женский | Сургут | ||
| Единая Россия | мужской | Нефтеюганск | ||
| КПРФ | мужской | Нефтеюганск | ||
| Единая Россия | женский | Нефтеюганск | ||
| Правое дело | мужской | Нижневартовск | ||
| КПРФ | женский | Нижневартовск | ||
| Справедливая Россия | мужской | Сургут | ||
| Справедливая Россия | женский | Сургут | ||
| Справедливая Россия | мужской | Сургут | ||
| Единая Россия | женский | Сургут |
Данные, предназначенные для обработки в SPSS для Windows, должны быть представлены в виде такой матрицы. Матрица данных состоит из определенного числа строк и столбцов. Строки и столбцы образуют прямоугольную таблицу. При этом каждая строка соответствует одной анкете, а каждый столбец — одной переменной. Так как в нашем небольшом опросе участвовало 10 респондентов, матрица содержит 10 строк. Каждая строка включает четыре столбца для переменных number (номер анкеты), var1 (первый вопрос анкеты «За какую партию Вы проголосовали бы, если бы выборы состоялись в ближайшее воскресенье?»), var2 (пол), age (возраст) и terr (населенный пункт).
Для работы со статистической компьютерной программой SPSS прежде всего необходимо иметь результаты проведенного опроса (заполненные опросные листы).
По выбранным отдельным вопросам, либо по всем вопросам опросного листа, необходимо выявить статистически значимые закономерности; определить статистические распределения вариантов ответов; оценить близость к нормальному закону распределения. Программа SPSS позволяет выводить на печать необходимые таблицы, строить графики, диаграммы и/или гистограммы.
Изучив полученные данные и сделав окончательные выводы, требуется сформировать итоговый отчет с подробным анализом результатов социологического исследования [2].
2.1. Пример использования программы при расчете коэффициента корреляции
Как было указано выше, корреляция - это исследование комбинаций непрерывных переменных. Графическое представление зависимости между переменными можно получить с помощью диаграммы рассеяния. Для построения диаграммы рассеяния используются пункты меню:
Graphs – Scatter – Simple – Define – выбор переменных
Диаграмма позволяет на глаз оценить зависимость двух переменных (Рис.2) 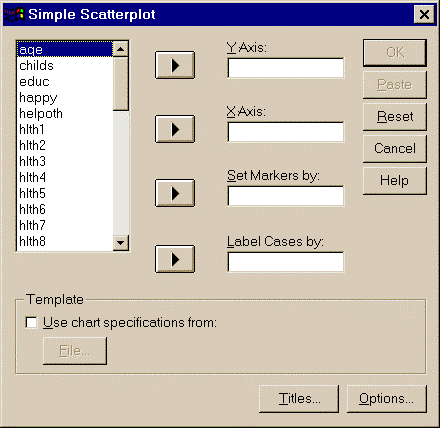
Рисунок 2. Построение диаграммы рассеяния
Поверх уже созданной диаграммы в окне вывода можно наложить линию наименьших квадратов. В окне Редактора графиков (чтобы его вызвать, необходимо два раза щелкнуть левой клавишей мыши на графике в окне вывода) требуется задать: Charts – Options – Fit Line – Total (Рис. 3)
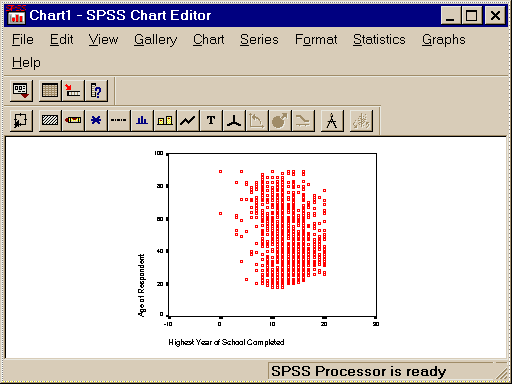
Рисунок 3 Наложение линии наименьших квадратов поверх диаграммы рассеяния
Если требуется обнаружить квадратичную или кубическую зависимость, необходимо в окне редактора графиков выбирать Fit Options.
Информацию о зависимости между переменными можно получить, вычислив коэффициент корреляции Пирсона r:
r = 1 – прямая зависимость;
r = -1 - обратная зависимость;
r = 0 - отсутствие зависимости (вернее, в данном случае линейную зависимость установить не удается и можно попытаться установить нелинейную зависимость, используя диаграммы рассеяния – см. выше). Для вычисления коэффициента корреляции Пирсона используются пункты меню:
Statistics – Correlate - Bivariate – выбор переменных – Correlation Coefficients - Pearson (рис. 4)
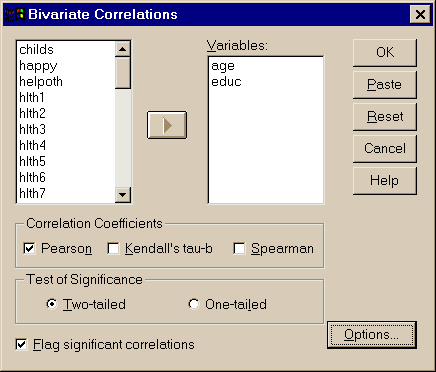
Рисунок 4. Вычисление коэффициента корреляции Пирсона
Для каждой выбранной пары переменных принимается нулевая гипотеза о том, что линейная зависимость между ними отсутствует.
