Федеральное государственное бюджетное образовательное учреждение высшего профессионального образования
Министерство образования и науки Российской Федерации
Российский химико-технологический университет имени Д.И. Менделеева
Факультет информационных технологий и управления
Кафедра информационных компьютерных технологий
ВЫПУСКНАЯ КВАЛИФИКАЦИОННАЯ РАБОТА БАКАЛАВРА
по направлению «Информационные системы и технологии»
на тему:
«Разработка элементов пользовательского интерфейса для облачной системы взаимодействия с кластером»
Заведующий кафедрой ИКТ,
д.т.н., профессор Кольцова Э.М.
Руководитель
ст. преп. Васецкий А.М.
Аспирант Куркин К.В.
Студент Балашов Е.П.
Москва
ОГЛАВЛЕНИЕ
ВВЕДЕНИЕ.. 4
1. ЛИТЕРАТУРНЫЙ ОБЗОР. 5
1.1 Анализ информационных технологий в области высокопроизводительных вычислений 5
1.2 Доступ к технологиям высокопроизводительных вычислений. 5
1.3 Структура вычислительного кластера. 6
1.3.1 Преимущества кластерной архитектуры.. 8
1.3.2 Требования к кластерной архитектуре. 8
1.4 Облачные вычисления. 9
1.4.1 Использование суперкомпьютеров в образовании и промышленности. 9
1.4.2 Характеристики облачных вычислений. 10
1.5 Обзор существующих подходов к созданию облачных платформ для вычислений. 11
1.5.1 Аппаратно-программный комплекс «NanoCloud». 12
1.5.2 «Персональный виртуальный компьютер». 13
1.5.3 Многопрофильная инструментально–технологическая платформа CLAVIRE.. 16
2. ТЕОРЕТИЧЕСКАЯ ЧАСТЬ. 18
2.1 Выбор оптимальной OC.. 18
2.2 Веб-сервер Apache. 20
2.3 Фреймворк программной системы.. 23
2.3.1 Концепция PHP-фреймворков. 23
2.3.2 Случаи использования PHP-фреймворка. 25
2.3.3 Обзор современных фреймворков. 25
2.3.4 Преимущества использования фреймворка. 31
2.3.5 Обоснование выбора фреймворка. 32
2.4 Выбор СУБД.. 32
2.4.1 Реляционная СУБД MySQL.. 33
2.5 Организация системы контроля версий. 34
2.6 Набор инструментов «Bootstrap». 37
2.7 Библиотека «Highcharts». 38
3. ПРАКТИЧЕСКАЯ ЧАСТЬ. 40
3.1 Интерфейс для регистрации пользователей. 40
3.2 Интерфейс для модерации пользовательских учетных записей и задач. 44
3.3 Визуализация результатов. 49
4. ОПИСАНИЕ ПРОГРАММЫ... 51
4.1 Общие сведения. 51
4.2 Функциональное назначение. 51
4.3 Описание логической структуры.. 51
4.4 Используемые технические средства. 53
4.5 Вызов и загрузка. 54
4.6 Входные и выходные данные. 54
5 РУКОВОДСТВО ПРОГРАММИСТА.. 57
5.1 Назначение и условия применения программы.. 57
5.2 Характеристика программы.. 57
5.3 Обращение к программе. 57
5.4 Входные и выходные данные. 57
ВЫВОДЫ... 61
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ... 62
ПРИЛОЖЕНИЕ.. 65
Приложение 1. Листинг программы.. 66
Приложение 2. Текст доклада. 85
Приложение 3. Иллюстрационные материалы к докладу. 88
ВВЕДЕНИЕ
Разработка программ для параллельных вычислительных систем (ПВС) является сложной задачей. Одним из вариантов ее упрощения является применение предметно–ориентированных пакетов прикладных программ (ППП) со встроенной поддержкой параллельных вычислений. Однако, такие пакеты сложны в установке и администрировании. Пользователи, как правило, не могут установить, настроить и поддерживать работоспособность этих пакетов самостоятельно. Дополнительную сложность представляет перенос программ, подготовленных в таком пакете, с персонального компьютера пользователя на ПВС и ее запуск в параллельном режиме.
