Співвідношення, які застосовуються у розв’язанні задач
Лабораторна робота № 3.
Тема
Статичні функції. Пакет аналізу: „Статистика”.
Мета
Оволодіти методикою автоматизації статистичної обробки даних за допомогою вбудованих засобів Excel.
Теоретичні відомості
В Excel представлено велику кількість статистичних функцій. Деякі з них є вбудованими, інші доступні тільки після встановлення Пакету аналізу.
Статистичні функції дозволяють виконувати статистичний аналіз діапазонів даних. Наприклад, за допомогою статистичної функції можна провести пряму по групі значень, обчислити кут нахилу і точку перетину з віссю Y і інше.
Дістатися до переліку статистичних функцій в Excel можна наступним чином: натиснути кнопку  , у вікні Категорії Майстра функцій вибрати Статистичні, тим самим у вікні Функції відкривши весь їх перелік.
, у вікні Категорії Майстра функцій вибрати Статистичні, тим самим у вікні Функції відкривши весь їх перелік.
FРАСП – повертає F-розподіл ймовірності.
FРАСПОБР – повертає обернене значення для F-розподілу ймовірності.
ZТЕСТ – повертає двостороннє P-значення z-тесту.
БЕТАОБР – повертає обернену функцію до інтегральної функції густини бета-ймовірності.
БЕТАРАСП – повертає інтегральну функцію густини бета-ймовірності.
БИНОМРАСП – повертає окреме значення біноміального розподілу.
ВЕЙБУЛЛ – повертає розподіл Вейбулла.
ВЕРОЯТНОСТЬ – повертає ймовірність того, що значення із діапазону знаходиться в заданих межах.
ГАММАНЛОГ – повертає натуральний логарифм гамма функції, Γ(x).
ГАММАОБР – повертає обернений гамма-розподіл.
ГАММАРАСП – повертає гамма-розподіл.
ГИПЕРГЕОМЕТ – повертає гіпергеометричний розподіл.
ДИСП – повертає дисперсію за вибіркою.
ДИСПА – повертає дисперсію за вибіркою, включаючи числа, текст та логічні значення.
ДИСПР – повертає дисперсію для генеральної сукупності.
ДИСПРА – повертає дисперсію для генеральної сукупності, включаючи числа, текст та логічні значення.
ДОВЕРИТ – повертає довірчий інтервал для середнього значення за генеральною сукупністю.
КВАДРОТКЛ – повертає суму квадратів відхилень.
КВАРТИЛЬ – повертає квартиль множини даних.
КВПИРСОН – повертає квадрат коефіцієнту кореляції Пірсона.
КОВАР – повертає коваріацію, тобто середнє добутків відхилень для кожної пари точок.
КОРРЕЛ – повертає коефіцієнт кореляції між двома множинами даних.
КРИТБИНОМ – повертає найменше значення, для якого біноміальна функція розподілу менше або рівна заданому значенню.
ЛГРФПРИБЛ – повертає параметри експоненціального тренду.
ЛИНЕЙН – повертає параметри лінійного тренду.
ЛОГНОРМОБР – повертає обернений логарифмічний нормальний розподіл.
ЛОГНОРМРАСП – повертає інтегральний логарифмічний нормальний розподіл.
МАКС – повертає максимальне значення із списку аргументів.
МАКСА – повертає максимальне значення із списку аргументів, включаючи числа, текст і логічні значення.
МЕДИАНА – повертає медіану заданих чисел.
МИН – повертає мінімальне значення із списку аргументів.
МИНА – повертає мінімальне значення із списку аргументів, включаючи числа, текст і логічні значення.
МОДА – повертає значення моди множини даних.
НАИБОЛЬШИЙ– повертає k-е найбільше значення з множини даних.
НАИМЕНЬШИЙ– повертає k-е найменше значення в множині даних.
НАКЛОН– повертає нахил лінії лінійної регресії.
НОРМАЛИЗАЦИЯ– повертає нормалізоване значення.
НОРМОБР – повертає обернений нормальний розподіл.
НОРМРАСП – повертає нормальну функцію розподілу.
НОРМСТОБР – повертає обернене значення стандартного нормального розподілу.
НОРМСТРАСП – повертає стандартний нормальний інтегральний розподіл.
ОТРБИНОМРАСП – повертає від’ємний біноміальний розподіл.
ОТРЕЗОК – повертає відрізок, що відсікається на осі лінією лінійної регресії.
ПЕРЕСТ – повертає кількість перестановок для заданого числа об’єктів.
ПЕРСЕНТИЛЬ – повертає k-у персентиль для значень з інтервалу.
