Предмашинная подготовка задачи
Порядок выполнения работы
1. Ознакомиться с методическими указаниями.
2. Ответить на контрольные вопросы.
3. Получить у преподавателя постановку задачи (задач).
4. Выполнить полную предмашинную подготовку задачи (задач).
5. Осуществить машинную обработку полученной программы (программ).
6. Проанализировать полученные результаты.
7. Оформить техническую документацию (отчёт).
8. Защитить работу.
Предмашинная подготовка задачи
Линейным называется вычислительный процесс последовательного однократного без проверки условий выполнения запланированных этапов вычислений.
Постановка задачи
Найти массу и стоимость ленты каучука, выходящей из сушилки за смену. Продолжительность смены 8 ч, ширина ленты 2 м, толщина 2 мм, скорость движений ленты 15м/мин, плотность ленты и цена 1 кг известны.
Математическая формулировка
Исходные данные:
(основные)
ЛШ = 2 м – ширина ленты
ЛТ = 2 мм – толщина ленты
ЛПЛ= =_, _ _ г/см3 – плотность ленты
ЛС = 15 м/мин – скорость ленты
ЛЦ =_ _ руб/кг – цена 1 кг ленты
ПС = 8 ч/смн – продолжительность смены
(вспомогательные)
К1 = 1000 мм/м – коэффициент перевода м в мм
К2 = 1000 г/кг – коэффициент перевода кг в г
К3 = 106 см3 / м3 – коэффициент перевода м3 в см3
К4 = 60 мин/ч – коэффициент перевода ч в мин
Расчётные зависимости
ЛП = ЛШ×ЛТ/К1 [м2=м×мм×м/мм] – площадь сечения
ленты
ЛО = ЛП×ЛС×К4 [м3/ч=м2×м/мин×мин/ч] – объём в ч
МЧ =ЛПЛ×ЛО/К2×К3 [кг/ч= г/см3×м3/ч/(г/кг) × см3 /м3]
– масса в ч
МС =МЧ×ПС [кг/смн= кг/ч × ч/смн ] – масса за смену
СС =МС× ЛЦ [руб/смн=кг/смн×руб/кг] – стоимость за смену
Выбор метода решения
Анализ математической формулировки задачи позволяет сделать вывод, что решение сводится к последовательному выполнению математических зависимостей, каждая из которых содержит только арифметические операции. Следовательно в качестве метода решения используем линейный вычислительный процесс.
Составление алгоритма решения

Создание исходного модуля программы
Исходный модуль – программа пользователя на алгоритмическом языке, введенная в ЭВМ и оформленная в виде файла на диске.
Исходный модуль формируется пользователем вводом текста программы, созданного ранее, в память ЭВМ с помощью любого редактора текста.
Основы языка С++
Язык программирования С++ разработан в начале 80-х годов сотрудником фирмы AT&T Bell Laboratories Бьярном Страуструпом. Название С++ отражает факт происхождения этого языка от языка С, который был разработан в 1972 году сотрудником этой же фирмы Денисом Ритчи для решения задач системного программирования.
Популярность языка С++ обусловлена двумя причинами. Во-первых, это современный, эффективный, гибкий язык, который можно использовать для программирования прикладных задач.
Во-вторых, он используется для создания системного программного обеспечения ЭВМ.
Популярность С++ уже привела к тому, что язык Java, разработанный для программирования в Интернет, основан на С++.
Лежащая в основе языков программирования С и С++ философия мобильности и расширяемости языка со временем привела к появлению большого числа новых библиотечных функций, которые, в свою очередь, привели к потере мобильности. Кроме того, отдельные разработчики компиляторов расширили язык и добавили в свои продукты новые средства, которые не поддерживаются другими компиляторами.
Для решения этой проблемы в 1983 году в Американском Национальном институте стандартизации (ANSI) был создан комитет по разработке стандарта языка программирования С. В 1989 году проект разработанного стандарта языка был принят комитетом ANSI, а вскоре после этого и Международной организацией стандартов (ISO). Для С++ предложен отдельный проект стандарта ANSI (сентябрь 1995).
В методических указаниях дано описание языка программирования С++ на основе стандарта International Standard for Information Systems – Programming Language C++ (ISO/IEC JTC1/SC22/WG21) []. Этому стандарту соответствует большинство новейших компиляторов С++, поставляемых различными компаниями.
2.1. Алфавит
Алфавит языка С++ составляют 52 (заглавные и прописные) букв латинского алфавита:
A B C D E F G H I J K L M N O P Q R S T U V W Z Y Z
a b c d e f g h i j k l m n o p q r s t u v w z y z
10 арабских цифр:
0 1 2 3 4 5 6 7 8 9
30 знаков и символов:
| + | плюс; | пробел; | |
| - | минус; | ( | левая круглая скобка; |
| * | звездочка; | ) | правая круглая скобка; |
| / | косая черта; | [ | левая квадратная скобка; |
| \ | обратная косая черта; | ] | правая квадратная скобка; |
| < | Меньше; | { | левая фигурная скобка; |
| > | больше; | } | правая фигурная скобка; |
| = | равно; | ? | знак вопроса; |
| . | точка; | ! | восклицательный знак; |
| , | запятая; | | | вертикальная черта; |
| ; | точка с запятой; | ~ | волнистая черта; |
| : | двоеточие; | ^ | угол вверх; |
| ' | апостроф; | # | фунт, решетка; |
| " | Кавычки; | & | амперсант; |
| _ | подчеркивание; | % | процент. |
2.2. Простейшие конструкции
Простейшие конструкции соответствуют слогам и словам разговорного языка.
В качестве простейших конструкций используются:
- ключевые слова;
- переменные;
- константы;
- вызовы функций.