Облачные технологии позволяют решить перечисленные выше проблемы с использованием пакетов прикладных программ. Вместо установки на персональные компьютеры пользователей, ППП устанавливаются в облачной платформе, и пользователи работают с ними удаленно. При этом установка ППП выполняется квалифицированными администраторами облачной платформы, а пользователи сразу получают доступ к установленным и настроенным пакетам.
Актуальной является задача создания облачной платформы, обеспечивающей возможность предоставлению пользователям ППП для параллельных вычислений, интегрированных с ПВС. Под интеграцией понимается возможность запуска задач на ПВС из графического интерфейса ППП и обработка с его же помощью результатов расчётов.
1. ЛИТЕРАТУРНЫЙ ОБЗОР
1.1 Анализ информационных технологий в области высокопроизводительных вычислений
Современные расчётные задачи, зачастую являются весьма ресурсоёмкими, и мощности обычных персональных ЭВМ может быть недостаточно при моделировании сложных процессов. Современные технологии позволяют упростить проведение сложных расчётов, задействовав удалённые вычислительные ресурсы [1]. Можно выделить несколько подходов, позволяющих облегчить жизнь рядовому пользователю:
– облачные вычисления, рассматриваемые в качестве моделей предоставления услуг, в которых пользователь получает доступ к различным ресурсам в виде Интернет-сервиса [2];
– веб-лаборатории или хабы (англ. hub), базирующиеся на технологии web 2.0 и направленные на организацию научных сообществ с предоставлением пользователям развитых средств коммуникации и взаимодействия.
1.2 Доступ к технологиям высокопроизводительных вычислений
К задачам, требующим проведения сложных расчётов (англ. Grand Challenges) по классификации правительства США [3], относят следующие:
– механика сплошных сред;
– прогнозирование погоды,
– климата и изменений в атмосфере,
– приборостроение;
– генетика;
– астрономия и др.
Подобные задачи, в которых необходимо использование высокопроизводительных вычислений, невозможно решать эффективно и зачастую невозможно решать вообще, без использования сверхмощных вычислительных ресурсов, предоставляемых «суперкомпьютерами». Благодаря этому становится реальным получение результатов расчетов до нескольких порядков быстрее. Тем не менее, к основным особенностям использования суперкомпьютерных систем относятся их высокая стоимость и большие затраты, связанные с их эксплуатацией.
Другой, не менее важной проблемой, становится нехватка прикладного программного обеспечения. Отсутствие открытых программных пакетов для моделирования вынуждает пользователей покупать их коммерческие аналоги.
В некоторых случаях стоимость программных решений и их дальнейшая поддержка сопоставима со стоимостью покупки такой системы, а иногда и значительно превышает ее.
На решение данных проблем, а также в связи с активным развитием технологии виртуализации и каналов связи, основной задачей последних лет стала попытка упрощения доступа к вычислительным кластерам и прикладному программному обеспечению. Это стало возможным в связи с последовательным развитием облачных вычислений (cloud computing) [4].
Также была разработана концепция виртуальных информационно–вычислительных веб-лабораторий или «хабов» [5], позволяющая организовывать предметно–ориентированные научные сообщества с предоставлением пользователям развитых средств коммуникации и взаимодействия, а также доступом к прикладным моделям данных.
1.3 Структура вычислительного кластера
Наибольшее распространение среди суперкомпьютерных архитектур для решения ресурсоемких задач получили вычислительные кластеры [6]. Это стало возможным благодаря их экономической эффективности при решении широкого класса вычислительных задач. В списке самых мощных вычислительных систем Топ-500 из суперкомпьютеров, представленных в 2013 году, 85% были построены по кластерной технологии [7].
