Завдання лексичного аналізу
Лексичний аналіз
Роль лексичних аналізаторів
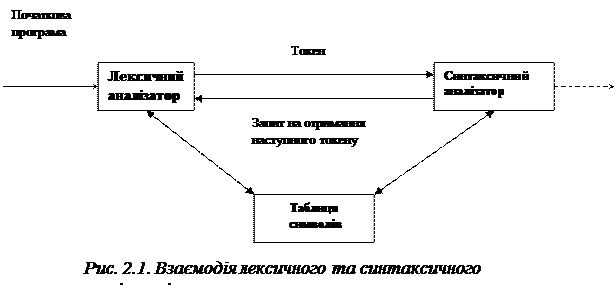
Лексичний аналізатор являє собою першу фазу компілятора. Його основне завдання полягає в читанні нових символів і видачі послідовності токенів, використовуваних синтаксичним аналізатором у своїй роботі. На рис. 2.1 схематично показана взаємодія лексичного й синтаксичного аналізаторів, що звичайно реалізується шляхом створення лексичного аналізатора як підпрограма синтаксичного аналізатора (або підпрограми, викликуваної ним). При одержанні запиту на наступний токен лексичний аналізатор зчитує вхідний потік символів до точної ідентифікації наступного токена.
 |
Оскільки лексичний аналізатор є частиною компілятора, що зчитує вхідний текст, він може також виконувати деякі вторинні завдання інтерфейсу. До них, наприклад, відносяться видалення з тексту вхідної програми коментарів і не несучих значеннєвого навантаження проміжків (а також символів табуляції й нового рядка). Ще одна завдання полягає в узгодженні повідомлень про помилки компіляції й тексту вхідної програми. Наприклад, лексичний аналізатор може підрахувати кількість лічених рядків і вказати рядок, що викликав помилку. На жаль, особливо в складних програмах і складних мовах програмування така вказівка помилки не завжди є вірною — іноді помилка може бути розпізнана тільки після зчитування декількох рядків. Такі ситуації можуть зустрічатися й у комерційних компіляторах, хоча в цьому випадку вони досить рідкі.
У деяких компіляторах лексичний аналізатор створює копію тексту вхідної програми із вказівкою помилок. Якщо вхідна мова підтримує макроси й директиви препроцесора, то вони також можуть бути реалізовані лексичним аналізатором.
Найчастіше робота лексичного аналізатора складається із двох фаз - сканування й лексичного аналізу. Фаза сканування відповідає за виконання найпростіших завдань, у той час як на фазу лексичного аналізу покладають більш складні завдання. Так, наприклад, компілятор може використати сканер для видалення із вхідного тексту зайвих проміжків.
Завдання лексичного аналізу
Є ряд причин, по яких фаза аналізу компіляції розділяється на лексичний і синтаксичний аналізи.
1. Мабуть, найбільш важливою причиною є спрощення розробки. Відділення
лексичного аналізатора від синтаксичного часто дозволяє спростити одну з фаз аналізу. Наприклад, включення в синтаксичний аналізатор коментарів і проміжків істотно складніше, ніж видалення їх лексичним аналізатором, При створенні нової мови поділ лексичних і синтаксичних правил може привести до більше чіткої і ясної побудови мови.
2. Збільшується ефективність компілятора. Окремий лексичний аналізатор дозволяє створити спеціалізований і потенційно більш ефективний процесор
для рішення поставленого завдання. Оскільки на читання вихідної програми й розбір її на токени витрачається багато часу, спеціалізовані технології буферизації йобробки токенів можуть істотно підвищити продуктивність компілятора.
3. Збільшується переносність (мобільність) компілятора. Особливості вхідного алфавиту та інші специфічні характеристики використовуваних пристроїв можуть обмежувати можливості лексичного аналізатора. Наприклад, у такий спосіб може бути вирішена проблема спеціальних нестандартних символів, таких як ↑ в Pascal.
Існує ряд спеціалізованих інструментів, призначених для автоматизації побудови лексичних та синтаксичних аналізаторів, навіть і у тому випадку, коли вони розділені.