2.2.1. Ключевые слова
Ключевые слова – это зарезервированные языком С/С++ последовательности символов, имеющие специальное назначение.
Основные ключевые слова языка С++ приведены в табл.1
Таблица 1
| Обозначение | Назначение | Обозначение | Назначение |
| auto | автоматический | long | длинный |
| bool | логический | new | создать |
| break | разорвать, выйти | operator | оператор |
| case | вариант | overload | оверлейный |
| char | символьный | private | личный |
| class | класс | protected | защищённый |
| const | константа | public | общий |
| continue | продолжить | register | регистровый |
| default | По умолчанию | return | вернуться |
| delete | удалить | short | короткий |
| do | выполнять | signed | знаковый |
| double | вещественный двойной точности | sizeof | определить размер |
| else | иначе | static | статический |
| enum | перечисление | struct | структура |
| extern | внешний | switch | переключатель |
| float | вещественный обычной точности | this | это |
| for | для | typedef | определить тип |
| friend | дружественный | union | смесь |
| goto | перейти к | virtual | виртуальный |
| if | если | volatile | используется для модификации переменной переферийным устройством |
| inline | встраиваемый | void | пустой |
| int | целый | while | пока |
2.2.2. Переменные
Переменная – обозначенная именем величина, способная изменять своё значение в процессе выполнения программы. Переменная обладает именем, размером и рядом других атрибутов (таких, как область действия, область видимости, время жизни).
Под областью действия переменной понимают область программы, в которой переменная доступна для использования. С этим понятием тесно связано понятие области видимости переменной. Если переменная выходит из области действия, она становится невидимой. С другой стороны, переменная может находиться в области действия, но быть невидимой. Переменная находится в области видимости, если к ней можно получить доступ (с помощью операции разрешения видимости, если она непосредственно не видима).
Временем жизни переменной называется интервал выполнения программы, в течение которого она существует.
При объявлении переменной для неё резервируется некоторая область памяти, размер которой зависит от конкретного типа переменной. Здесь следует также учитывать, что размер одного и того же типа данных может отличаться на компьютерах разных платформ, а также может зависеть от используемой операционной системы. Поэтому при объявлении той или иной переменной нужно чётко представлять, сколько байт она будет занимать в памяти ЭВМ, чтобы избежать проблем, связанных с переполнением и неправильной интерпретации данных.
В табл. 2 приведён перечень базовых типов переменных в С/С++,их размер и диапазоны значений.
Таблица 2
| № п/п | Тип переменной | Объём памяти | Диапазоны представления чисел | ||
| бит | байт | min | max | ||
| Bool | false (0) | true (1) | |||
| signed char (сокращённо char) | -128 | ||||
| unsigned char | |||||
| int[1] | -32768 | ||||
| unsigned int (unsigned) | |||||
| short int (short) | -32768 | ||||
| unsigned short int (unsigned short) | |||||
| long int (long) | -2147483648 | ||||
| unsigned long int (unsigned long) | |||||
| Float | 3,4 Е-38 | 3,4 Е+38 | |||
| Double | 1,7 Е-308 | 1,7 Е+308 | |||
| long double | 3,4 Е-4932 | 3,4 Е+4932 | |||
| Указатель | |||||
| void[2] | отсутствие значения |
Каждая переменная должна быть перед первым использованием обязательно однократно описана. Описание (объявление) переменной осуществляется с помощью оператора описания.
Оператор описания в общем случае имеет следующую структуру:
описатель u1[=c1] [,u2[=c2] , … , uN[=cN] ];
Описатель определяет такие атрибуты, как область видимости, время жизни, тип переменной и имеет следующий вид:
[спецификатор класса памяти] спецификатор типа
Здесь [ ] – признак необязательности содержимого;
спецификатор класса памяти – ключевое слово, определяющее класс памяти переменной;
спецификатор типа – ключевое слово, определяющее тип переменной;
u1 … uN – идентификаторы переменных;
, – разделитель идентификторов;
с1 … сN – значения, которые присваиваются переменным
в случае их инициализации;
= – знак операции присваивания;
; – символ окончания оператора.
Один описатель позволяет объявить несколько переменных. При этом они следуют друг за другом через запятую (,). Заканчивается объявление символом точка с запятой (;).
Имя переменной (идентификатор) не должно превышать 256 символов, из которых значимыми являются только первые восемь символов[3] (остальные компилятором игнорируются).
В программе идентификатор может содержать прописные и строчные латинские буквы, цифры и символ подчёркивания и обязательно начинается с буквы или символа подчёркивания и не должен совпадать с ключевым словом . При этом важно учитывать регистр букв ( Abc и abc – не одно и то же)! Имя должно быть достаточно информативным, однако не следует использовать слишком длинные имена, так как это приводит к опискам.
Инициализация – присваивание объекту начального значения в момент его описания.
Хотя изначальная инициализация и не является обязательной при объявлении переменной, всё же рекомендуется инициализировать переменные начальным значением. Если этого не сделать, переменная изначально может принять непредсказуемое значение.
Установка начального значения переменной осуществляется с помощью операции присваивания (=).
Спецификаторы класса памяти рассмотрим несколько позже, а здесь рассмотрим подробно основные типы переменных.
Переменная типа bool занимает всего 1 байт и используется, прежде всего, в логических операциях, так как может принимать значение 0 (false, ложь) или отличное от нуля (true, истина). В старых текстах программ на языке С вы можете встретить тип данных BOOL и переменные этого типа, принимающие значения TRUE и FALSE. Этот тип данных и указанные значения не являлись частью языка С, а объявлялись в заголовочных файлах как unsigned short, 1 и 0, соответственно. В новой редакции С++ bool – самостоятельный тип данных.