Вычислительный кластер представляет собой набор взаимосвязанных автономных компьютеров (вычислительных узлов), которые работают совместно, как единый интегрированный вычислительный ресурс (рис. 1.1).
Процессор вычислительного узла кластера работает только со своим локальным адресным пространством памяти, а доступ к удаленной памяти других узлов обеспечивается через механизм передачи сообщений. Такая организация вычислений исключает возникновение конфликтов при обращении к памяти и возникновение проблемы когерентности кэш-памяти.
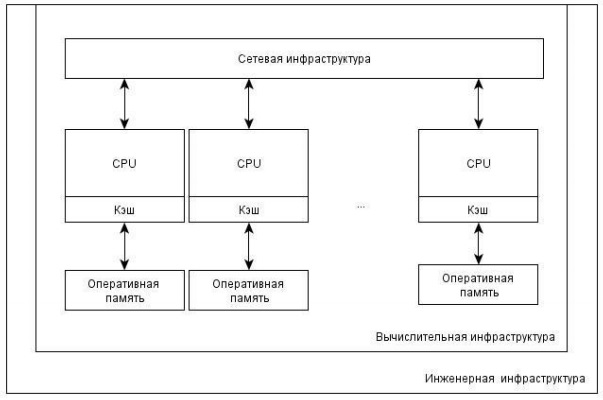
Рисунок 1.1. Общая схема организации кластерных вычислительных систем с распределенной памятью.
В РХТУ им. Д. И. Менделеева на кафедре «Информационных компьютерных технологий» был создан научно-образовательный центр «Высокопроизводительные параллельные вычисления». Центр имеет мощный вычислительный кластер со следующими характеристиками:
– вычислительный кластер из 24 четырехъядерных процессов Intel Xeon X5570, итого 96 вычислительных ядер, 144 GB RAM, 3.6 TB HDD
– управляющий узел кластера: 2 четырехъядерных процессора Intel Xeon X5570, 24 GB RAM;
– система хранения данных ReadyStorage NAS 3160, 12 TB;
– вычислительная сеть (InfiniBand);
– управляющая сеть (Gigabit Ethernet);
– управляющий узел для Tesla: 2 четырехъядерных процессора Intel Xeon X5570, 12 GB RAM;
– вычислительный ускоритель Tesla GPU S1070: 4 графических процессора, 960 вычислительных ядер [8].
1.3.1 Преимущества кластерной архитектуры
Преимущества кластерной архитектуры заключаются в:
– эффективности: компоненты общего назначения, на базе которых создаются кластерные системы, а так же специальные мероприятия по настройке системного программного обеспечения позволяют добиться высокой эффективности кластерных вычислительных систем при решении широкого круга вычислительных задач;
– масштабируемости: вычислительная система, построенная по кластерной архитектуре, состоит из одинаковых независимых вычислительных модулей, что позволяет строить системы самого широкого круга вычислительных 18 возможностей, от небольших кластеров рабочих групп до вычислительных систем масштаба группы предприятий;
– стоимости владения: использование в основе кластера вычислительных компонентов общего назначения и распространенных свободных программных средств снижает совокупную стоимость владения кластерной вычислительной системой [9].
1.3.2 Требования к кластерной архитектуре
В зависимости от типа вычислительного кластера к его архитектуре могут накладываться специальные функциональные и не функциональные требования. Так, параллельные программы, на эффективное выполнение которых нацелены высокопроизводительные системы, характеризуются наличием частых обменов данными, эффективность выполнения которых и определяет общую эффективность выполнения программы. В связи с этим на компоненты и архитектуру высокопроизводительной кластерной системы накладываются специальные требования.
Высокопроизводительная кластерная система с распределенной памятью, предназначенная для решения параллельных задач, должна состоять из однородных вычислительных узлов, объединенных специализированной сетью и иметь централизованную точку доступа, администрирования и управления. При этом характеристики вычислительных узлов и сети должны быть согласованы.
