LDAP: архитектура, реализации и тенденции
Глобальные сети
1. Основные характеристики ATM (85)ок
2. Эталонная модель ATM (87)ок
3. Уровень адаптации ATM(AAL) (87)ок
4. Технология ретрансляции кадров(FRAMERELAY)(84) - http://www.emanual.ru/download/3615.html http://ru.wikipedia.org/wiki/Frame_Relay ок
5. Прикладной уровень (62, 806) ок
6. Приложение: клиент, срвер(702) ок
7. Службы протоколов канального уровня (296) / 58 - http://www.conlex.kz/sluzhby-kanalnogo-urovnya/
8. Службы протоколов сетевого уровня (496) - http://sharmanka.net/?p=23
9. Службы протоколов транспортного уровня (586) - http://ru.wikipedia.org/wiki/TCP (раздел TCP-порты)
10. Службы протоколов прикладного уровня (659) – http://edu.mmcs.rsu.ru/~ulysses/Edu/cnets-05/lab2.html
11. Всемирная паутина WWW(694) ок
12. Постоянные и непостоянные соединения (в HTTP)(735-оборвано)ок
13. Типы HTTP-сообщений (735) ок
14. Способы распознавания пользователей HTTP- сервером (709) – автор. и cookie ок
15. Протокол передачи файлов FTP (приложение) ок
16. Электронная почта: передача сообщений (674)ок
17. Электронная почта: протоколы доступа к почте (684)ок
18. Службы трансляции имен (658)ок
19. Структура DNS(примеры)(658)ок
20. Типы запросов DNS (примеры) (в приложении) ок
21. DNS –записи (663)ок
22. Распределение ресурсов (приложение)ок
23. Сети распределения ресурсов (приложение, 744)ок
24. Технология ADSL (160)ок
25. Сети SONET/SDH (178)ок
26. Виды мультиплексирования (TDM, FDM и др.)(168)ок
27. Носитель T1/E1 (172)ок
28. Протокол Ipv6(533) ок
29. Стандарты X.25 (84) - http://ru.wikipedia.org/wiki/X.25 ок
30. Категории служб АТМ – (приложение) ок
31. Беспроводные сети IEEE 802.11 (92, 342)ок
32. MPLS (479)ок
33. Качество обслуживания в IP-сетях (459)ок
34. Протокол RSVP (473)ок
35. Протокол RTP (604) ок
36. Интегрированные службы (473)ок
37. Дифференцированные службы (476)ок
38. Службы управления каталогами (приложение) ок
Типы ответов DNS-серверов
Авторитативный ответ (authoritative response ) - такой ответ возвращаютсервера которые являются ответственными за зону.еавторитативный ответ (non authoritative response) - возвращают серверы,которые не отвечают за зону. Необходимую информацию они получают изсвоего кэша или после нерекурсивного запроса к авторитативному DNS-серверу.
Виды запросов к DNS-серверу
Прямой запрос (orward) – это запрос на преобразование имени хоста в IP-адрес. Думаю это самый распространенный запрос.
Обратный запрос (reverse) – это запрос на преобразование IP-адреса хостав доменное имя. Почтовые сервера любят проверять наличие этой записи,что в свою очередь помогает бороться со спамом.
Так о типах запросов. Тип запроса имеет числовое значение от 1 до 16 и определяет тип информации, которую вы желаете получить. В документации всем типам наряду с числовыми присвоены мнемонические значения. Для чего спросите - так я и отвечу: для читабельности документации, а также простоты восприятия и запоминания. Номер типа ответа всегда соответствует номеру типа запроса, чтобы знать, что и к чему относится.