Часто бывает необходимо указать в программе, что переменная должна принимать только целые значения. Целочисленные переменные (типа int, long, short), как следует из названия, призваны хранить целые значения, и могут быть знаковыми и беззнаковыми. Знаковые переменные могут представлять как положительные, так и отрицательные числа. Для этого в их представлении один бит (самый старший) отводится под знак. В отличие от них, беззнаковые переменные принимают только положительные значения. Чтобы указать, что переменная будет беззнаковой, используется ключевое слово unsigned. По умолчанию целочисленные переменные считаются знаковыми (ключевое signed, чаще всего опускается, и используется, как правило, при преобразовании типов данных).
Символьный тип данных char применяется, когда переменная должна нести информацию в коде ANCII. Этот тип данных часто используется при построении более сложных конструкций, таких, как строки, символьные массивы и т. д. Данные типа char также могут быть знаковыми и беззнаковыми.
Для представления чисел с плавающей запятой применяют тип данных float. Этот тип, как правило, используется для хранения не очень больших дробных чисел и занимает в памяти 4 байта: 1 бит – знак, 8 бит – экспонента, 23 бита – мантисса. Таким образом, вещественные обычной точности могут иметь 7-8 значащих чисел мантиссы.
Если вещественное число может принимать очень большие значения, используют переменные двойной точности, тип double или (в случае, когда двойной точности не достаточно) – используется тип повышенной точности – long double. Тип double занимает в памяти 8 байт: 1 бит – знак, полтора байта – экспонента, оставшиеся – мантисса). Вещественные двойной точности могут иметь 16-17 значащих чисел мантиссы, повышенной точности – до 20 значащих чисел.Указатель (pointer) представляет собой переменную, значение которой является адресом ячейки памяти.Переменная типа void не имеет значения и служит для согласования синтаксиса. Например, синтаксис требует, чтобы функция возвращала значение. Если не требуется использовать возвращённое значение, перед именем функции ставится тип void.Примеры операторов описания int A2, igr; double s, s1; float summa; long int sh; short int n, N; unsigned short it, i, j, k; При использовании типов long int, short int (см. табл. 2) ключевое слово int может не указываться. Например: long sh; short n, N;Допускается в одном операторе описания объявлять несколько переменных одного типа: int ss, sr, sob1; При описании переменные могут определяться (инициализироваться), т. е. получать значения констант.Например:char per='\n';int pc=265, i=0;float x, y, z=15.e-3;ВНИМАНИЕ! В расчётах могут использоваться только описанные и проинициализированные переменные!2.2.3. Константы
Константа – величина, значение которой определено и не меняется в процессе выполнения программ. Константы бывают литеральными и типизованными, причём литеральные константы делятся на: символьные, строковые, целые и вещественные.
Символьные константы представляются отдельным символом, заключённым в одинарные кавычки (апострофы): 'e', '@', '>'.
Значением символьной константы является её числовой восьмеричный код. Этот код с предшествующим знаком "обратная косая черта" допускается применять вместо символа. Это удобно, если используются символы, не выводимые на печать. Например, звуковому сигналу соответствует код 007. При записи восьмеричного кода левые незначащие нули можно не указывать. Так, символьные константы
'\007', '\07', '\7'
являются идентичными. Символьные константы хранятся однобайтовых ячейках.
Строковые константы – это последовательность символов, заключённая в двойные кавычки:
"Это пример строковой константы! ".
Кавычки не являются частью строки, а отмечают её начало и конец. Если в состав символьной строки входят символы ", ', \, то они записываются в виде \", \', \\.
Так предложение:
Запомните, " символ \ называется обратная косая черта",
будет иметь вид:
"Запомните, \" символ \\ называется обратная косая черта\"".
Строка символов хранится в последовательности соседних ячеек (байтов), число которых соответствует количеству хранимых символов плюс символ конца строки '\0'. Нуль-символ '\0' не выводится на печать, но автоматически добавляется в конец строки оператором ввода. Например, текстовые константы 'T' и "T" по виду (не считая ограничителей) совершенно одинаковы, но в первом случае это символьная константа, для хранения которой нужен один байт, а во втором – это символьная строка, состоящая из символа Т и знака окончания символьной строки \0. Для хранения этой строки потребуется два байта.
Целые константы – совокупность цифр со знаком +(-) или без него. Целые константы бывают следующих форматов:
- десятичные;
- восьмеричные;
- шестнадцатиричные.
Десятичные могут быть представлены, как последовательность цифр, начинающихся не с нуля, например: 123; 2384.
Восьмеричные константы – последовательность восьмеричных цифр (от 0 до 7), начинающаяся с нуля, например: 034; 047.
Шестнадцатеричный формат констант начинается с символов 0х или 0Х и включает цифры от 0 до 9 и буквы латинского алфавита А, В, С, D, E, F, (a, b, c, d, e, f), которые обозначают цифры от 10 до 15 соответственно. Например: 0Х12, -0х1А7, 0хFF, 0xfa62.
Константы целого типа хранятся в ячейках размером в одно слово. Двухбайтовые слова ПЭВМ позволяют рассчитать диапазоны изменения целых констант. Для десятичных знаковых констант он изменяется от -32768 до +32767, для беззнаковых – от 0 до 65535.
При необходимости увеличения диапазона используются длинные константы (размером в два слова). Отличительный признак длинной константы – буква L (l) в конце. Например:
1000242L 047777777l +12345678L -0XA761263l
Константа с плавающей точкой (вещественная константа) – десятичное число со структурой
[m].[n][Ep] ([m].[n][ep]),
где m – целая часть мантиссы (десятичные цифры со знаком или без него;
n – дробная часть мантиссы (десятичные цифры без знака);
p – показатель степени (целая константа);
E (е) – символ системы счисления (десятичной);
[ ] – символ необязательности содержимого.