1.4 Облачные вычисления
Облачные вычисления – это модель предоставления сервиса (услуги), при которой пользователь имеет возможность получить повсеместный, удобный доступ по требованию к пулу (англ. pool) разделяемых, конфигурируемых ресурсов (например, сетей, серверов, памяти, приложений), которые могут быть быстро предоставлены пользователю и с минимальными для пользователя усилиями по взаимодействию с сервис–провайдерами в процессе получения доступа к ресурсам [10].
1.4.1 Использование суперкомпьютеров в образовании и промышленности
Ввиду отсутствия для ряда отраслей промышленности открытых программных пакетов для моделирования пользователи вынуждены покупать их коммерческие аналоги. В некоторых случаях стоимость программных решений и их дальнейшая поддержка сопоставима со стоимостью покупки кластерной системы, а иногда и значительно превышает ее. Поэтому большинство компаний малого и среднего бизнеса, а также вузы, не могут позволить себе приобретение промышленного суперкомпьютера и необходимого программного обеспечения.
Таким образом, в связи с активным развитием технологии виртуализации и каналов связи, основной задачей последних лет стала попытка упрощения доступа к прикладному программному обеспечению и средствам его разработки. Это стало возможным в связи с последовательным развитием технологий облачных вычислений (cloud computing) [10].
1.4.2 Характеристики облачных вычислений
Национальным институтом стандартов и технологий США зафиксированы следующие обязательные характеристики облачных вычислений [11]:
– самообслуживание по требованию (англ. self service on demand), при котором потребитель самостоятельно определяет и изменяет вычислительные 25 потребности, такие как серверное время, скорости доступа и обработки данных, объем хранимых данных без взаимодействия с представителем поставщика услуг;
– универсальный доступ по сети, услуги доступны потребителям по сети передачи данных вне зависимости от используемого терминального устройства;
– объединение ресурсов (англ. resource pooling), когда поставщик услуг объединяет ресурсы для обслуживания большого числа потребителей в единый пул для динамического перераспределения мощностей между потребителями в условиях постоянного изменения спроса на мощности; при этом потребители контролируют только основные параметры услуги (например, объем данных, скорость доступа), но фактическое распределение ресурсов, предоставляемых потребителю, осуществляет поставщик (в некоторых случаях потребители все-таки могут управлять некоторыми физическими параметрами перераспределения, например, указывать желаемый центр обработки данных из соображений географической близости);
– «эластичность», когда услуги могут быть предоставлены, расширены, сужены в любой момент времени, без дополнительных издержек на взаимодействие с поставщиком, как правило, в автоматическом режиме;
– учет потребления, когда поставщик услуг автоматически исчисляет потребленные ресурсы на определенном уровне абстракции (например, объем хранимых данных, пропускная способность, количество пользователей, количество транзакций) и на основе этих данных оценивает объем предоставленных потребителям услуг.
С точки зрения поставщика, благодаря объединению ресурсов и непостоянному характеру потребления со стороны потребителей, облачные вычисления позволяют экономить на масштабах, используя меньшие аппаратные ресурсы, чем требовались бы при выделенных аппаратных мощностях для каждого потребителя, а за счет автоматизации процедур и модификации выделения ресурсов существенно снижаются затраты на абонентское обслуживание.
С точки зрения потребителя эти характеристики позволяют получить услуги с высоким уровнем доступности (англ. high availability) и низкими рисками неработоспособности, обеспечить быстрое масштабирование вычислительной системы благодаря эластичности без необходимости создания, обслуживания и модернизации собственной аппаратной инфраструктуры.
Удобство и универсальность доступа обеспечивается широкой доступностью услуг и поддержкой различного класса терминальных устройств (персональных компьютеров, мобильных телефонов, планшетных ПК).
1.5 Обзор существующих подходов к созданию облачных платформ для вычислений
В настоящее время в России развивается несколько проектов по созданию облачных платформ для высокопроизводительных вычислений. Можно отметить следующие платформы:
· NanoCloud [12], создаваемая для нужд Национальной нанотехнологической сети под руководством «Курчатовского института».