Вот эти типы запросов/ответов (TYPE) :
--------------------------------------------------------
No ............ мнем ... значение
--------------------------------------------------------
01 ............ A ...... host address (IP адрес хоста)
02 ............ NS ..... authoritative name server (NS сервер)
03 ............ MD ..... mail destination (устар.тип, сейчас юзают MX)
04 ............ MF ..... mail forwarder (устар.тип, сейчас юзают MX)
05 ............ CNAME .. the canonical name for alias
06 ............ SOA .... marks of a start of zone of authority
07 ............ MB ..... (experimental)
08 ............ MG ..... (experimental)
09 ............ MR ..... mail rename domain name (experimental)
10 ............ NULL ... a null RR
11 ............ WKS .... a well known service description
12 ............ PTR .... a domain name pointer
13 ............ HINFO .. host information
14 ............ MINFO .. mail box or mail list information
15 ............ MX ..... mail exchange
16 ............ TXT .... text string
числа десятичные, как в документации.
Я пока работал только с типами 'A' и 'NS', чуть позже добавится 'MX', а с остальными буду разбираться по мере их появления. Просто руки еще не дошли.
Тепрерь о классах запросов. Их всего четыре :
01 ............ IN ..... the Internet
02 ............ CS ..... the CSNET
03 ............ CH ..... the CHAOS class
04 ............ HS ..... Hesiod [Dyer 87]
Судя по всему нам так и придется пользоваться только первым по списку классом - Интернет.
Категории служб ATM
Для передачи трафика с различными характеристиками Форум ATM определил следующие категории служб (называемые также классами обслуживания. — Прим. ред.) ATM: постоянная (CBR), переменная (Variable Bit Rate — VBR), доступная (ABR) и неспецифицированная (Unspecified Bit Rate — UBR) скорость передачи битов.
В сетях ATM общего пользования, вероятно, станут применяться только две из этих категорий, а именно: CBR и ABR. Их преимущество состоит в том, что они позволяют выделять для каждого соединения достаточно ресурсов. CBR использует гарантированные ресурсы, а ABR забирает все оставшиеся, что позволяет задействовать оборудование коммутации и передачи данных почти на 100%.
Для разделения ресурсов служба VBR использует механизм статистического мультиплексирования. Но вряд ли такой механизм реально будет применяться в сетях общего пользования.
Служба UBR не представляет интереса для сетей общего пользования, так как вообще не предусматривает установления какого-либо соглашения на передачу трафика. Являясь дешевой службой, которая использует статистические особенности трафика, UBR скорее всего найдет ограниченное применение лишь для передачи данных в корпоративных сетях.
Мы полагаем, что ABR может использоваться для большинства приложений, предназначенных для VBR. А приложения для VBR, чувствительные к временной задержке, видимо, смогут использовать CBR. Для сохранения определенных величин вариации задержек (требование, накладываемое трафиком реального времени) очереди в коммутаторах должны быть небольшими. А чем меньше очередь, тем труднее задействовать преимущества, даваемые неравномерностью трафика.
Стоит отметить, что Форум ATM сейчас трудится над разработкой новой службы, основанной на ABR, которая предназначена для поддержки приложений реального времени.
CBR
CBR — очень простая служба, предназначенная для трафика, требовательного к величинам задержки и ее изменения, т.е. для передачи, в основном, речи и видео. Согласно CBR, исходный узел отправляет ячейки равномерно с согласованной скоростью.
Обычное соединение АТМ для передачи голоса (со скоростью 64 Кбит/с) вносит дополнительную задержку 6 мс по сравнению с узкополосным каналом. Эта дополнительная задержка, вызванная формированием ячейки ATM, равносильна задержке, возникающей при передаче информации по узкополосному каналу на расстояние 1000 км. Поэтому создание "бесшовной" сети ATM весьма важно для речевой связи. Ведь задержка 6 мс еще допустима, однако ее увеличение крайне нежелательно. Если же соединение проходит через несколько сетей АТМ, то дополнительное время, затрачиваемое на формирование ячейки при каждом входе в сеть АТМ, может привести к неприемлемым задержкам.