Наличие одной из составляющих мантиссы обязательно. Например: 3.14159 -255. .79 -1.56Е12 2.87е-3 10.Е6 .3е12 6Е-2
Использовать пробелы при записи константы запрещается.
Константы с плавающей точкой хранятся в двухсловных ячейках. Первый байт отводится под показатель степени, остальные три – для записи мантиссы. Это позволяет представлять константу с плавающей точкой в диапазоне от 10±38 с точностью до 6-7 значащих цифр. При необходимости большей точности используются ячейки удвоенной длины (восьми байтовые). По умолчанию вещественные константы имеют двойную точность. При необходимости использования обычной точности, в конце константы ставится символ F (f).
Типизованные константы используются как переменные, значение которых не может быть изменено после инициализации.
Типизованная константа объявляется с помощью ключевого слова const, за которым следует указание типа константы, но, в отличие от переменных, константы всегда должны быть инициализированы.
Символьные константы в С++ занимают в памяти 1 байт и, следовательно, могут принимать значения от 0 до 255 (см. табл. 3). При этом существует ряд символов, которые не отображаются при печати, – они выполняют специальные действия: возврат каретки, табуляция, называются символами escape-последовательности. Термин «escape-последовательности» ввела компания Epson, ставшая первой фирмой, которая для управления выводом информации на своих принтерах стала использовать неотображаемые символы. Исторически сложилось так, что управляющие последовательности начинались с кода с десятичным значением 27 (0х1В), что соответствовало символу "Escape" кодировки ASCII.
Escape-символы в программе изображаются в виде обратного слеша, за которым следует буква или символ.
Таблица 3
| Обозначение | Назначение |
| \\ | Вывод на печать обратной черты |
| \' | Вывод апострофа |
| \" | Вывод при печати кавычки |
| \? | Символ вопросительного знака |
| \a | Подача звукового сигнала |
| \b | Возврат курсора на 1 символ назад |
| \f | Перевод страницы |
| \n | Перевод строки |
| \r | Возврат курсора на начало текущей строки |
| \t | Перевод курсора к следующей позиции табуляции |
| \v | Вертикальная табуляция (вниз) |
Пример использования типизированных и литеральных констант:
const double Pi=3.1415;
Здесь в правой части операции присваивания указана литеральная вещественная константа 3.1415. Учитывая, что процесс решения задачи может потребовать многократного использования этой константы, её удобно задать в виде типизированной (именованной) константы Pi.
2.2.4. Вызов функций
Функция – универсальная конструкция языка, предназначенная для организации совокупности вычислений (действий), планируемых пользователем. Функцию можно представить как некоторую процедуру, несущую законченную смысловую нагрузку.
Каждая функция, которую предполагается использовать в программе, должна быть в ней объявлена. Обычно объявления функций размещают в заголовочных файлах, которые затем подключаются к исходному тексту программы с помощью директивы #include. Объявление функции описывает её прототип (иногда говорят, сигнатура). Прототип функции объявляется следующим образом
[тип] имя([параметры]);
где имя – идентификатор (название) функции;
тип – возвращаемый функцией тип данных. Если
возвращаемый тип не указан, по умолчанию
подразумевается тип int;
параметры – список объявляемых параметров, задающий
тип и имя каждого параметра функции,
разделённых запятыми. Допускается в
в прототипе опускать имена параметров.
Список объявляемых параметров может
быть пустым;
( ) – ограничители параметров;
[ ] – признак необязательности содержимого.
Функция может быть пользовательской или стандартной.
Пользовательской называется функция, составленная им самим для оформления некоторого участка вычислений, желательно, многократного использования.
Стандартной является функция, созданная для выполнения стандартных вычислений (действий) и хранящаяся в одной из библиотек языка программирования.
Для того чтобы функция выполнила определённые действия, она должна быть вызвана в программе. При обращении к функции она выполняет поставленную задачу, а по окончании работы возвращает в качестве результата некоторое значение.
Вызов функции представляет собой указание идентификатора функции (её имени), за которым в круглых скобках следует список аргументов, разделённых запятыми:
имя(а1[,a2, … , an])
где имя – идентификатор функции;
а1 … аn – аргументы функции;
, – разделитель аргументов;
( ) – ограничители аргументов;
[ ] – признак необязательности содержимого.
В вычислительных процессах наиболее часто используются тригонометрические и другие математические функции. Программы их вычисления разработаны и включены в библиотеку математических функций (см. табл. 4). Прототипы стандартных математических функций определены в заголовочном файле math.h.
Таблица 4
| Математическая запись | Вызов функции | Наименование функции |
| xy | pow(x,y) | Возведение в степень |
| ex | exp(x) | Экспонента |
| ln x | log(x) | Вычисление натурального логарифма |
| log x | log10(x) | Вычисление десятичного логарифма |
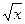
| sqrt(x) | Извлечение квадратного коння |
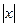
| fabs(x) | Нахождение абсолютного значения х |
| sin x | sin(x) | Синус |
| сos x | сos(x) | Косинус |
| tg(x) | tan(x) | Тангенс |
| arcsin x | asin(x) | Арксинус |
| arccos x | acos(x) | Арккосинус |
| arctg x | atan(x) | Арктангенс х |
| arctg y/x | atan2(x,y) | Арктангенс отношения y/х |
В качестве аргументов функции используются константы, переменные или их совокупности (арифметические выражения).
Аргументы тригонометрических функций предполагаются заданными в радианах.
2.3. Выражения
Выражение – это последовательность операндов, разделителей (круглых скобок) и знаков операций, задающая вычисление. Если выражение содержит арифметические операции, то оно называется арифметическим, если логические операции, то – логическим выражением.
В качестве операндов в С/С++ могут быть использованы константы, переменные и вызовы функций.
