Триггеры расширяют возможности субд в целом
CREATE TRIGGER SET QUANT ON STUDENT FOR - будет запускаться при добавление записи
DECLARE @ SSTUD INT;
DECLARE @SGR CHAR(4); - объявление переменных в триггере который может принимать значение в SET (SET @STUD=) или SELECT)
SELECT @SGR=SGROUP FROM INSERTED;
INSERTED/ DELETED – логич. виртуальная таблица БД, структура которой соответствует структуре таблице, для которой определён триггер и которая содержит старое или новое значение строки кот. м.б. изменена в результате действий пользователя.
SELECT @SSTUD =COUNT(SNUM) FROM STUDENT
WHERE SGROUP=SGR;
UPDATE SGROUP SET QUANT=SSTUD
WHERE SGROUP=@SGR;
Данный триггер будет выполняться когда добавляется новая запись в таблицу STUDENT
CREATE TRIGGER ins_prot
ON k_protokol FOR INSERT
AS
DECLARE @s_new NUMERIC(9,2),
@kolvo NUMERIC(6),
@bill_num NUMERIC(6)
SELECT @kolvo=kolvo FROM Inserted
IF @kolvo>0
BEGIN
SELECT @s_new=p.price_sum, @bill_num=bill_num
FROM k_price p, Inserted i
WHERE p.price_num=i.price_num
IF @s_new !=0
UPDATE k_bill
SET bill_sum=bill_sum+@s_new*@kolvo
WHERE k_bill.bill_num=@bill_num
END
Хранимые процедуры
это именованный набор процедурных и SQL операторов, хранящихся на сервере бд и испол. для выполнений повторений выполняющихся задач. Хрна процедуры выз. по имени, на выполнение передаёться сразу всё её значение, исключая повторного выполнения отдельных операторов по сети. Это уменьшает сетевой трафик и повышает производительность БД
CTEATE PROC имя_процедуры
[ { @parameter [{IN|OUT} ] data_type}]
AS BEGIN
SQL_statements
END
@parameter параметры, которые д.б. переданны в хранимую процедуру
data_type – 1 из типов данных, поддерживаемых СУБД
Для выполнения хранимой процедуры используется команда:
EXEC имя_процедуры (parameter-1,…,)
57. Физическое хранение отношений.
в файлах БД, структура хранения данных индексация
файлы: прямого доступа, последовательного доступа, индексы (индексно-прямые плотные индекс, индексно-последовательные неплотные индексы, В-деревья), взаимосвязанные файлы (с однонаправленными цепочками, с двунаправленными цепочками), инвертированные маски.
В РСУБД: строки отношений – большая часть БД, непосредственно видимой пользователем, управляющие структуры - индексы создаваемые пользователем, журнальная информация –поддерживаемая СУБД для повышения надёжности, служебная информация – поддерживаемая субд для внутренних потребностей
файлы с плотным индексом.В этих файлах основная область содержит последовательность записей одинаковой длины, расположенных в произвольном порядке, а структура индексной записи в них имеет следующий вид: Значение ключа Номер записи
Неплотный индекс строится именно для упорядоченных файлов. Для этих файлов используется принцип внутреннего упорядочения для уменьшения количества хранимых индексов. Структура записи индекса для таких файлов имеет следующий вид: Значение ключа первой записи блока Номер блока с этой записью. В индексной области мы теперь ищем нужный блок по заданному значению первичного ключа.
Механизм добавления и удаления записи при организации индекса в виде В-дерева аналогичен механизму, применяемому в случае с неплотным индексом.
это наличие вторых названий для плотного и неплотного индексов.
В случае плотного индекса после определения местонахождения искомой записи доступ к ней осуществляется прямым способом по номеру записи, поэтому этот способ организации индекса и называется индексно-прямым.