Отдельно необходимо рассмотреть ситуацию, когда через сеть АТМ передается речевой поток с меньшими скоростями, скажем 8 и 16 Кбит/с. Такие скорости используются в радиосетях, например в сетях персональной связи (Personal Communication Networks). В подобных случаях время компоновки ячейки АТМ может быть слишком большим (48 мс для скорости 8 Кбит/с). Один из способов решения данной проблемы состоит в использовании ячеек меньшего размера (микроячеек), переносимых в обычной ячейке АТМ.
ABR
Служба ABR только недавно определена Сектором ITU-T и Форумом ATM. Это — несомненно наиболее важная служба, в полной мере использующая гибкость полосы пропускания сетей ATM и действительно эксплуатирующая эту полосу на все 100%. ABR может применяться для множества приложений. В принципе все приложения, связанные с передачей данных, в частности передача данных по протоколу IP и не требующая установления соединений служба SMDS, могут успешно воспользоваться ABR.
Цель ABR состоит в предоставлении гибкой и эффективной службы для приложений, ориентированных на передачу данных. С одной стороны, ABR обеспечивает эффективность ЛВС, а с другой — гарантирует выделение в любой момент времени каждому узлу определенной полосы пропускания. При перегрузке некоторого сетевого узла сеть сообщает источникам трафика о необходимости снижения скорости передачи. После устранения перегрузки эти скорости снова могут быть увеличены.
Служба ABR не контролирует величину вариации задержек ячеек (Cell Delay Variation — CDV) и, следовательно, она не ориентирована на работу с приложениями реального времени. При установлении ABR-соединения пользователь должен задать максимальную (Peak Cell Rate — PCR) и минимальную (Minimum Cell Rate — MCR) скорости передачи ячеек по сети. После чего сеть гарантирует выделение полосы пропускания не меньше MCR, а исходный узел обязуется посылать ячейки со скоростью, не превышающей PCR.
Между CBR и ABR есть существенное различие. Для CBR-соединения сеть все время должна поддерживать ресурсы, выделенные при его установлении. В случае ABR-соединения сеть может динамически изменять полосу пропускания, выделенную соединению, и тем самым адаптироваться к возникающей перегрузке. Таким образом ресурсы сети будут использоваться более эффективно. Механизм управления потоком ABR основан на ячейках управления ресурсами (RM-ячейках), передаваемых в потоке обычных пользовательских ячеек через равные интервалы времени.
22,23
Интернет-провайдеры арендуют и устанавливают кэш-серверы, чтобы повысить качество обслуживания своих пользователей. Как было показано в подразделе «Web-кэширование» данного раздела, применение кэш-серверов способно значительно сократить время доставки наиболее востребованных ресурсов пользователям.
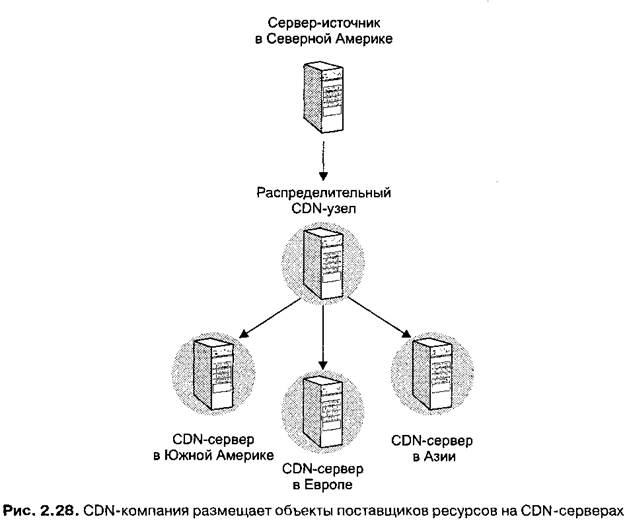
В конце 1990-х годов широкое распространение получила еще одна технология распределения ресурсов — технология CDN (Content Distribution Network — сети распределения ресурсов). В CDN используется иная «бизнес-модель», нежели в web-кэшировании. Если при web-кэшировании потребителями услуг являются Интернет-провайдеры, то в сетях распределения ресурсов на их месте находятся поставщики ресурсов. Тем не менее сети распределения ресурсов преследуют ту же цель — сократить время доставки ресурсов. Обычно CDN-компания функционирует по следующему плану.