· «Персональный виртуальный компьютер» – Южно-Уральского государственного университета [13].
· CLAVIRE, создаваемая Институтом информационных технологии механики и оптики, совместно с компанией Ай-Ти [14].
1.5.1 Аппаратно-программный комплекс «NanoCloud»
NanoCloud– это масштабируемый аппаратно–программный комплекс для виртуализации и динамичного управления вычислительными ресурсами и данными Национальной нанотехнологической сети (ННС) и суперкомпьютерного вычислительного комплекса Национального исследовательского центра «Курчатовский институт» на основе технологии облачных вычислений.
NanoCloud включает в себя базовую инфраструктуру облачных вычислений Infrastructure as a Service (IaaS), подборку готовых виртуальных машин Platform as a Service (PaaS), хранилище данных Data as a Service (DaaS), а также веб-приложения Software as a Service (SaaS), веб-сервисы Application as a Service (AaaS) и грид-сервисы Grid as a Service (GaaS).
Важность достижения и актуальность поставленной в проекте цели определяется необходимостью эффективного хранения, обработки и визуализации больших объемов данных в нано- и био-областях, в когнитивных исследованиях, а также необходимостью организации сложных многоступенчатых конвейеров для обработки экспериментальных данных на различных типах вычислительных системах.
Созданный аппаратно-программный комплекс позволяет решать эти проблемы с помощью виртуализации и интеграции различных вычислительных ресурсов в единую среду для хранения данных, расчетов и визуализации.
Целью проекта является создание для участников ННС масштабируемой среды NanoCloud для виртуализации вычислительных ресурсов и научных данных по технологии облачных вычислений, которая основана на новой модели сервисов, предоставляемых высокопроизводительным вычислительным центром.
Основными пользователями в этой модели являются не сами владельцы вычислительных ресурсов (суперкомпьютеров и центров данных), а внешние потребители информационных сервисов, получающие доступ к виртуальным «персональным компьютерам» и виртуальным «параллельным кластерам», а также к долгосрочной памяти, лицензиям на программные продукты и хостингу веб-приложений. При этом владельцы вычислительных ресурсов гарантируют качество базовых сервисов, масштабируемость среды виртуализации и суммарные объемы хранилищ. Они же предоставляют потребителям квоту (а в случае коммерциализации сервисов берут плату) в виде почасовой аренды процессоров, дисков, лицензий и за объем сетевого трафика без первоначальной премии за подключение, а не в виде долгосрочной (годовой, помесячной) подписки на пакет услуг.
Пользователи сервисов облачных вычислений получают доступ к базовым конфигурациям виртуальных машин, сети и дисковых хранилищ, которые они могут сами изменять и расширять, создавая на их основе многоуровневые веб-приложения, надежные масштабируемые сервисы и распределенные рабочие потоки для моделирования физических процессов и анализа экспериментальных данных. При этом пользователю не надо знать или непосредственно контролировать инфраструктуру самих суперкомпьютеров и центров данных, поддерживающих облачные вычисления на принципах IaaS (Infrastrucutre as a Services), SaaS (Software as a Service) и DaaS (Data as a Service), составляющих сегодня основные технологические тренды в области информационных технологий [12].
1.5.2 «Персональный виртуальный компьютер»
На сегодняшний день в Южно-Уральском государственном университете функционируют два суперкомпьютера: «СКИФ-Аврора ЮУрГУ» [15] и «СКИФ Урал» [16]. Для повышения качества инженерно– технического образования было принято решение о модернизации электронной образовательной среды вуза и переходе на инновационные технологии облачных вычислений. Для достижения этой цели на высокопроизводительных вычислительных кластерах ЮУрГУ с характеристиками, представленными в табл. 1, был реализован проект «Персональный виртуальный компьютер» (ПВК).
Табл. 1.1
Технические характеристики суперкомпьютеров ЮУрГУ.