В случае неплотного индекса после нахождения блока, в котором расположена искомая запись, поиск внутри блока требуемой записи происходит последовательным просмотром и сравнением всех записей блока. Поэтому способ индексации с неплотным индексом называется еще и индексно-последовательным.
Файлы с постоянной длиной записи, расположенные на устройствах прямого доступа (УПД), являются файлами прямого доступа.
В этих файлах физический адрес расположения нужной записи может быть вычислен по номеру записи (NZ).
Файлы с переменной длиной записи всегда являются файлами последовательного доступа. Они могут быть организованы двумя способами:
1. Конец записи отличается специальным маркером.
2. В начале каждой записи записывается ее длина.
с однонаправленными цепочками в этом случае связываются два файла, например F1 и F2, причем предполагается, что одна запись в файле F1 может быть связана с несколькими записями в файле F2. При этом файл F1 в этом комплексе условно называется «Основным», а файл F2 — «зависимым» или «подчиненным». Структура основного файла может быть условно представлена в виде трех областей.
Однако часто бывает необходимо просматривать цепочку подчиненных записей в двух направлениях: прямом и обратном. В этом случае применяют двойные указатели. В «основном файле» один указатель равен номеру первой записи в цепочке записей «подчиненного файла», а второй — номеру последней записи. В «подчиненном файле» один указатель равен номеру следующей записи в цепочке, а другой — номеру предыдущей записи в цепочке. Для первой и последней записей в цепочке один из указателей пуст, то есть равен пробелу.
Инвертированный список в общем случае — это двухуровневая индексная структура. Здесь на первом уровне находится файл или часть файла, в которой упорядочено расположены значения вторичных ключей. Каждая запись с вторичным ключом имеет ссылку на номер первого блока в цепочке блоков, содержащих номера записей с данным значением вторичного ключа. На втором уровне находится цепочка блоков, содержащих номера записей, содержащих одно и то же значение вторичного ключа. При этом блоки второго уровня упорядочены по значениям вторичного ключа.
два подхода к физическому хранению отношений.
покортежное хранение отношений (кортеж является единицей физического хранения). это обеспечивает быстрый доступ к целому кортежу, но при этом во внешней памяти дублируются общие значения разных кортежей одного отношения и, вообще говоря, могут потребоваться лишние обмены с внешней памятью, если нужна часть кортежа.
по столбцам, т.е. единицей хранения является столбец отношения с исключенными дубликатами. Естественно, что при такой организации суммарно в среднем тратится меньше внешней памяти, поскольку дубликаты значений не хранятся; за один обмен с внешней памятью в общем случае считывается больше полезной информации.
По картежам основным характеристикам:
· Каждый кортеж обладает уникальным идентификатором (tid), не изменяемым во все время существования кортежа.
· Обычно каждый кортеж хранится целиком в одной странице. Из этого следует, что максимальная длина кортежа любого отношения ограничена размерами страницы. "длинными" данными, простым решением является хранение таких данных в отдельных (вне базы данных) файлах с заменой "длинного" данного в кортеже на имя соответствующего файла. можно такие данные хранить в отдельном наборе страниц внешней памяти, связанном физическими ссылками.
· Как правило, в одной странице данных хранятся кортежи только одного отношения. Существуют, однако, варианты с возможностью хранения в одной странице кортежей нескольких отношений. Это вызывает некоторые дополнительные расходы по части служебной информации \
· Изменение схемы хранимого отношения с добавлением нового столбца не вызывает потребности в физической реорганизации отношения. Достаточно лишь изменить информацию в описателе отношения и расширять кортежи только при занесении информации в новый столбец.
· Поскольку отношения могут содержать неопределенные значения, необходима соответствующая поддержка на уровне хранения. Обычно это достигается путем хранения соответствующей шкалы при каждом кортеже, который в принципе может содержать неопределенные значения.
· Проблема распределения памяти в страницах данных связана с проблемами синхронизации и журнализации и не всегда тривиальна.