1. Компания устанавливает множество (порядка сотен) CDN-серверов, распределенных в Интернете. Как правило, CDN-серверы располагаются в центрах Интернет-хостинга, принадлежащих сторонним компаниям (наподобие Exodus и Worldcom) и представляющих собой здания с большим числом хостов внутри. Обычно центры Интернет-хостинга подключены к Интернет-провайдерам нижнего звена и расположены вблизи их сетей доступа.
2. Компания копирует ресурсы своих потребителей на CDN-серверы. Когда потребитель обновляет свои ресурсы, CDN-компания заменяет старое содержимое серверов новым.
3. Компания обеспечивает такое обслуживание, при котором CDN-сервер осуществляет обработку запроса за минимальное время. Для этого выбирается либо такой CDN-сервер, который территориально наиболее близок к пользователю, либо такой, на пути к которому нет перегруженных узлов.
Любопытно отметить, что в создание CDN вовлекаются сразу несколько независимых компаний. Поставщик ресурсов (например, Yahoo!) использует услуги CDN-компании (например, Akamai). В свою очередь, CDN-компания покупает CDN-серверы у их производителей (Inktomi, IBM и др.) и устанавливает эти серверы в центрах Интернет-хостинга, принадлежащих компаниям, предоставляющим услуги Интернет-хостинга (например, Exodus). Таким образом, в создании CDN участвуют как минимум четыре компании, не считая Интернет-провайдеров!
На рис. 2.28 представлена схема взаимодействия между поставщиком ресурсов и CDN-компанией. Сначала поставщик ресурсов определяет объекты, которые он хотел бы сделать распределенными с помощью CDN (остальные объекты могут распространяться без участия CDN). Нужные объекты отсылаются узлу распределения CDN, который, в свою очередь, доставляет их на все CDN-серверы. Специально для этой цели CDN-компании иногда приобретают частные компьютерные сети. В случае, если поставщик ресурсов желает произвести обновление своих объектов, он отсылает их последние версии узлу распределения, откуда они попадают на все CDN-серверы, заменяя устаревшие объекты. Обратите внимание на то, что каждый CDN-сервер содержит объекты, принадлежащие множеству поставщиков ресурсов.
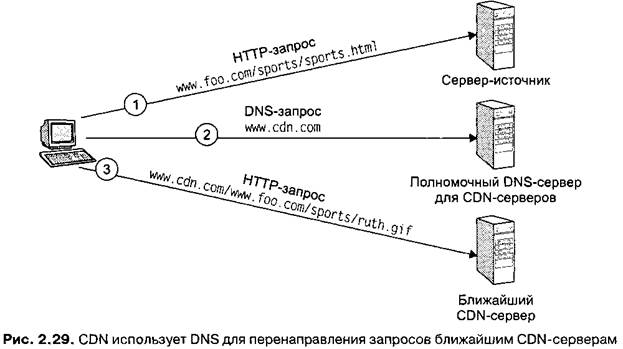
При знакомстве с технологией CDN возникает интересный вопрос. Когда браузер на хосте пользователя формирует запрос на получение объекта (идентифицируемого своим URL-адресом), каким образом браузер определяет, кому отправить этот запрос — серверу-источнику или одному из CDN-серверов? Для решения этого вопроса в CDN используется механизм DNS-перенаправления, указывающий браузерам адрес нужного сервера. Заинтересовавшемуся читателю рекомендуем обратиться к дополнительным источникам информации [256].