Язык С/С++ в значительной степени является языком выражений. Это следует из того факта, что некоторые операции, например присваивания, не реализуется с помощью специальных операторов, а трактуются как операции с двумя аргументами. Важной особенностью является возможность превращения произвольного выражения в оператор. Для этого достаточно закончить выражение точкой с запятой. Такой способ чаще всего используется в отношении операции присваивания, которая в записи, заканчивающейся точкой с запятой, образует оператор, известный из других языков программирования как оператор присваивания.
Структура оператора присваивания
ИП = А; ИП = L;
где ИП – идентификатор переменной;
= – символ операции присваивания
A(L) – арифметическое (логическое) выражение;
; – признак оператора.
Принципы вычисления значений выражений вытекают из семантики и приоритетов, содержащихся в них операций, а также из видов использованных аргументов (операндов). Если данный аргумент находится в границах более чем одной операции с одинаковыми приоритетами, то операции являются связанными. Большинство операций связывает аргументы слева направо. Исключение составляют только операции с одним аргументом и операции присваивания, а также трёхаргументная условная операция. Порядок применения операций к аргументам зависит от принятых в языке приоритетов и связей операций. Операции более высокого приоритета, выполняются в первую очередь. Если некоторый аргумент касается двух операций одинакового приоритета, то очерёдность выполнения операций определяется по связыванию. Для изменения порядка выполнения операций используют круглые скобки. Таким образом, выражение x = y = z означает x = (y = z), а выраженияе x + y + z означает (x + y) + z, согласно соответствующим правилам связывания.
Связывание и упорядочивание операций по очерёдности уменьшения приоритетов приведены в табл. 5.
Таблица 5
| № | Оператор | Описание | Приоритет | Связывание |
| :: | Разрешение видимости | => | ||
| [ ] | Индекс массива | => | ||
| ( ) | Вызов функции | => | ||
| . | Выбор члена структуры или класса | => | ||
| -> | ||||
| ++ | Постфиксный инкремент | <= | ||
| -- | Постфиксный декремент | <= | ||
| ++ | Префиксный инкремент | <= | ||
| -- | Префиксный декремент | <= | ||
| sizeof sizeof() | Размер | <= | ||
| (тип) | Преобразование типа | |||
| ~ | Инверсия | <= | ||
| ! | Логическое НЕ | <= | ||
| - | Унарный минус | <= | ||
| + | Унарный плюс | <= | ||
| & | Получение адреса | <= | ||
| * | Разыменование | <= | ||
| new new[] | Создание динамического объекта | <= | ||
| delete delete[] | Удаление динамического объекта | <= | ||
| casting | Приведение типа | |||
| * | Умножение | => | ||
| / | Деление | => | ||
| % | Остаток от деления | => | ||
| + | Сложение | => | ||
| - | Вычитание | => | ||
| >> | Сдвиг вправо | => | ||
| << | Сдвиг влево | => | ||
| < | Меньше | => | ||
| <= | Меньше или равно | => | ||
| > | Больше | => | ||
| >= | Больше или равно | => | ||
| == | Равно | => | ||
| != | Не равно | => | ||
| & | Побитовое И | => | ||
| ^ | Побитовое исключающее ИЛИ | => | ||
| | | Побитовое ИЛИ | => | ||
| && | Логическое И | => | ||
| || | Логическое ИЛИ | => | ||
| ?: | Условие | <= | ||
| = | Присваивание | <= | ||
| *= | Умножение с присваиванием | <= | ||
| /= | Деление с присваиванием | <= | ||
| %= | Модуль с присваиванием | <= | ||
| += | Сложение с присваиванием | <= | ||
| -= | Вычитание с присваиванием | <= | ||
| <<= | Сдвиг влево с присваиванием | <= | ||
| >>= | Сдвиг вправо с присваиванием | <= | ||
| &= | Побитовое И с присваиванием | <= | ||
| ^= | Исключающее ИЛИ с присваиванием | <= | ||
| |= | Побитовое ИЛИ с присваиванием | <= | ||
| throw | Генерация исключения | <= | ||
| , | Запятая | => |
Операция присваивания может быть простой и составной.
Структуру использования простой операции мы рассмотрели выше.
Составная операция присваивания имеет вид
ИП ор= А;
где ИП – идентификатор переменной (целой или вещественной );
ор – символ операции (см. табл. 5);
А – арифметическое выражение;
; – признак оператора.
Составное присваивание выполняется как присваивание вида
ИП = ИП ор А;
Например, a*=b; эквивалентно a=a*b; или a-=b; эквивалентно a=a-b;
2.3.1. Арифметические операции
Арифметические операции служат для описания арифметических действий: замена знака (-), инкремент (++), декремент (--), сложение (+), вычитание (-), умножение (*), деление (/), а также вычисление остатка от деления (%). Операторы замены знака, инкремента и декремента – однооперандные (унарные), а их использование приводит соответственно к смене знака операнда, добавлению к операнду числа 1 и вычитанию из операнда числа 1. Если операнд операции замены знака имеет тип unsigned, то замена знака реализуется путём вычитания операнда из числа 2n , где n – число битов, используемых для представления данных типа int.
Как и в Ассемблере, в С++ имеется эффективное средство увеличения и уменьшения значения операнда на единицу – унарные операции инкремента и декремента.
Унарные операции инкремента/декремента преобразуются компилятором в машинных код однозначно и на языке Ассемблера могут выглядеть так:
инкремент: INC N
декремент: DEC N
где N может быть либо регистром процессора, либо содержимым ячейки памяти.
По отношению к операнду данный вид операций может быть префиксным и постфиксным. Префиксная операция применяется к операнду перед использованием полученного результата. Постфиксная операция применяется к операнду после использования операнда.