· Распространенным способом повышения эффективности СУБД является кластеризация отношения по значениям одного или нескольких столбцов.
· С целью использования возможностей распараллеливания обменов с внешней памятью иногда применяют схему декластеризованного хранения отношений: кортежи с общим значением столбца декластеризации размещают на разных дисковых устройствах, обмены с которыми можно выполнять в параллель.
Что же касается хранения отношения по столбцам, то основная идея состоит в совместном хранении всех значений одного (или нескольких) столбцов. Для каждого кортежа отношения хранится кортеж той же степени, состоящий из ссылок на места расположения соответствующих значений столбцов
58. Индексы
Чтобы облегчить операции связанные с поиском создается второй файл, называемый разреженным индексом, который состоит из пары (х,b), где х-значение ключа, а b- это физический адрес блока в котором значение ключа первой записи равно х.
их основное назначение состоит в обеспечении эффективного прямого доступа к кортежу отношения по ключу. Обычно индекс определяется для одного отношения, и ключом является значение атрибута (возможно, составного). Если ключом индекса является возможный ключ отношения, то индекс должен обладать свойством уникальности. для проверки сохранения свойства уникальности возможного ключа так или иначе требуется индексная поддержка.
полезным свойством индекса является обеспечение последовательного просмотра кортежей отношения в диапазоне значений ключа в порядке возрастания или убывания значений ключа.
оптимизации выполнения эквисоединения отношений является организация так называемых мультииндексов для нескольких отношений, обладающих общими атрибутами. Любой из этих атрибутов (или их набор) может выступать в качестве ключа мультииндекса. Значению ключа сопоставляется набор кортежей всех связанных мультииндексом отношений, значения выделенных атрибутов которых совпадают со значением ключа.
Общей идеей любой организации индекса, поддерживающего прямой доступ по ключу и последовательный просмотр в порядке возрастания или убывания значений ключа является хранение упорядоченного списка значений ключа с привязкой к каждому значению ключа списка идентификаторов кортежей. Одна организация индекса отличается от другой главным образом в способе поиска ключа с заданным значением.
59. Использования B-деревьев
B-дерево - это сбалансированное сильно ветвистое дерево во внешней памяти. Сбалансированность означает, что длина пути от корня дерева к любому его листу одна и та же. B-дерево представляется как мультисписочная структура страниц внешней памяти, т.е. каждому узлу дерева соответствует блок внешней памяти (страница). Внутренние и листовые страницы обычно имеют разную структуру.
структура внутренней страницы 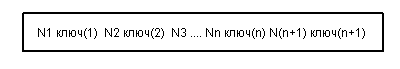
следующие свойства:
· ключ(1) <= ключ(2) <= ... <= ключ(n);
· в странице дерева Nm находятся ключи k со значениями ключ(m) <= k <= ключ(m+1).
Листовая страница имеет следующую структуру 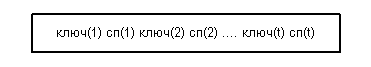 :
:
Листовая страница обладает следующими свойствами:
· ключ(1) < ключ(2) < ... < ключ(t);
· сп(r) - упорядоченный список идентификаторов кортежей (tid), включающих значение ключ(r);
· листовые страницы связаны одно- или двунаправленным списком.
Поиск в B-дереве - это прохождение от корня к листу в соответствии с заданным значением ключа, в сбалансированном дереве, где длины всех путей от корня к листу одни и те же, если во внутренней странице помещается n ключей, то при хранении m записей требуется дерево глубиной logn(m), где logn вычисляет логарифм по основанию n. Если n достаточно велико (обычный случай), то глубина дерева невелика, и производится быстрый поиск.
При занесение новой записи выполняется:
· Поиск листовой страницы. Фактически, производится обычный поиск по ключу.
· Помещение записи на место. Листовая страница, в которую требуется занести запись, считывается в буфер, и в нем выполняется операция вставки.