Рассмотрим следующий пример. Пусть поставщик ресурсов имеет имя хоста www.foo.com, а CDN-компания — cdn.com. Предположим, что поставщик ресурсов желает распределить свои GIF-файлы при помощи CDN, при этом все остальные файлы, включая базовые HTML-страницы, будут распространяться им (поставщиком) самостоятельно. Для этого поставщик изменяет все свои объекты таким образом, что ссылки на GIF-файлы предваряются фрагментом http://www.cdn.com. Например, ссылка http://www.foo.com/sports/ruth.gif после изменения приобретает вид http://www.cdn.com/www.foo.com/sports/ruth.gif. Когда браузер формирует запрос объекта ruth.gif, происходит следующее.
1. Браузер передает запрос на получение базового HTML-объекта серверу-источнику www.foo.com, который выполняет запрос и отсылает браузеру требуемый файл. Браузер производит обработку HTML-страницы и находит в ней ссылку на объект http://www.cdn.com/www.foo.com/sports/ruth.gif.
2. Браузер осуществляет DNS-поиск хоста www.cdn.com, при этом запрос передается от корневого сервера имен полномочному серверу имен хоста www.cdn.com. Последний извлекает IP-адрес хоста, сделавшего запрос, и на основе специальной внутренней карты Интернета возвращает IP-адрес CDN-сервера, который более других подходит для обслуживания запроса.
3. Ответ с IP-адресом CDN-сервера возвращается браузеру, который перенаправляет свой запрос с использованием полученного IP-адреса. Далее запрос обрабатывается и обслуживается CDN-сервером. Любой последующий запрос, адресованный хосту www.cdn.com, будет автоматически обслуживаться этим же CDN-сервером, поскольку IP-адрес www.cdn.com окажется в DNS-кэше либо на стороне клиента, либо на стороне локального сервера имен.
На рис. 2.29 приведена иллюстрация этапов выполнения запроса на получение документа с помощью CDN. Сначала браузер получает базовый HTML-файл с сервера-источника, затем обращается к полномочному серверу имен, который определяет IP-адрес «наилучшего» CDN-сервера, и, наконец, запрашивает распределенные объекты у CDN-сервера. Обратите внимание на то, что приведенная схема не требует внесения изменений в протоколы HTTP и DNS или применения каких-либо дополнительных средств.
Пожалуй, единственным оставшимся вопросом, который следует рассмотреть детально, является методика определения «наилучшего» CDN-сервера для хоста, формирующего запрос. Несмотря на то что каждая CDN-компания располагает собственным алгоритмом решения этой задачи, нетрудно выделить общую идею подобных решений. Каждому Интернет-провайдеру нижнего звена (то есть группе оконечных пользователей, подключенных к сети такого провайдера) компанией ставится в соответствие CDN-сервер, который определяется на основе анализа таблиц маршрутизации (точнее, BGP-таблиц, рассматриваемых в главе 4), времени кругового оборота и прочих данных о передаче между различными сетями доступа. Подробности вы можете найти в [535]. Оценив приближенные значения времени ответа для каждой сети доступа, можно выбрать сеть с минимальным временем. Этой сети и назначается определенный CDN-сервер, а соответствующая информация заносится в полномочный DNS-сервер.
Хотя наше рассмотрение CDN лежит в контексте web-ресурсов, сети CDN весьма активно используются, например, для передачи потоковых аудио- и видеоресурсов. Для этого применяются специальные протоколы (RTSP и др.), поддерживаемые большинством CDN-серверов.
38.
Служба каталогов в контексте компьютерных сетей — программный комплекс, позволяющий администратору работать с упорядоченным по ряду признаков массивом информации о сетевых ресурсах (общие папки, серверы печати, принтеры, пользователи и т. д.), хранящимся в едином месте, что обеспечивает централизованное управление как самими ресурсами, так и информацией о них, а также позволяющий контролировать использование их третьими лицами.
LDAP: архитектура, реализации и тенденции
Сервисы каталогов облегчают доступ к информации в разных средах и приложениях. Облегченная версия протокола доступа к каталогам LDAP с помощью структур данных, подобных структурам протокола X.500, обеспечивает доступ к хранимой в каталогах информации.