ПИРСОН – повертає коефіцієнт кореляції Пірсона.
ПРЕДСКАЗ – повертає значення лінійного тренда.
ПРОЦЕНТРАНГ – повертає відсоткову норму значення в множині даних.
ПУАССОН – повертає розподіл Пуассона.
РАНГ – повертає ранг числа в списку чисел.
РОСТ – повертає значення відповідно до експоненціального тренда.
СКОС – повертає асиметрію розподілу.
СРГАРМ – повертає середнє гармонійне.
СРГЕОМ – повертає середнє геометричне.
СРЗНАЧ – повертає середнє арифметичне аргументів.
СРЗНАЧА – повертає середнє арифметичне аргументів, включаючи числа, текст і логічні значення.
СРОТКЛ – середнє абсолютних значень відхилень точок даних від середнього.
СТАНДОТКЛОН – оцінює стандартне відхилення за вибіркою.
СТАНДОТКЛОНА – оцінює стандартне відхилення за вибіркою, включаючи числа, текст та логічні значення.
СТАНДОТКЛОНП – обчислює стандартне відхилення за генеральною сукупністю.
СТАНДОТКЛОНПА – обчислює стандартне відхилення за генеральною сукупністю, включаючи числа, текст та логічні значення.
СТОШYX – повертає стандартну похибку передбачених значень y для ковзного значення x в регресії.
СТЬЮДРАСП – повертає t-розподіл Ст’юдента.
СТЬЮДРАСПОБР – повертає обернений t- розподіл Ст’юдента.
СЧЁТ – підраховує кількість чисел в списку аргументів.
СЧЁТЗ – підраховує кількість значень в списку аргументів.
ТЕНДЕНЦИЯ – повертає значення у відповідності з лінійним трендом.
ТТЕСТ – повертає ймовірність, яка відповідає критерію Ст’юдента.
УРЕЗСРЕДНЕЕ – повертає середнє множини даних.
ФИШЕР – повертає перетворення Фішера.
ФИШЕРОБР – повертає обернене перетворення Фішера.
ФТЕСТ – повертає результат F-теста.
ХИ2ОБР – повертає обернене значення однобічної ймовірності розподілу хі-квадрат.
ХИ2РАСП – повертає однобічну ймовірність розподілу хі-квадрат.
ХИ2ТЕСТ – повертає тест на незалежність.
ЧАСТОТА – повертає розподіл частот у вигляді вертикального масиву.
ЭКСПРАСП – повертає експоненціальний розподіл.
ЭКСЦЕСС– повертає ексцес множини даних.
Для виконання індивідуальних завдань необхідно буде скористатися функцією ЛИНЕЙН, тому інформація щодо неї розглядається детальніше.
Функція ЛИНЕЙН, розраховує статистику для ряда з використанням методу найменших квадратів, щоб обчислити пряму лінію, яка найкращим чином апроксимує дні. Функція повертає масив, який описує цю пряму.
Рівняння для прямої лінії має наступний вигляд:
 або
або 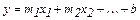 (у випадку декількох діапазонів значень х),
(у випадку декількох діапазонів значень х),
де залежне значення у є функцією незалежного значення х. Значення m – це коефіцієнти, які відповідають кожній незалежній змінній х, а b – це стала. Функція ЛИНЕЙН повертає масив {mn;mn-1;...;m1;b}. ЛИНЕЙН може повертати і регресіонну статистику.
ЛИНЕЙН(відомі_значення_y;відомі_значення_x;конст;статистика).
Відомі_значення_y – це множина значень у, які вже відомі у співвідношенні .
1 Якщо масив відомі_значення_y має один стовпець, то кожний стовпець масиву відомі_значення_x інтерпретується як окрема змінна.
2 Якщо масив відомі_значення_y має один рядок, то кожний рядок масиву відомі_значення_x інтерпретується як окрема змінна.
Відомі_значення_x – це необов’язкова множина значень х, які вже відомі у співвідношенні .
1 Масив відомі_значення_x може містити одну або декілька множин змінних. Якщо використовується тільки одна змінна, то відомі_значення_y і відомі_значення_x можуть мати будь-яку форму, за умови, що вони мають однакову розмірність. Якщо використовується більше однієї змінної, то відомі_значення_y повинні бути вектором (тобто діапазоном висотою в один рядок або шириною в один стовпець).
2 Якщо відомі_значення_x пропускають, то передбачається, що це масив {1;2;3;...} такого ж розміру, як і відомі_значення_y.
Конст – це логічне значення, яке вказує, чи потрібно щоб константа b була рівна 0.
1 Якщо аргумент конст має значення ИСТИНА або пропускається, то b обчислюється звичайним способом.