Токени, шаблони, лексеми
Говорячи про лексичний аналіз, ми використаємо терміни "токен", "шаблон" й "лексема" кожний у своєму власному визначенні. Приклади їхнього використання наведені на рис. 2.2. Загалом кажучи, у вхідному потоці існує набір рядків, для яких як вихід отримуємо один і той самий токен. Цей набір рядків описується правилом, іменованим шаблоном (pattern), пов'язаним з токеном. Про шаблон говорять, що він відповідає (match) певному рядку в наборі. Лексема ж являє собою послідовність символів вхідної програми, що відповідає шаблону токена. Наприклад, в інструкції Pascal
const pi = 3.1416;
підрядок pi являє собою лексему токена "ідентифікатор". Приклади інших токенів наведено на рис. 2.2.
| Токен | Приклад лексем | неформальний опис шаблона |
| const | const | const |
| if | if | if |
| relation | <, <=, =, <>, >, >= | < або <= або = або про або > або >= |
| id | pi, count, D2 | Буква, за котрою ідуть букви або цифри |
| num | 3.1416, 0, 6.02E23 | Будь-яка числова константа |
| literal | "core dumped" | Будь-які символи між парними лапками, за виключенням самих лапок |
Рис. 2.2. Приклади токенів
Будемо розглядати токени як термінальні символи граматики вхідної мови, для позначення яких використовувати виділення іншим шрифтом. Лексеми, що відповідають шаблонам токенів, представляють у вхідній програмі рядки символів, які розглядаються разом як лексична одиниця.
У більшості мов програмування в якості токенів виступають ключові слова, оператори, ідентифікатори, константи, рядки літералів і символи пунктуації, наприклад дужки, коми й крапки з комами. У наведеному вище прикладі, коли у вхідному потоці зустрічається послідовність символів pi, синтаксичному аналізатору повертається токен, що представляє ідентифікатор. Повернення токена найчастіше реалізується шляхом передачі цілого числа або покажчика, що відповідає системному токену.
Шаблон - правило, що описує набір лексем, які можуть представляти певний токен у вхідній програмі. Так, шаблон токена const (рис. 2.2) являє собою просто рядок const, що є ключовим словом. Шаблон токена relation - набір всіх шести операторів порівняння в Pascal. Для точного опису шаблонів складних токенів типу id (для ідентифікатора) і num (для числа) потрібно використати регулярні вирази, яким присвячений розділ 2.2.
У багатьох мовах ряд рядків є зарезервованим, тобто їхній зміст визначений і не може бути змінений користувачем. Якщо ключові слова не зарезервовані, лексичний аналізатор повинен уміти визначити, із чим він має справу - ключовим словом або ідентифікатором, уведеним користувачем.
Атрибути токенів
Якщо шаблону відповідає кілька лексем, лексичний аналізатор повинен забезпечити додаткову інформацію про лексеми для наступних фаз компіляції. Наприклад, шаблон num відповідає як рядку 0, так й 1, і при генерації коду надто важливо знати, який саме рядок відповідає токену.
Лексичний аналізатор зберігає інформацію про токени у пов'язаних з ними атрибутах. Токени визначають роботу синтаксичного аналізатора; атрибути – трансляцію токенів. На практиці токени звичайно мають єдиний атрибут – покажчик на запис у таблиці символів, у якій зберігається інформація про токен. Для діагностичних цілей можуть знадобитися як лексеми ідентифікаторів, так і номера рядків, у яких вони вперше з'явилися в програмі. Вся ця (й інша) інформація може зберігатися в записах у таблиці символів.
Приклад 2.1
Токени й пов'язані з ними значення атрибутів для інструкції Fortran
Е = М*C**2
записуються як послідовність пар:
<id, покажчик на запис у таблиці символів для Е>
<assign_op, >
<id, покажчик на запис у таблиці символів для М>
<mult_op,>
<id,покажчик на запис у таблиці символів для C>
<ехр_ор, >
<num,ціле значення 2>.
Помітимо, що в деяких парах немає необхідності в значенні атрибута — першого компонента цілком достатньо, щоб ідентифікувати лексему. У цьому невеликому прикладі токен numзаданий атрибутом із цілим значенням. Компілятор може зберігати рядок символів, що становлять число, у таблиці символів, зробивши, таким чином, атрибут токена numпокажчиком на запис у таблиці символів.
Алфавит, рядки і мови