Сервисы каталогов облегчают доступ к информации в разных средах и приложениях. Облегченная версия протокола доступа к каталогам LDAP (Lightweight Directory Access Protocol) с помощью структур данных, подобных структурам протокола X.500, обеспечивает доступ к хранимой в каталогах информации.
 Решения на базе LDAP поставляются компаниями IBM Tivoli, Novell, Sun Microsystems, Oracle, Microsoft и др. Растущая популярность этой технологии объясняется как ее гибкостью, так и совместимостью с существующими приложениями.
Решения на базе LDAP поставляются компаниями IBM Tivoli, Novell, Sun Microsystems, Oracle, Microsoft и др. Растущая популярность этой технологии объясняется как ее гибкостью, так и совместимостью с существующими приложениями.
Сервис каталогов — это оснащенный средствами поиска репозитарий, в котором наделенные соответствующими полномочиями пользователи и службы могут находить информацию о людях, компьютерах, сетевых устройствах и приложениях. Потребность в получении информации, особенно по каналам Internet, постоянно растет, поэтому в последнее десятилетие сервисы каталогов получили широкое распространение и многие распределенные приложения имеют такие службы.
Облегченный протокол доступа к каталогам [1] представляет собой открытый промышленный стандарт, получающий все более широкое распространение как метод доступа к каталогам. Как явствует из его названия, LDAP является облегченной версией протокола доступа к каталогам Directory Access Protocol и прямым потомком «тяжеловеса» X.500, наиболее известного протокола управления каталогами. В LDAP и в X.500 применяются сходные структуры представления данных, но эти протоколы имеют ряд фундаментальных различий [2].
· LDAP использует стек протоколов TCP/IP, тогда как X.500 — стек OSI.
· Правила кодировки элементов протокола LDAP не столь сложны, как у протокола X.500.
· Серверы LDAP реализуют ссылочный механизм (referral mechanism). Если такой сервер не в состоянии предоставить запрашиваемую клиентом информацию, он предоставляет ему URL альтернативного сервера LDAP, содержащего искомые данные. Сервер X.500 действует иначе: он разыскивает отсутствующие данные собственными средствами и предоставляет их клиенту без ссылки на сервер, на котором были взяты эти данные.
Многие поставщики программных средств обеспечивают их совместимость с LDAP, поскольку этот протокол отличается гибкостью и интегрируется со все большим числом программ извлечения данных и управления ими.
Технология LDAP
На рынке имеется множество серверов на базе LDAP — от общедоступных серверов гигантского масштаба, таких как BigFoot и Infospace, до небольших LDAP-серверов, предназначенных для рабочих групп. Промежуточное положение занимают серверы каталогов, установленные и особым образом сконфигурированные во многих университетах и на предприятиях. Их назначение — предоставлять информацию о профессорско-преподавательском составе, служащих и студентах в формате, совместимом с почтовым сервисом данной организации, с системой аутентификации и методами управления доступом к приложениям и ресурсам.
Список общедоступных интерфейсов каталогов имеется в общеевропейской исследовательской сети DANTE (Delivery of Advanced Network Technology to Europe). В таблице 1 представлены наиболее известные из Web-сервисов, использующих LDAP, и перечислены функциональные возможности, полученные при интеграции LDAP с существующими приложениями обработки данных (электронная почта, передача файлов, видеоконференции и т.д.). В почтовой службе, к примеру, типичная LDAP-запись может содержать такие атрибуты, как mailLocalAddress, mailHost, UserCertificate (содержит сертификат пользователя в двоичном формате), ipLoginPort и ipLoginHost (для тех случаев, когда пользователь устанавливает соединение по коммутируемым линиям).
Таблица 1. Наиболее известные Web-сервисы, использующие LDAP

Архитектура LDAP
Функционирование LDAP основывается на модели клиент-сервер. С помощью протокола LDAP, который выполняется поверх стека TCP/IP, клиенты LDAP извлекают данные из базы данных сервера каталога. Клиенты LDAP либо напрямую контролируются сервером с установленными на нем средствами LDAP, либо управляются LDAP-совместимыми приложениями. На рис. 1 представлены основные элементы архитектуры LDAP.

