Укажите достоинства и недостатки иерархической модели данных
Иерархическая модель
В иерархической модели связи между данными можно описать с помощью упорядоченного графа (или дерева). Упрощенно представление связей между данными в иерархической модели показано на рис. 2.1.
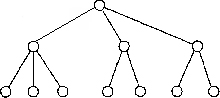
Рис. 2.1. Представление связей в иерархической модели
Для описания структуры (схемы) иерархической БД на некотором языке программирования используется тип данных "дерево". Тип "дерево" схож с типами данных "структура" языков программирования ПЛ/1 и Си и "запись" языка Паскаль. В них допускается вложенность типов, каждый из которых находится на некотором уровне. Тип "дерево" является составным. Он включает в себя подтипы ("поддеревья"), каждый из которых, в свою очередь, является типом "дерево". Каждый из типов "дерево" состоит из одного "корневого" типа и упорядоченного набора (возможно пустого) подчиненных типов. Каждый из элементарных типов, включенных в тип "дерево", является простым или составным типом "запись". Простая "запись" состоит из одного типа, например, числового, а составная – объединяет некоторую совокупность типов, например, целое, строку символов и указатель (ссылку). Пример типа "дерево" как совокупности типов показан на рис. 2.2.
Корневым называется тип, который имеет подчиненные типы и сам не является подтипом. Подчиненный тип (подтип) является потомком по отношению к типу, который выступает для него в роли предка (родителя). Потомки одного и того же типа являются близнецами по отношению друг к другу. В целом тип "дерево" представляет собой иерархически организованный набор типов "запись".
Иерархическая БД представляет собой упорядоченную совокупность экземпляров данных типа "дерево" (деревьев), содержащих экземпляры типа "запись" (записи). Часто отношения родства между типами переносят на отношения между самими записями. Поля записей хранят собственно числовые или символьные значения, составляющие основное содержание БД. Обход всех элементов иерархической БД обычно производится сверху вниз и слева направо.
В иерархических СУБД может использоваться терминология, отличающаяся от приведенной. Так, в системе IMS понятию "запись" соответствует термин "сегмент", а под "записью БД" понимается вся совокупность записей, относящаяся к одному экземпляру типа "дерево". Данные в базе с приведенной схемой (рис. 2.2) могут выглядеть, например, как показано на рис. 2.3.
Для организации физического размещения иерархических данных в памяти ЭВМ могут использоваться следующие группы методов:
 представление линейным списком с последовательным распределением памяти (адресная арифметика, левосписковые структуры);
представление линейным списком с последовательным распределением памяти (адресная арифметика, левосписковые структуры);
представление связными линейными списками (методы, использующие указатели и справочники).
К основным операциям манипулирования иерархически организованными данными относятся следующие:
поиск указанного экземпляра БД (например, дерева со значением 10 в поле Отд_номер);
переход от одного дерева к другому;
переход от одной записи к другой внутри дерева (например, к следующей записи типа Сотрудники);
вставка новой записи в указанную позицию;
удаление текущей записи и т. д.
В соответствии с определением типа "дерево", можно заключить, что между предками и потомками автоматически поддерживается контроль целостности связей. Основное правило контроля целостности формулируется следующим образом: потомок не может существовать без родителя, а у некоторых родителей может не быть потомков. Механизмы поддержания целостности связей между записями различных деревьев отсутствуют.
К достоинствам иерархической модели данных относятся эффективное использование памяти ЭВМ и неплохие показатели времени выполнения основных операций над данными. Иерархическая модель данных удобна для работы с иерархически упорядоченной информацией.
Недостатком иерархической модели является ее громоздкость для обработки информации с достаточно сложными логическими связями, а также сложность понимания для обычного пользователя. На иерархической модели данных основано сравнительно ограниченное количество СУБД, в числе которых можно назвать зарубежные системы IMS, PC/Focus, Team-Up и Data Edge, а также отечественные системы Ока, ИНЭС и МИРИС.