2 Якщо аргумент конст має значення ЛОЖЬ, то b вважається рівним 0 і значення m підбираються так, щоб виконувалося співвідношення  .
.
Статистика – це логічне значення, яке вказує, чи потрібно повернути додаткову статистику за регресією.
1 Якщо аргумент статистика має значення ИСТИНА, то функція ЛІНЕЙН повертає додаткову регресійну статистику, так що масив, який повертається, матиме вигляд: {mn;mn-1;...;m1;b:sen;sen-1;...;se1;seb:r2;sey:F;df:ssreg;ssresid}.
2 Якщо аргумент статистика має значення ЛОЖЬ або пропускається, то функція ЛІНЕЙН повертає тільки коефіцієнти m і постійну b.
Додаткова регресійна статистика:
| Величина | Опис |
| se1,se2,...,sen | Стандартні значення помилок для коефіцієнтів m1,m2...,mn. |
| seb | Стандартне значення помилки для сталої b (seb = #Н/Д, якщо конст має значення ЛОЖЬ). |
| r2 | Коефіцієнт детермінованості. Порівнюються фактичні значення у і значення, які отримуються з рівняння прямої; за результатами порівняння обчислюється коефіцієнт детермінованості, нормований від 0 до 1. Якщо він рівний 1, то має місце повна кореляція з моделлю, тобто немає відмінності між фактичним і оцінним значеннями у. В протилежному випадку, якщо коефіцієнт детермінованості рівний 0, то рівняння регресії невдале для прогнозу значень у. |
| sey | Стандартна помилка для оцінки у. |
| F | F-статистика, або F-спостерігаєме значення. F-статистика використовується для визначення того, чи є спостережуваний взаємозв’язок між залежною і незалежною змінними випадковим або ні. |
| df | Ступені свободи. Ступені свободи корисні для знаходження F-критичних значень в статистичній таблиці. Для визначення рівня надійності моделі потрібно порівняти значення в таблиці з F-статистикою, яка повертається функцією ЛІНЕЙН. |
| ssreg | Регресійна сума квадратів. |
| ssresid | Залишкова сума квадратів. |

Наведений нижче рисунок демонструє, в якому порядку повертається додаткова регресійна статистика.
До складу Excel входить також комплект засобів аналізу даних (так званий Пакет аналізу), призначений для розв’язку складних статистичних і інженерних задач. Для аналізу даних за допомогою цих інструментів варто вказати вхідні дані й вибрати параметри; аналіз буде виконаний за допомогою відповідної статистичної або інженерної макрофункції, а результат буде розміщено у вихідному діапазоні. Інші засоби дозволяють представити результати аналізу в графічному вигляді.
Засоби, які включені в пакет аналізу даних, описані нижче. Вони доступні через команду Анализ данных меню Сервис. Якщо цієї команди немає в меню, необхідно завантажити надбудову Пакет анализа.
Дисперсійний аналіз. Існує кілька видів дисперсійного аналізу. Необхідний варіант вибирається з урахуванням числа факторів і наявних вибірок з генеральної сукупності.
1 Однофакторний дисперсійний аналіз використовується для перевірки гіпотези про подібність середніх значень двох або більше вибірок, що належать одній генеральній сукупності. Цей метод поширюється також на тести для двох середніх (до яких належить, наприклад, t-критерій).
2 Двофакторний дисперсійний аналіз являє собою більш складний варіант однофакторного аналізу з декількома вибірками для кожної групи даних.
Кореляційний аналіз застосовується для кількісної оцінки взаємозв’язку двох наборів даних, представлених у безрозмірному виді. Коефіцієнт кореляції вибірки представляє відношення коваріації двох наборів даних до добутку їх стандартних відхилень. Для обчислення коефіцієнта кореляції між двома наборами даних на аркуші використовується статистична функція КОРРЕЛ.
Коваріаційний аналіз. Коваріація є мірою зв’язку між двома діапазонами даних. Використовується для обчислення середнього добутку відхилень точок. Обчислення коваріації для окремої пари даних здійснюються за допомогою статистичної функції КОВАР.
Описова статистика. Цей засіб аналізу служить для створення одномірного статистичного звіту, що містить інформацію про центральну тенденцію й змінність вхідних даних.
Експоненційне згладжування застосовується для прогнозування значення на основі прогнозу для попереднього періоду, скоректованого з урахуванням похибок у цьому прогнозі. При аналізі використовується константа згладжування a, по величині якої визначається ступінь впливу на прогнози похибок у попередньому прогнозі.