· Если после выполнения вставки новой записи размер используемой части буфера не превосходит размера страницы, то на этом выполнение операции занесения записи заканчивается. Буфер может быть немедленно вытолкнут во внешнюю память, или временно сохранен в оперативной памяти в зависимости от политики управления буферами.
· Если же возникло переполнение буфера, то выполняется расщепление страницы. Для этого запрашивается новая страница внешней памяти, используемая часть буфера разбивается пополам, и вторая половина записывается во вновь выделенную страницу, а в старой странице модифицируется значение размера свободной памяти.
· Чтобы обеспечить доступ от корня дерева к заново заведенной страницы, необходимо соответствующим образом модифицировать внутреннюю страницу,. вставить в нее соответствующее значение ключа и ссылку на новую страницу.
· Предельным случаем является переполнение корневой страницы B-дерева. В этом случае она тоже расщепляется на две, и заводится новая корневая страница дерева, т.е. его глубина увеличивается на единицу.
При удалении записи выполняются следующие действия:
· Поиск записи по ключу. Если запись не найдена, то значит удалять ничего не нужно.
· Реальное удаление записи в буфере, в который прочитана соответствующая листовая страница.
· Если размер занятой в буфере области оказывается таковым, что его сумма с размером занятой области в листовых страницах, являющихся братом данной страницы, больше, чем размер страницы, операция завершается.
· Иначе производится слияние с правым или левым братом, т.е. в буфере производится новый образ страницы, содержащей общую информацию из данной страницы и ее левого или правого брата.
· Чтобы устранить возможность доступа от корня к освобожденной странице, нужно удалить соответствующее значение ключа и ссылку на освобожденную страницу из внутренней страницы - ее предка.
· Предельным случаем является полное опустошение корневой страницы дерева, которое возможно после слияния последних двух потомков корня. В этом случае корневая страница освобождается, а глубина дерева уменьшается на единицу.
расщепления и слияния. с минимизацией числа расщеплений и слияний:
· упреждающие расщепления, т.е. расщепления страницы не при ее переполнении, а несколько раньше, когда степень заполненности страницы достигает некоторого уровня;
· переливания, т.е. поддержание равновесного заполнения соседних страниц;
· слияния 3-в-2, т.е. порождение двух листовых страниц на основе содержимого трех соседних.
60 . хеширование
В поле ключа индексного файла хранятся значения ключевых полей индексированной таблицы или свертка ключа (хеш-код).
Хеширование— преобразование входного массива данных произвольной длины в выходную битовую строку фиксированной длины. Такие преобразования также называются хеш-функциями или функциями свёртки, а их результаты называют хешем, хеш-кодом
подходом к организации индексов является использование техники хэширования
Общей идеей методов хэширования является применение к значению ключа некоторой функции свертки (хэш-функции), вырабатывающей значение меньшего размера. Свертка значения ключа затем используется для доступа к записи.
В самом простом, классическом случае, свертка ключа используется как адрес в таблице, содержащей ключи и записи. Основным требованием к хэш-функции является равномерное распределение значение свертки. При возникновении коллизий (одна и та же свертка для нескольких значений ключа) образуются цепочки переполнения. Главным ограничением этого метода является фиксированный размер таблицы.
преимущество хэширования - доступ к записи почти всегда за одно обращение к таблице - будет утрачено. Расширение таблицы требует ее полной переделки на основе новой хэш-функции.
В случае баз данных такие действия являются абсолютно неприемлемыми. Поэтому обычно вводят промежуточные таблицы-справочники, содержащие значения ключей и адреса записей, а сами записи хранятся отдельно. Тогда при переполнении справочника требуется только его переделка, что вызывает меньше накладных расходов.
Чтобы избежать потребности в полной переделки справочников, при их организации часто используют технику B-деревьев с расщеплениями и слияниями. Хэш-функция при этом меняется динамически, в зависимости от глубины B-дерева.