В рамках системы для каждого студента первого курса создан персональный виртуальный компьютер на базе ОС Windows 7, доступ к которому осуществляется с домашнего компьютера, ноутбука, нетбука и др. В результате, в качестве компьютерного класса может быть использована любая учебная аудитория ЮУрГУ оборудованная Wi-Fi сетью и электрическими розетками.
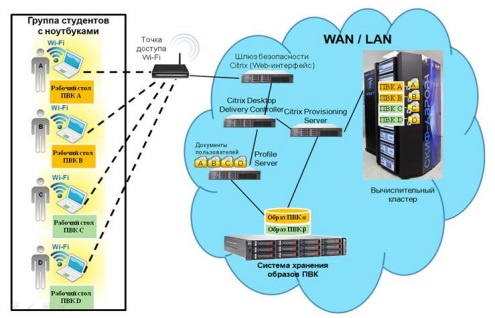
Рис. 1.2. Принцип работы системы «Персональный виртуальный компьютер».
Система ПВК основана на виртуальной серверной инфраструктуре, построенной по технологии Microsoft Hyper – V. В решении использована выделенная система хранения данных, подключенная к узлам кластера по технологии iSCSI over InfiniBand. На виртуальной серверной инфраструктуре создана инфраструктура виртуальных рабочих столов по технологии Citrix XenDesktop VDI Edition. Принципы работы системы ПВК приведены на рис. 1.2
Преимущества платформы ПВК:
– эффективное использование учебных площадей (отпадает необходимость выделять отдельные и специально оборудованные помещения под традиционные компьютерные классы);
– качественно иной уровень получения современных знаний по специальности – студенты получают возможность находиться в процессе обучения в любое время и в любом месте, где есть Интернет;
– возможность быстро создавать, адаптировать и тиражировать образовательные сервисы в ходе учебного процесса;
– возможность для студентов осуществлять обратную связь с преподавателем путем оценки и комментирования предлагаемых им образовательных сервисов;
– гарантия лицензионной чистоты ПО, используемого в процессе обучения;
– сокращение затрат на лицензионное ПО путем создания функционально эквивалентных образовательных сервисов на базе ПО с открытым кодом;
– минимизацию количества лицензий за счет их централизованного использования;
– централизованное администрирование программных и информационных ресурсов, используемых в учебном процессе;
– эффективное использование кластерных вычислительных систем, имеющихся в вузе [13];
1.5.3 Многопрофильная инструментально-технологическая платформа CLAVIRE
Многопрофильная инструментально-технологическая платформа CLAVIRE (CLoud Application VIRtual Environment) обеспечивает создание, разработку и эксплуатацию публичных облачных сред второго поколения, предоставляя доступ к вычислительным ресурсам, прикладным пакетам и композитным приложениям в рамках моделей SaaS и AaaS. CLAVIRE обеспечивает:
– эффективное управление вычислительными, информационными и программными ресурсами распределенных неоднородных вычислительных инфраструктур (включая суперкомпьютеры, ресурсы облачных провайдеров);
– разработка предметно-ориентированных высокопроизводительных композитных приложений, функционирующих на основе облака распределенных прикладных сервисов, а также управление приложениями и предоставление сервисов доступа к ним;
– построение корпоративных облачных инфраструктур, публичных инфраструктур с использованием ресурсов Грид-сред, инфраструктур центров компетенции в различных предметных областях, облачных инфраструктур в рамках парадигмы big data, а также распределенных систем поддержки принятия решений с интенсивным использованием вычислительных технологий.
Платформа CLAVIRE разработана в НИИ Наукоемких компьютерных технологий НИУ ИТМО в 2010 – 2012 гг. по заказу ЗАО «Фирма „АйТи”»[14].