Двохвибірковій F-Тест застосовується для порівняння дисперсій двох генеральних сукупностей. Наприклад, F-Тест можна використовувати для виявлення розходження в дисперсіях тимчасових характеристик, обчислених по двох вибірках.
Аналіз Фур’є призначається для розв’язку задач у лінійних системах і аналізу періодичних даних на основі методу швидкого перетворення Фур’є (ШПФ). Ця процедура підтримує також зворотні перетворення, при цьому, інвертування перетворених даних повертає вихідні дані.
Гістограма використовується для обчислення вибіркових і інтегральних частот попадання даних у зазначені інтервали значень. При цьому розраховуються числа влучень для заданого діапазону клітинок.
Ковзне середнє використовується для розрахунку значень у прогнозованому періоді на основі середнього значення змінної для зазначеного числа попередніх періодів. Ковзне середнє, на відміну від простого середнього для всієї вибірки, містить відомості про тенденції зміни даних.
Генерація випадкових чисел використовується для заповнення діапазону випадковими числами, витягнутими з одного або декількох розподілів. За допомогою даної процедури можна моделювати об’єкти, що мають випадкову природу, по відомому розподілу ймовірностей.
Ранг і персентиль використовується для виводу таблиці, що містить порядковий і відсотковий ранги для кожного значення в наборі даних. Дана процедура може бути застосована для аналізу відносного взаємного розташування даних у наборі.
Регресія. Лінійний регресійний аналіз полягає в підборі графіка для набору спостережень за допомогою методу найменших квадратів. Регресія використовується для аналізу впливу на окрему залежну змінну значень однієї або більше незалежних змінних.
Вибірка створює вибірку з генеральної сукупності, розглядаючи вхідний діапазон як генеральну сукупність. Якщо передбачається періодичність вхідних даних, то можна створити вибірку, що містить значення тільки з окремої частини циклу.
T-Тест. Цей вид аналізу використовується для перевірки середніх для різних типів генеральних сукупностей.
Двовибірковий z-тест для середніх з відомими дисперсіями. Використовується для перевірки гіпотези про розходження між середніми двох генеральних сукупностей.
Індивідуальні завдання.
Варіанти.
Задача №1
На базі статистичних даних (економічного показника Х за 12 місяців):
1) побудувати графік тренду змінної  , вибрати форму лінійної однофакторної моделі
, вибрати форму лінійної однофакторної моделі
 ;
;
2) оцінити всі її параметри;
3) визначити зони надійності
 ,
, 
параметрів регресії  при рівні значущості
при рівні значущості  ;
;
4) оцінити коефіцієнти детермінації  та кореляції
та кореляції  ;
;
5) оцінити прогноз для таких трьох місяців  :
:
| t | X(t) |
| 5,93+N/10 6,17+N/10 7,15+N/10 6,87+N/10 7,71+N/10 8,20+N/10 7,77+N/10 7,36+N/10 9,45+N/10 9,57+N/10 10,24+N/10 10,70+N/10 |
N – номер варіанту.
Співвідношення, які застосовуються у розв’язанні задач.
Параметри і показники коректності моделі обчислюються за такими формулами:
 , (1)
, (1)
 , (2)
, (2)
 , (3)
, (3)
 , (4)
, (4)
 , (5)
, (5)
 ,
,
 ,
,
де
 – середнє арифметичне значень
– середнє арифметичне значень  ,
,
 – дисперсія значень ,
– дисперсія значень ,
 – середнє арифметичне значень
– середнє арифметичне значень  ,
,
– дисперсія значень ,
 – коваріація значень та ,
– коваріація значень та ,
 – стандартна похибка рівняння,
– стандартна похибка рівняння,

 – відповідно незалежна і залежна змінні.
– відповідно незалежна і залежна змінні.
6) оцінку параметрів обраної моделі зробити за допомогою:
- функції ЛИНЕЙН;
- Пакету аналізу.
Задача №2
Використовуючи просту лінійну регресію, на другому аркуші Excel визначити залежність Y від X, якщо вона задана таблицею.
| X | 6,95+ N/10 | 7,00+ N/10 | 7,05+ N/10 | 7,10+ N/10 | 7,15+ N/10 | 7,20+ N/10 | 7,25+ N/10 | 7,30+ N/10 | 7,35+ N/10 | 7,40+ N/10 |
| Y | 7,12+ N/10 | 7,18+ N/10 | 7,23+ N/10 | 7,29+ N/10 | 7,34+ N/10 | 7,38+ N/10 | 7,40+ N/10 | 7,45+ N/10 | 7,49+ N/10 | 7,45+ N/10 |
Зробити прогноз на наступні два періоди.