Результаты вычислений помещаются в таблицу Correlations в окне вывода:
Pearson Correlation – коэффициент корреляции;
Sig. (2-tailed) – уровень значимости коэффициента;
N - количество записей в файле данных, по которым делался расчет.
Особое внимание следует обратить на уровень значимости – любая значимость выше 0.05 (5%) подтверждает нулевую гипотезу (о том, что в генеральной совокупности значение коэффициента корреляции равно нулю).
Для использования коэффициента корреляции Пирсона необходимо, чтобы все переменные были непрерывными и данные являлись бы случайной выборкой из генеральной совокупности с нормальным распределением. В том случае, когда какое-либо из этих условий не выполняется и коэффициент Пирсона использовать нельзя, применяются так называемые непараметрические критерии и, в частности, коэффициент ранговой корреляции Спирмена. Его значение также заключено между –1 и +1, интерпретация осуществляется так же, как и интерпретация значений коэффициента Пирсона Statistics – Correlate - Bivariate – выбор переменных— Correlation Coefficients – Spearman [2].
Коэффициент Спирмена менее мощный, чем коэффициент Пирсона, поскольку в нем используется меньше информации о данных; тем не менее он является весьма полезным и часто используется в случае невозможности использования критерия Пирсона.
Как уже подчеркивалось ранее, при интерпретации результатов исследования комбинации переменных с помощью корреляции, необходимо помнить, что сильная корреляционная зависимость между переменными совсем не означает, что одна является причиной другой.
Результаты выполнения процедур SPSS выводятся в окно, называемое Output Navigator (Навигатор Вывода). Непосредственно в окне Навигатора можно отредактировать выводимые результаты и создать документ, содержащий именно то, что необходимо исследователю для создания полноценного отчета о результатах анализа опросных листов.
Навигатор вывода можно использовать для того, чтобы:
o просматривать выводимые данные;
o показывать или скрывать выбранные таблицы и диаграммы;
o изменять порядок следования элементов вывода;
o переходить к Редактору Таблиц, Редактору Текста или Редактору Диаграмм;
o перемещать объекты SPSS в другие приложения (например, документ текстового редактора Word) [4].
Большинство результатов в SPSS выводится в форме таблиц. Их вид может быть изменен пользователем, который может управлять представлением строк, столбцов и слоев таблицы. Таблицы такого типа называются в SPSS "pivot table" (мобильная таблица). Для редактирования таблицы необходимо два раза щелкнуть на ней в правой части окна Навигатора Вывода. Это действие запускает Редактор Мобильной Таблицы. Используя пункт меню Pivot – Pivoting Trays, можно активизировать окно Pivoting Trays 1 (рис. 5).
Рисунок 5. Окно Pivoting Trays группировки данных в таблице (изменения меток строк и столбцов, порядок отображения категорий и т.п.)
Используя Редактор Мобильной Таблицы можно перемещать и менять местами строки (столбцы), поворачивать метки строк и столбцов: Format - Rotate Inner Column Labels или Rotate Outer Row Labels.
Некоторые элементы вывода в программе SPSS отображаются только в виде текста, а не в виде таблицы или диаграммы. Эти текстовые элементы отображаются равномерным шрифтом, например Courier. Равномерный шрифт позволяет выравнивать содержимое вывода, например, диаграмму «ствол - и – листья». Содержимое текстового вывода можно редактировать, используя стандартные возможности Windows, либо скопировав это содержимое в текстовый редактор (например, Word). В окно Навигатора Вывода могут также быть добавлены текстовые элементы, не соединенные ни с какой таблицей или диаграммой. Для этого необходимо щелкнуть мышью на объекте Навигатора, который должен предшествовать вставляемому текстовому элементу, выбрать в меню: Insert - New Title или Insert - New Text, щелкнуть дважды на новом объекте и вводить текст в появившееся поле [3].
Используя Редактор, пользователь может преобразовать этот график или воспользоваться имеющимся списком типов графиков и представить те же данные в другом виде, а также:
- редактировать заголовки и метки осей;
- редактировать цвета и способы заштриховки столбиков;
- добавлять заголовки;
- изменять положение осевой линии графика;
- добавлять аннотации;
- добавлять внешнюю рамку и т.д.
При самостоятельной работе с программой SPSS исследователь может использовать мощные возможности поддержки пользователя. Пункт основного меню Help позволяет получать справки, подсказки, изучать примеры и уроки, для более правильного понимания используемых статистических методов и верной интерпретации получаемых результатов.
Список литературы
- А. Ю. Алексеева, О. Г. Ечевская, Г. Д. Ковалева, П. С. Ростовцев. Анализ социологических данных с применением пакета SPSS. Сборник практических заданий. — Новосибирск: Редакционно-издательский центр НГУ, 2003. – 523с.
- Бююль Ахим, Цёфель Петр. SPSS: Искусство обработки информации. Анализ статистических данных и восстановление скрытых закономерностей: Пер. с нем. / Ахим Бююль, Петр Цёфель — Спб.: «ДиаСофтЮП», 2005—608 стр.
- Наследов А. Д. Математические методы психологического исследования: Анализ и интерпретация данных: Учебное пособие. — СПб.: Речь, 2004. — 392 с.
- Наследов А. Д. SPSS: Компьютерный анализ данных в психологии и социальных науках. 2-е изд. — СПб.: Питер, 2006. – 429с.
- Пациорковский В. В., Пациорковская В. В. SPSS для социологов. Учебное пособие. — М.: ИСЭПН РАН, 2005. — 433 с.