Последовательность действий СУБД при обработке запросов пользователей
СУБД как совокупность языковых и программных средств, многофункциональность СУБД, способы доступа к данным, независимость данных(физическая, логическая и независимость от стратегии доступа).
Система управления базами данных (СУБД) – совокупность программных и лингвистических средств общего или специального назначения, обеспечивающих управление созданием и использованием баз данных.
Основные функции СУБД:
- управление данными во внешней памяти (на дисках);
- управление данными в оперативной памяти с использованием дискового кэша;
- защита логической целостности базы данных (корректность данных);
- защита физической целостности (сбои в работе железа);
- журнализация изменений, резервное копирование и восстановление базы данных после сбоев;
- поддержка языков БД (язык определения данных, язык манипулирования данными).
Обычно современная СУБД содержит следующие компоненты:
- ядро, которое отвечает за управление данными во внешней и оперативной памяти, и журнализацию;
- процессор языка базы данных, обеспечивающий оптимизацию запросов на извлечение и изменение данных и создание, как правило, машинно-независимого исполняемого внутреннего кода;
- подсистему поддержки времени исполнения, которая интерпретирует программы манипуляции данными, создающие пользовательский интерфейс с СУБД;
- а также сервисные программы (внешние утилиты), обеспечивающие ряд дополнительных возможностей по обслуживанию информационной системы.
Способы доступа к данным
Любое упорядочение (расположение) данных на диске называется структурой хранения. Можно организовать самые разные структуры хранения, обладающие различной производительностью и оптимальные для различных способов использования. Однако не существует идеальной структуры хранения, которая была бы оптимальна для любых задач. Исходя из этого, можно заключить, что совершенная СУБД должна содержать несколько разных структур хранения для различных частей системы. Кроме того, следует также предусмотреть возможность изменения структуры хранения по мере изменения требований к производительности системы.
Работа СУБД построена следующим образом и включает три основных этапа:
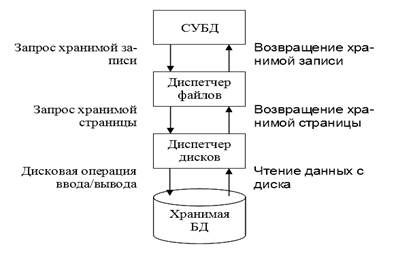
Сначала в СУБД определяется искомая запись, а затем для ее извлечения запрашивается диспетчер файлов.
Диспетчер файлов определяет страницу, на которой находится искомая запись, а затем для извлечения этой страницы запрашивает диспетчер дисков.
Наконец, диспетчер дисков определяет физическое положение искомой страницы на диске и посылает соответствующий запрос на ввод-вывод данных.
Индексирование
Индексный файл – это хранимый файл особого типа, в котором каждая запись состоит из двух значений, а именно данных и указателя. Данные соответствуют некоторому полю (индексному полю) из индексированного файла, а указатель служит для связывания с соответствующей записью индексированного файла. Индексное поле также называется индексным ключом (index key).
Индекс можно сравнить с предметным указателем обычной книги, который состоит из списка слов с "указателями" (номерами страниц) для упрощения поиска связанной с этими словами информации из "индексированного файла" (т.е. из содержимого книги).
Основным преимуществом использования индексов является значительное ускорение процесса выборки или извлечения данных, а основным недостатком – замедление процесса обновления данных, поскольку при каждом добавлении новой записи в индексированный файл потребуется также добавить новый индекс в индексный файл.
Хранимый файл может иметь несколько индексов, которые могут как раздельно, так и совместно использоваться для более эффективного доступа к записям.
Хеширование
Хешированием, хеш-адресацией или хеш-индексированием называется технология быстрого прямого доступа к хранимой записи на основе заданного значения некоторого поля. При этом не обязательно, чтобы поле было ключевым.
Ниже перечислены основные особенности этой технологии:
1. Каждая хранимая запись БД размещается по адресу, который вычисляется с помощью специальной хеш-функции на основе значения некоторого поля данной записи, т.е. хеш-поля, или хеш-ключа. Вычисленный адрес называется хеш-адресом.
2. Для сохранения записи в СУБД сначала вычисляется хеш-адрес новой записи, а затем диспетчер файлов помещает эту запись по вычисленному адресу.
3. Для извлечения нужной записи по заданному значению хеш-поля в СУБД сначала вычисляется хеш-адрес, а затем диспетчеру файлов посылается запрос для извлечения записи по вычисленному адресу.
Независимость данных
Обеспечение логической независимости данных предоставляет возможность изменения (в определенных пределах) логического представления базы данных без необходимости изменения физических структур хранения данных. Таким образом, изменение логического представления данных в прикладных программах не приводит к изменению структур хранения данных. Обеспечение физической независимости данных предоставляет возможность изменять (в определенных пределах) способы организации базы данных в памяти ЭВМ не вызывая необходимости изменения "логического" представления данных. Таким образом, изменение способов организации базы данных не приводит к изменению прикладных программ.