61. Одноуровневая и двухуровневая схема индексации
Одноуровневая схема.
В индексном файле хранятся короткие записи, имеющие по два поля:
1. поле значения старшего ключа, адресуемого блока
2. поле адреса начала этого блока
В каждом блоке записи располагаются в порядке возрастания значения ключа или свертки. Старшим ключом каждого блока является ключ его последней записи.
Алгоритм поиска для данной схемы состоит из трех шагов:
1. образование свертки значения ключевого поля для искомой записи
2. поиск в индексном файле записи о блоке, значение 1-го поля которого больше полученной свертки
3. последовательный просмотр записей блока до совпадения сверток искомой записи и записи блока. В случае коллизии сверток ищется запись, значение ключа которой совпадает со значением ключа исходной записи.
Недостаток: хранение ключей или сверток записей вместе с самими записями – это приводит к увеличению времени поиска из-за большой длины просмотра.
Двухуровневая схема.
В этой схеме индекс основной таблицы распределен по совокупности файлов: одному файлу главного индекса и множеству файлов с блоками ключей. (глав. индекс – блок ключей –запись) каждому ключу соотв. одна запись
Вторичный индекс
Вторичные индексы- это файлы состоящие из пар (v , p), где v-это список значений по одному для каждого из полей F1 , F2 … Fn , а p-это указатель на v.
Индексы, создаваемые пользователем для не ключевых полей, иногда называют вторичными (пользовательскими) индексами. Введение таких индексов не изменяет физического расположения записей таблицы, но влияет на последовательность просмотра записей. Индексные файлы, создаваемые для поддержания вторичных индексов таблицы, обычно называются файлами вторичных индексов.
Связь вторичного индекса с элементами данных базы может быть установлена различными способами. Один из них - использование вторичного индекса как входа для получения первичного ключа, по которому затем с использованием первичного индекса производится поиск необходимых записей).
62. Влияние индексирования на производительность
Главная причина повышения скорости выполнения различных операций в индексированных таблицах состоит в том, что основная часть работы производится с небольшими индексными файлами, а не с самими таблицами. Наибольший эффект повышения производительности работы с индексированными таблицами достигается для значительных по объему таблиц. Индексирование требует небольшого дополнительного места на диске и незначительных затрат процессора на изменение индексов в процессе работы.
Принципиальным отличием кластерного индекса от индексов других типов является то, что при его определении в таблице физическое расположение данных перестраивается в соответствии со структурой индекса . Логическая структура таблицы в этом случае представляет собой скорее словарь, чем индекс. Данные в словаре физически упорядочены, например по алфавиту.
Кластерные индексы могут дать существенное увеличение производительности поиска данных даже по сравнению с обычными индексами. Увеличение производительности особенно заметно при работе с последовательными данными. Если в таблице определен некластерный индекс, то сервер должен сначала обратиться к индексу, а затем найти нужную строку в таблице. При использовании кластерных индексов следующая порция данных располагается сразу после найденных ранее данных.
СУБД MySQL использует индексы в :
· индексы используются для поиска строк, WHERE, или строк, имеющих соответствия в других таблицах при выполнении объединения.
· для ускорения поиска при MIN() или MAX().
· для ускорения ORDER BY и GROUP BY.
· иногда СУБД может избежать чтения из файла данных вообще, при выборке только индексированного столбца.
63. Создание и удаление индексов CREATE [ UNIQUE | FULLTEXT | SPATIAL ]INDEX index_name [ USING = index_type ] ON table_name (index_columns)Оператор CREATE INDEX не может быть использован для создания индекса PRIMARY KEY, для этого необходимо использовать оператор ALTER TABLE.