2. ТЕОРЕТИЧЕСКАЯ ЧАСТЬ
2.1 Выбор оптимальной OC
Linux – операционная система с открытым исходным кодом [17]. Она состоит из четырёх основных частей:
Ядро –это операционная система низкого уровня, обрабатывающая файлы, работающая с дисками, сетью и выполняющая другие необходимы операции
Программное обеспечение –включает в себя файловые менеджеры, текстовые редакторы, математические программы и другое программное обеспечение, работающее с различными форматами файлов.
Командный процессор –Пользовательский интерфейс для набора команд, их исполнения и отображения результатов.
«Х» – Графическая система, которая обеспечивает поддержку окон, меню, иконок, мыши и других элементов графического интерфейса пользователя.
Операционная система Linux является клоном Unix, в ней много заимствований, но она не является производной от исходного кода Unix. При возможности разработчики использовали свой подход, отличный от того, что используется в Unix .
В настоящее время существует множество различных версий Linux, построенных на основе единого ядра. Эти версии принято называть дистрибутивами (distributions, distros). Одними из самых известных дистрибутивов являются Mandriva, Xandros, Red Hat, SUSE. Но еще сотни версий уже существуют и появляются каждый день. Такое разнообразие возможно только благодаря идее свободного программного обеспечения. Созданием своих версий занимаются как энтузиасты–одиночки, так и крупные компании, спонсирующие написание и поддержание новых дистрибутивов. ОС Ubuntu сочетает в себе оба подхода. Её разработка спонсируется компанией Canonical Ltd., основанной в 2004 году Марком Шаттлвортом (Mark Shuttleworth), и поддерживается большим сообществом разработчиков и пользователей. Сама Ubuntu основана на дистрибутиве Debian,созданном коллективными усилиями [18].
Причины выбора операционной системы Ubuntu:
Доступ к исходным кодам. За проектом GNU, частью которого является ОС Linux (Ubuntu является разновидносьтю Linux), стоит целая философия, утверждающая, что «программное обеспечение должно быть общедоступным или свободно распространяемым». Хотя это чаще всего означает, что ПО должно быть бесплатным (хотя и не всегда, если судить по успешному продвижению на рынке основанных на Linux продуктов Red Hat и SUSE компании Novell), но гораздо важнее то, что процесс разработки системы открыт и общедоступен [19].
Гибкость –Бесплатное программное обеспечение. В любой точке, если есть доступ к компьютеру, возможно использовать все, что предлагается в качестве компонентов системы Ubuntu. И бесплатным является не только исходный загружаемый дистрибутив системы, но и все последующие ее обновления.
Быстрый доступ к обновлениям. Как только будет выпущена новая версия системы, Ubuntu сообщает и предлагает бесплатно обновить ее автоматически при условии наличия подключения к Интернету.
Круглосуточная техническая поддержка. Для домашних и частных пользователей разнообразная техническая поддержка предоставляется на Web-сайте Ubuntu и форумах в Интернете. Если возникла проблема, ответ приходит за несколько часов (а иногда и минут). Объясняется это тем, что Ubuntu написана добровольцами со всего света, которые постоянно поддерживают связь друг с другом через эти форумы и всегда рады помочь вам, чем могут.
Система может работать без установки. Возможно запустить Ubuntu с CD или DVD, или же с носителя флеш-USB, без необходимости предварительной установки системы на жесткий диск вашего компьютера.
В дистрибутив включены офисные приложения. Ubuntu поставляется с заранее установленным пакетом OpenOffice.org, поэтому можно сразу же заняться созданием документов, электронных таблиц и презентаций, совместимыми с пакетом Microsoft Office.
2.2 Веб-сервер Apache
Информация в Интернете организована с помощью архитектуры, определенной организацией Internet Society (ISOC). Это целеустремленная (хотя и управляемая комитетами) организация, которая поддерживает согласованную работу и операционную совместимость в Интернете [20].
Организация ISOC определяет три способа идентификации ресурсов: унифицированные идентификаторы ресурсов (Uniform Resource Identifier – URI), унифицированные указатели ресурсов (Uniform Resource Locator – URN) и унифицированные имена ресурсов (Uniform Resource Names – URN).