Классификация баз данных
По способу доступа к БД:
1. Файл-серверные
В файл-серверных СУБД файлы данных располагаются централизованно на файл-сервере. СУБД располагается на каждом клиентском компьютере (рабочей станции). Доступ СУБД к данным осуществляется через локальную сеть. Синхронизация чтений и обновлений осуществляется посредством файловых блокировок. Преимуществом этой архитектуры является низкая нагрузка на процессор файлового сервера. Недостатки: потенциально высокая загрузка локальной сети; затруднённость или невозможность централизованного управления; затруднённость или невозможность обеспечения таких важных характеристик как высокая надёжность, высокая доступность и высокая безопасность. Применяются чаще всего в локальных приложениях, которые используют функции управления БД; в системах с низкой интенсивностью обработки данных и низкими пиковыми нагрузками на БД.
На данный момент файл-серверная технология считается устаревшей.
Примеры: Microsoft Access, Paradox, dBase, FoxPro, Visual FoxPro.
2. Клиент-серверные
Клиент-серверная СУБД располагается на сервере вместе с БД и осуществляет доступ к БД непосредственно, в монопольном режиме. Все клиентские запросы на обработку данных обрабатываются клиент-серверной СУБД централизованно. Недостаток клиент-серверных СУБД состоит в повышенных требованиях к серверу. Достоинства: потенциально более низкая загрузка локальной сети; удобство централизованного управления; удобство обеспечения таких важных характеристик как высокая надёжность, высокая доступность и высокая безопасность.
Примеры: Oracle, Firebird, Interbase, IBM DB2, Informix, MS SQL Server, Sybase Adaptive Server Enterprise, PostgreSQL, MySQL, Caché, ЛИНТЕР.
3. Встраиваемые
Встраиваемая СУБД — СУБД, которая может поставляться как составная часть некоторого программного продукта, не требуя процедуры самостоятельной установки. Встраиваемая СУБД предназначена для локального хранения данных своего приложения и не рассчитана на коллективное использование в сети. Физически встраиваемая СУБД чаще всего реализована в виде подключаемой библиотеки. Доступ к данным со стороны приложения может происходить через SQL либо через специальные программные интерфейсы.
Примеры: OpenEdge, SQLite, BerkeleyDB, Firebird Embedded, Microsoft SQL Server Compact, ЛИНТЕР.
Последовательность действий СУБД при обработке запросов пользователей
Обработка запросов – это последовательность действий, выполняемая СУБД с целью извлечения данных с диска на основе запросов пользователей.
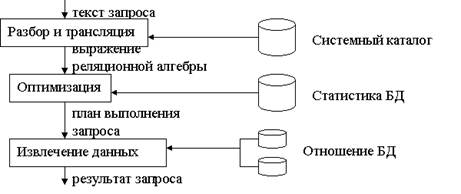
Этап 1.Производиться лексический и синтаксический анализ текста запроса на SQL и преобразование его в выражение реляционной алгебры. Кроме того производиться сопоставление имен, т.е. выяснятся существуют ли указанные отношения в бд и есть ли в них необходимые атрибуты.
Этап 2. Оптимизация состоит в нахождении выражений реляционной Алгебры эквивалентных начальному, но более эффективных с точки зрения извлечения данных. Кроме того для каждого оператора реляционной алгебры выбирается алгоритм работы. Если какое-либо действие может использовать индекс, то производится оценка эффективности этого индекса.
Этап 3. На основе выбранного запроса осуществляется непосредственное считывание данных из базы.
Есть два подхода к вычислению выражений при обработке запроса:
- параллельно выполняться две ветви запроса (в примере селекции), что повысит эффективность;
- параллельно выполняться операции в рамках одной ветви (конвейерная обработка).
Оптимизация запроса является шагом обработки запросов и основывается на том, что один и тот же запрос может быть транслирован в несколько выражений реляционной алгебры. Эти выражения могут выполняться с различной эффективностью. Работа оптимизатора состоит из 2-х частей:
- получение выражений реляционной алгебры, эквивалентных первоначальному;
- выбор стратегии выполнения запроса, т.е. алгоритма выполнения операций реляционной алгебры.
Существует 3 вида оптимизаторов:
1. Итеративный. Выбирается наиболее дешевый алгоритм для каждой операции в отдельности. Наиболее быстрый оптимизатор (не строит множество планов запроса), но малоэффективный (не учитывает влияние операций плана друг на друга).
2. Основанный на стоимостях. Генерирует все возможные планы выполнения запросов, для каждого плана рассчитывает его стоимость и выбирается наиболее дешёвый план. Гарантирует нахождение самого оптимального плана, но не эффективен для сложных запросов (занимает много времени).
3. Эвристический. Предполагает применение правил, найденных опытным путем.