Понятие префикса или постфикса имеет смысл главным образом в выражениях с присваиванием:
x = y++; // постфикс
index = --current;//префикс
count++; //унарная операция
//то же, что ++count;
abc--; //то же, что --abc;
Здесь переменная у сначала присваивается переменной х, а затем увеличивается на единицу. Переменная current сначала уменьшается на единицу, после чего результат присваивается переменной index.
Операция взятия остатка применяется только к целочисленным операндам (char, short, int, long) и дает остаток от деления первого операнда на второй. Например, результатом операции 6%2 будет 0, 5%2 будет 1, 7%4 будет 3 и т.д. Знак результата операции совпадает со знаком делимого.
Специальной операции деления нацело в С/С++ нет — для него применяется обычная операция деления (/). Если оба операнда ее являются целыми, то результат этой операции также будетцелым, равным частному от деления с остатком первого операнда на второй.
Внимание! В качестве предостережения заметим, что это свойство деления в С часто бывает источником ошибок даже у довольно опытных программистов. Предположим, нектохочет вычислить объем шара и пишет, переводя известную формулу на язык С:
volume = 4/3*Pi*r*r*r;
Все операции в выражении правой части имеют одинаковый приоритет, и оценка выражения производится в последовательности слева направо. На первом шаге производится деление 4/3, но это будет делением нацело с результатом, равным 1. Эта единица преобразуется далее в вещественное 1.0. Коэффициент в формуле, таким образом, получается равным 1.0 вместо ожидаемого 1.333...
Смешанные выражения
В арифметическом выражении могут присутствовать операнды различных типов — как целые, так и вещественные, а кроме того, и те и другие могут иметь различную длину (short, long и т. д.), в то время как оба операнда любой арифметической операции должны иметь один и тот же тип. В процессе оценки таких выражений компилятор следует алгоритму т. н. возведения типов, который заключается в следующем.
На каждом шаге вычисления выражения выполняется одна операция и имеются два операнда. Если их тип различен, операнд меньшего "ранга экстенсивности" приводится к типу более "экстенсивного". Под экстенсивностью понимается диапазон значений, который поддерживается данным типом. По возрастанию экстенсивности типы следуют в очевидном порядке:
Сhar, short
Int, long
Float
Double
Long double
Кроме того, если в операции участвуют знаковый и беззнаковый целочисленные типы, то знаковый операнд приводится к беззнаковому типу. Результат тоже будет беззнаковым. Во избежание ошибок нужно точно представлять, что при этом происходит, и при необходимости применять операцию преобразования типа, явно преобразующую тот или иной операнд.
Операция преобразования типа
Операция преобразования типа – однооперандная и в общем случае имеет вид
имя_типа(выражение) или (имя_типа)выражение
Первая форма вызова операции называется функциональной, вторая – канонической (она унаследована от языка С). Функциональная форма применима лишь в случаях, когда тип имеет простое (в одно слово) наименование. Результатом преобразования в обоих случаях является значение выражения-операнда, преобразованное к заданному типу. Например:
int i = 1;
float f = float(i+1);
unsigned long ul = (unsigned long)i;
В последней строке функциональная форма unsigned long(i) недопустима.
2.4. Операторы
Выполняемая часть программы на любом алгоритмическом языке состоит из операторов, которые определяют элементарные шаги и логику реализованного алгоритма. Операторы языка С++ делятся на три группы:
· операторы-выражения, получающиеся из произвольных выражений добавлением точки с запятой, как описано ранее;
· пустые операторы и блоки;
· операторы, начинающиеся с ключевого слова.
Блок – составной оператор, имеющий вид последовательности операторов, заключённой в фигурные скобки :
{ оператор1; оператор2; … }
Наличие в языке блока значительно расширяет возможности синтаксических конструкций: везде, где синтаксис позволяет использовать оператор, допустимо использование и блока операторов.
Специальным случаем оператора служит пустой оператор. Она представляется символом "точка с запятой", перед которым нет никакого выражения или не завершённого разделителем (;) оператора. Пустой оператор не предусматривает выполнения никаких действий. Он используется там, где синтаксис языка требует присутствия оператора, а по смыслу программы никакие действия не должны выполняться (например, в качестве тела цикла, когда все циклически выполняемые действия определены в заголовке цикла). Другое его применение связано с необходимостью в ряде случаев помечать пустое действие, например для реализации перехода к концу блока операторов.
2.4.1. Ввод и вывод в С/С++
В языке С/С++ отсутствуют стандартные операторы ввода-вывода. Организация ввода и вывода данных в языке С/С++ может быть реализована с помощью функций библиотеки стандартного ввода-вывода, объявление которых содержится в заголовочном файле stdiо.h, подключаемом к основной программе с помощью директивы include.
Наряду с библиотечными функциями язык С++ содержит дополнительный набор объектно-ориентированных средств ввода-вывода.
Рассмотрим сначала функции библиотеки стандартного ввода-вывода.
Функция ввода scanf()
Структура обращения к функции scanf():
scanf("строка форматирования", АП1[, АП2,…,АПn]);
где scanf – имя функции;
" строка форматирования" - список спецификаторов
вводимых данных (полей),
оформленный в виде
символьной строки;
АП1,…,АПn - список адресов переменных, которым
присваиваются значения вводимых
данных;
,…, - разделители аргументов функции;
[ ] – признак необязательности содержимого
; - признак оператора.
Функция scanf() сканирует (откуда и её название) поля из стандартного ввода (по умолчанию — клавиатуры) и форматирует каждое поле в соответствии со спецификатором формата, переданном в строке форматирования. Для каждого поля должен существовать спецификатор формата и адрес переменной, предназначенной для размещения результата преобразования поля в соответствии с заданным спецификатором формата. Функция может прекратить сканирование поля до достижения конца поля (символа-заполнителя) или прекратить сканирование полей вообще. В случае успеха scanf() возвращает число успешно просканированных, преобразованных и сохранённых входных полей. В это число не входят не сохранённые поля. Если ни одно поле не было сохранено, функция возвращает 0.