Как показано на рис. 2.1, по существу, унифицированные указатели и имена ресурсов представляют собой частный случай унифицированного идентификатора ресурсов.

Рис. 2.1 Классификация унифицированных идентификаторов ресурсов
Разница между ними заключается в том, что:
• унифицированные указатели ресурсов сообщают, как найти ресурс, описывая его механизм первичного доступа (например, http://admin.com);
• унифицированные имена ресурсов идентифицируют («называют») ресурс без указания на него или сообщают, как получить доступ к нему (например, urn:isbn:0-13-020601-6).
Если доступ к ресурсу возможен только через Интернет, то используется указатель URL. Если же доступ к ресурсу возможен не только через Интернет, но и с помощью других средств, то используется идентификатор URI.
Принцип работы HTTP
HTTP – это клиент-серверный протокол, не хранящий информацию о состоянии сеанса. Клиент запрашивает у сервера «содержимое» заданного URL-адреса. Сервер отвечает, передавая поток данных или возвращая сообщение об ошибке. Затем клиент может запросить следующий объект.
Поскольку протокол HTTP прост, можно легко подключиться к веб-браузеру с помощью утилиты telnet. Для этого достаточно подключиться к порту 80 выбранного веб-сервера. После установления соединения сервер готов принимать НТТР-команды.
Чаще всего используется команда GET, которая запрашивает содержимое документа. Обычно она задается в формате «GET /». В этом случае возвращается корневой документ сервера (как правило, начальная страница). Протокол HTTP чувствителен к регистру символов, поэтому команды следует набирать прописными буквами.
Генерирование содержимого
Помимо работы со статическими документами, HTTP-сервер способен выдавать пользователям страницы, формируемые «на лету». Например, если требуется отобразить текущие время и температуру, сервер вызывает сценарий, предоставляющий эту информацию. Такие сценарии зачастую создаются средствами CGI (Common Gateway Interface – единый шлюзовой интерфейс).
CGI является не языком программирования, а, скорее, спецификацией, описывающей обмен информацией между HTTP-сервером и другими программами. Чаще всего CGI-сценарии представляют собой программы, написанные на языке Perl, Python или РНР. В действительности подойдет практически любой язык программирования, который поддерживает операции ввода-вывода в режиме реального времени.
Встроенные интерпретаторы
Модель CGI обеспечивает высокую гибкость, благодаря которой разработчик веб-приложения может свободно использовать любой интерпретатор или язык сценариев. К сожалению, запуск отдельного процесса в каждом сценарии может стать весьма затруднительным для загруженного веб-сервера, обрабатывающего значительный объем динамического содержания.
Кроме поддержки дополнительных внешних сценариев CGI, многие веб-серверы определяют модульную архитектуру, позволяющую интерпретаторам сценариев, таким как Perl и РНР, самим встраиваться в веб-сервер. Это связывание значительно увеличивает производительность, поскольку веб-сервер больше не обязан запускать отдельный процесс, чтобы обрабатывать каждый запрос сценария. Архитектура, большей частью, скрыта от разработчиков сценариев. Как только сервер видит файл, имя которого заканчивается специфическим расширением (например, .pi или .php), он посылает содержимое файла встроенному интерпретатору для выполнения.
В настоящее время Apache HTTP Server представляет собой хорошо защищённый, высокопроизводительный сервер, предназначенный для обработки HTTP-запросов. Разработка сервера и некоторых смежных проектов поддерживается Apache Software Foundation. Код сервера имеет модульную структуру и, следовательно, может быть легко модифицирован к решению практически любых задач по организации виртуального общения между сервером и клиентом.
Потенциальные уязвимости Apache, как и любого другого программного обеспечения, могут использоваться для реализации атак на систему. Поэтому для повышения безопасности системы Apache может работать в защищённой среде «chroot-jail» [21].
2.3 Фреймворк программной системы