|
| Рис. 1. Инфраструктура LDAP. Устройства и серверы с помощью протокола LDAP обращаются к данным, хранимым в базе данных LDAP-серверов |
Важнейшую роль в архитектуре LDAP играют два компонента. Это LDAP-совместимая база данных, или каталог, и формат представления данных, основывающийся на языке XML.
Каталог LDAP
LDAP-каталоги — это базы данных, структурированные по принципу иерархических информационных деревьев, которые описывают представляемые ими организации. На рис. 2 приведен пример иерархической структуры, состоящей из трех уровней. Каждая запись LDAP идентифицируется с помощью отличительного имени (distinguished name, DN), которое декларирует свою позицию в иерархии. Структура данной иерархии представляет собой информационное дерево каталога (directory information tree, DIT), которое «вырастает» из корня (RootDN).

|
| Рис 2. Пример иерархической структуры стандарта LDAP. Каждая запись LDAP идентифицируется отличительным именем, которое свидетельствует о позиции данной записи в иерархии |
В базовой системе обозначений LDAP символы dc обозначают компонент домена (domain component), символы ou — организационную единицу (organizational unit), а символы uid — идентификатор пользователя (user id). Так, корень RootDN, описывающего некую базирующуюся в Греции организацию информационного дерева каталога с данными о пользователях, выглядел бы как dc=organization-name, dc=gr, а отличительное имя DN записи уполномоченного пользователя формулировалось бы так: uid=avakali, ou=people, dc=organization-name, dc=gr.
Представление данных и их структура. В реляционных СУБД структуру данных определяют пользователи; в каталогах LDAP фиксированная базовая схема управляет иерархией каталога. Кроме того, если объекты LDAP вложены в иерархические структуры, то объекты реляционных баз данных связаны друг с другом посредством первичного и внешнего ключей, соединяющих элементы данных. Наконец, типы данных LDAP отличаются гибкостью и расширяемостью.
Организация запросов и транзакций. В реляционных СУБД процессор запросов чувствителен к отношениям между объектами базы данных, тогда как в каталогах LDAP соответствующие отношения отбрасываются в процессе обработки запроса. Кроме того, запросы LDAP могут различаться по тому уровню на дереве, с которого начинается поиск (запрос-ответ). К примеру, мы можем иметь запросы двух типов:
Запрос 1:
ldapsearch -h localhost -b
«dc=organization-name, dc=gr»
«uid=avakali»
Запрос 2:
ldapsearch -h localhost -b
«ou=people, dc=organization-name, dc=gr»
«businesscategory=Assistant Professor»
Параметр -h определяет выполняющую поиск главную машину, а параметр -b указывает на уровень иерархии, на котором будет начинаться поиск. Таким образом, первый запрос указывает на запись пользователя с идентификатором uid=avakali (поиск начнется с узла, имеющего отличительное имя «dc=organization-name, dc=gr»), а второй — на все записи с атрибутом «businesscategory=AssistantProfessor» (поиск начнется с узла с именем «ou=people, dc=organization-name, dc=gr»).
Операционные выгоды и затраты. В реляционных базах данных важнейшее значение имеет быстродействие при записи транзакций и считывании, тогда как каталоги LDAP используются в основном для считывания данных. Кроме того:
· серверы LDAP, как правило, просты в установке и в обслуживании;
· каталоги LDAP могут быть весьма распределенными, а реляционные базы данных, как правило, отличаются высокой степенью централизации;
· серверы LDAP могут тиражировать некоторые или все хранимые на них данные с помощью встроенных и легко конфигурируемых средств репликации. Многие поставщики СУРБД считают такие средства «дополнительными» и соответственно берут за них дополнительную плату. Наконец, если реляционные базы данных исправно отображают сложные взаимоотношения объектов, то в каталогах LDAP трудно отобразить какие-либо отношения между объектами, помимо иерархических.