Строка форматирования представляет собой символьную строку, которая содержит объекты трёх типов:
· символы-заполнители;
· символы, отличные от символов-заполнителей;
· спецификаторы формата.
Символы-заполнители – это пробел, символ табуляции
(\t) и перевод строки (\n). Эти символы считываются из форматной строки, но не сохраняются.
Символы, отличные от символов-заполнителей – это все остальные символы, за исключением знака процента (%). Эти символы так же считываются, но не сохраняются.
Спецификаторы формата направляют процесс сканирования, считывания и преобразования символов из входного поля в переменные, заданные своими адресами. Каждому спецификатору формата должен соответствовать адрес переменной. Если спецификаторов формата больше, чем переменных, результат непредсказуем. Наоборот, если имеется больше переменных, чем спецификаторов формата, они игнорируются.
Спецификаторы формата имеют следующий вид:
% [*] [ширина] [F |[4] N] [h | l | L] символ_типа
Каждый спецификатор формата начинается с символа процента (%).
После знака процента идут следующие знаки в указанном в табл. 6 порядке.
Таблица 6
| Компонент | Обязательный или нет | Назначение |
| * | Нет | Символ подавления присвоения переменной значения следующего поля. Текущее поле сканируется, но не сохраняется в переменной. Предполагается, что аргумент, соответствующий спецификатору формата, содержащему звёздочку, имеет тип, указанный символом типа преобразования (type_char), который идёт за звёздочкой. |
| ширина | Нет | Спецификатор ширины поля. Задаёт максимальное число считываемых символов. Функция может прочесть меньше символов, если в потоке ввода встретится символ-заполнитель. |
| F | N | Нет | Модификатор величины указателя. Переопределяет величину по умолчанию аргумента задающего адрес: N – near pointer F – far pointer |
| h | l | L | Нет | Модификатор типа аргумента. Переопределяет тип по умолчанию аргумента, задающего адрес: h = short int l =long int, если type_char задаёт преобразование в целое l=double, если type_char задаёт преобразование в тип с плавающей точкой L=long double (верно только для преобразования в тип с плавающей точкой) |
| символ_типа | Да | Символ типа (преобразования) |
Возможные значения символа типа приведены в табл. 7.
Таблица 7
| Тип данных | Ожидаемый ввод | Тип вводимой переменной |
| d | Десятичное целое | Целая обычной точности (int). Если указан модификатор типа аргумента h, то вводимая переменная имеет тип короткое целое (short int). Если указан модификатор типа аргумента h, то вводимая переменная имеет тип длинное целое (long) |
| D | Десятичное целое | Длинное целое (long) |
| E,e | Число с плавающей точкой | Вещественное обычной точности. Если указан модификатор типа l, то вводимая переменная имеет тип double. Если указан модификатор типа L, то вводимая переменная имеет тип long double. |
| f | Число с фиксированной точкой | Вещественное обычной точности. Если указан модификатор типа l, то вводимая переменная имеет тип double. |
| о | Восьмеричное целое | Восьмеричное целое обычной точности (int) |
| О | Восьмеричное целое | Длинное восьмеричное целое (long) |
| i | Десятичное, восьмеричное или шестнадцатиричное целое | Целое обычной точности (int) |
| I | Десятичное, восьмеричное или шестнадцатиричное целое | Длинное целое (long) |
| u | Беззнаковое десятичное целое | Беззнаковое десятичное целое обычной точности (int) |
| U | Беззнаковое десятичное целое | Беззнаковое длинное десятичное целое (unsigned long) |
| х | Шестнадцатиричное целое | Шестнадцатиричное целое обычной точности (int) |
| Х | Шестнадцатиричное целое | Шестнадцатиричное длинное целое (long) |
| s | Символьная строка | Символьная строка (char arg[]) |
| c | Символ | Одиночный символ |
Кроме того, в качестве спецификаторов формата можно задать совокупность символов, заключённых в квадратные скобки. Соответствующий ему аргумент должен указывать на массив символов. Эти квадратные скобки определяют совокупность символов поиска. Если первым символом в квадратных скобках является каре (^), то условие соответствия инвертируется: во входном потоке ищутся символы, не соответствующие указанным в квадратных скобках.
Например,
%[abcd] - поиск во входном поле любого из символов a, b, c, d.
%[^abcd] - поиск во входном поле любого из символов, за исключением a, b, c, d.
Вы также можете указать диапазон поиска, задав символы через тире в качестве совокупности символов поиска.
Например,
%[0-9] – поиск во входном потоке любых десятичных цифр.
%[0-9A-Za-z] – поиск во входном потоке любых десятичных цифр и букв.
Сканирование прекращается, если очередной символ не попадает в совокупность символов поиска.
Функция может прекратить сканирование какого-то поля ещё до достижения его естественного конца (символа-заполнителя) или даже прекратить сканирование совсем. В частности, это происходит, когда в поле ввода появляется символ, не соответствующий по типу заданному преобразованию в спецификаторе формата. В этом случае результат может оказаться непредсказуем.
Адреса вводимых переменных. Любой объект программы (в том числе и переменные) занимает в памяти определённую область. Местоположение объекта в памяти определяется его адресом. Доступ к содержимому переменной осуществляется с использованием её идентификатора (имени). Для того, чтобы узнать адрес конкретной переменной, необходимо использовать унарную операцию взятия адреса. При этом перед именем переменной ставится знак амперсанда (&). Таким образом, адрес переменной имеет вид:
&имя,
где & – символ операции взятия адреса.
имя – идентификатор переменной, для которой
формируется адрес.
Например, для переменных a, x2, summa адресами будут &a, &x2, &summa.
Примечание. Для символьных строк адресом является имя символьной строки.
Примером вызова scanf() может служить следующий фрагмент кода:
int i, res;
float fp;
char c, s[81];
res=scanf("%d%f%c%s",&i, &f, &c, s);
printf("\n\n Количество полей ввода равно %d \n",res);
printf("Результат:\n %d %f %c %s\n", i, f, c, s);
При вводе исходных данных с клавиатуры:
1234 1234.5678 F string
программа выведет на экран монитора:
Количество полей ввода равно 4
Результат:
1234 1234.5678 F string
Функция вывода на экран монитора printf().
Структура обращения к функции printf():
printf(" управляющая строка", [АВ1,…,АВn]);
где printf – имя функции;
" управляющая строка" – список спецификаторов
выводимых данных (полей),
оформленный в виде
символьной строки;
АВ1,…,АВn – список арифметических выражений,
значения которых выводятся на дисплей
(в простейшем случае список может
содержать только имена выводимых
переменных);
,…, - разделители аргументов функции;
[ ] – признак необязательности содержимого
; - признак оператора.
Функция printf() позволяет осуществлять форматированный вывод в стандартный поток вывода stdout (по умолчанию – дисплей). Функция принимает последовательность аргументов, применяя к каждому аргументу спецификатор формата, который содержится в управляющей строке. Если аргументов меньше, чем спецификаторов формата, результат непредсказуем. С другой стороны, если аргументов больше, чем спецификаторов формата, лишние аргументы просто игнорируются. В случае успеха функция возвращает число выведенных байтов, в случае ошибки – значение EOF.
Управляющая строка в функции printf() определяет то, как эта функция будет преобразовывать, форматировать и выводить свои аргументы. Она представляет собой символьную строку, которая содержит два типа объектов:
· простые символы, которые копируются в выходной поток;
· спецификаторы формата, которые применяются к аргументам (арифметическим выражениям), выбираемым из списка аргументов.
Спецификаторы формата имеют следующий вид:
%[флаги] [поле][.точность][F | N | h | l | L] символ типа
Каждый спецификатор формата начинается с символа процента (%), после которого идут спецификаторы в порядке, указанном в табл. 8.
Таблица 8
| Компонент | Обязательный или нет | Назначение |
| флаги | Нет | Флаговые символы. Управляют выравниванием, знаком числа, десятичной точкой, конечными нулями, префиксами для восьмеричных и шестнадцатиричных чисел |
| поле | Нет | Спецификатор ширины поля. Указывает минимальное число выводимых символов (дополняемое в случае необходимости пробелами или нулями) |
| точность | Нет | Спецификатор точности. Указывает максимальное число выводимых символов; для целых чисел – минимальное число выводимых цифр |
| F | N | h | l | L | Нет | Модификатор размера. Переопределяет размер аргумента по умолчанию |
| символ типа | Да | Символ типа преобразования |
Флаговые символы (флажки) могут появляться в любом порядке и комбинации. Таблицы флажков и их смысл приведены в табл. 9.
Таблица 9
| Флажок | Назначение |
| - | Выровнять вывод по левому краю поля. |
| Заполнить свободные позиции нулями вместо пробелов. | |
| + | Всегда выводить знак числа. |
| пробел | Вывести пробел на месте знака, если число положительное. |
| # | Вывести 0 перед восьмеричным или Ох перед шестнадцатеричным значением. |
Замечание: Флажок «плюс» (+) имеет преимущество перед флажком «пробел» (' '), если они заданы оба.
Спецификатор ширины поля устанавливает минимальную ширину поля для выводимого значения. Ширина задаётся одним из двух способов:
· непосредственно с помощью десятичного числа;
· косвенно, с помощью символа звёздочки (*).
Если вы используете в качестве спецификатора ширины звёздочку, следующий аргумент в списке аргументов (который должен быть целым числом) задаёт не выводимое значение, а минимальную ширину поля для вывода. Если ширина поля вывода не указана или мала, это не вызывает усечения значения до ширины поля. Вместо этого поле расширяется до нужного размера, чтобы вместить результат преобразования значения. Спецификаторы ширины и их влияние на вывод перечислены в табл. 10
Таблица 10
| Спецификатор ширины | Влияние на вывод |
| N | По крайней мере N символов выводятся. Если выводимое значение имеет менее чем N символов, вывод дополняется пробелами (справа, если указан флажок минус (-), слева – в противном случае). |
| 0n | Выводится, по меньшей мере, n символов. Если выводимое значение имеет меньше чем n символов, оно дополняется слева нулями. |
| * | Список аргументов предоставляет спецификатор ширины, который должен предшествовать реально выводимому аргументу. |
Спецификатор точности функции printf() устанавливает максимальное число выводимых символов или минимальное число выводимых цифр для целых чисел. Этот спецификатор всегда начинается с точки, чтобы отделить его от предыдущего спецификатора ширины. Как и спецификатор ширины, он задаётся одним из двух способов:
· непосредственно, с помощью десятичного числа;
· косвенно, с помощью символа звёздочки (*).
Если вы используете звёздочку в качестве спецификатора точности, то следующий аргумент в списке аргументов (который должен быть целым числом) задаёт точность. Если вы задаёте звёздочки в качестве спецификаторов ширины и точности, то вслед за ними в списке аргументов должен идти спецификатор ширины, затем спецификатор точности, а за ними – само выводимое значение.
Спецификатор типа преобразования задаёт преобразование типа выводимого аргумента. Возможные значения символа типа преобразования и их назначение приведены в табл. 11. Информация в этой таблице основывается на предположении, что спецификатор формата не содержит ни флажков, ни спецификатора ширины, ни спецификатора точности, ни модификатора размера входного значения.
Таблица 11