ALTER TABLE table_name ADD PRIMARY KEY (index_columns)ALTER TABLE table_name ADD INDEX [index_name] (index_columns)ALTER TABLE table_name ADD FULLTEXT [KEY | INDEX] [index_name] (index_columns)ALTER TABLE table_name ADD UNIQUE (index_name) (index_columns)ALTER TABLE table_name ADD SPATIAL [KEY | INDEX] [index_name] (index_columns)индексируемого столбца. Кроме того, оператор ALTER TABLE позволяет удалять индексы:
ALTER TABLE table_name DROP [KEY | INDEX] index_nameALTER TABLE table_name DROP PRIMARY KEY илиDROP INDEX index_name ON table_nameDROP INDEX `PRIMARY` ON table_name
64. Транзакции
Транзакция – это последовательность операций базы данных (один или более запросов к БД), которые обращаются к БД. Транзакция – это логическая единица работы, т.е. она должна быть полностью выполнена или отменена без промежуточных положений. Все транзакции должны иметь следующие свойства:
1 – атомарность – требует, чтобы все операции (части) транзакции были завершены, иначе транзакция отменяется
2_ - устойчивость гарантирует, что если транзакция завершена, то БД достигает непротеворичивого состояния; это состояние не может быть утрачено даже в случае сбоя системы
3 – сериализуемость - возможность выполнения нескольких тран-ий одновременно, точнее их последовательность. В многопользоват. и в распред. БД – несколько транзак-ий могут выполняться параллельно.4 – изолированность – гарантирует, что данные, использующиеся во время выполнения о транзакции, не будут использованы второй транзакцией до того, как, первая не будет завершена.
Транзакция, которая изменяет содержимое БД, переводит БД из одного устойчивого состояния в другое.
Устойчивым состоянием БД считается состояние, при котором выполняются все условия ограничения целостности. Чтобы гарантировать устойчивость БД, каждая транзакция должна начинаться только в устойчивом состоянии БД.
Совокупность функций СУБД по организации и управлению транзакциями называют монитором транзакций.
В однопользовательских БЛ гарантируется изолированность и сериализуемость
65. Управление транзакциями
COMMIT Завершить транзакцию – завершить обработку информации, объединенную в транзакцию, всё записать с БД
ROLLBACK Откатить транзакцию – отменить изменения, приведенные в ходе выполнения транзакции
SAVEPOINT Сохранить промежуточную точку выполнения транзакции – сохранить промежуточное состояние БД, пометить его для того, чтобы можно было в дальнейшем к нему вернуться
~ COMMIT достигнуть конец программы, все изменения записаны в БД
~ROLLBACK выполнение программы неож. прервано
Но в некоторых SQL – Begin TRANSACTION - указ. на начало новой транзакции
Журнал транзакций
Для отслеживания всех транзакций, обновляющих БД. Информация, содержащаяся в этом журнале, используется СУБД для восстановления БД, выполняемого оператором ROLLBACK при прерывании выполнения программы или системном сбое (проблемы сети или поломка жесткого I диска).
В журнале хранится следующая информация:
· запись о начале транзакции;
· для каждого компонента транзакции (SQL-оператора) хранятся:
• тип выполняемой операции (обновление, удаление, вставка);
• имена объектов, на которые влияет транзакция (названия таблиц);
• значения "до" и "после" для обновляемых полей;
• указатели на предыдущую и последующие записи для такой же транзакции;
завершение транзакции (COMMIT).
TRL ID = идентификатор записи в журнале транзакций
TRX NUM = номер транзакции
PTR = указатель идентификатора записи в журнале транзакций
66. Восстановление транзакций
концепции:
1. протокол упреждения записи- гарантирует что журнал т. всегда записывается перед обновлением бд ля её восстановления
2. резервные журналы транзакции – копии
3. буфера БД – при обновлении данных, запис. копия в буфер, одной операцией (отложенная запись), что позволяет экономить время на обработку данных
4. установка контр. точки БД – когда субд записывает обновл. буфера на диск субд автомат. создаёт несколько контр. точек
процесс восстановления
1. если отложенная запись. – то операции т. записываются не сразу на физ. диск, только после т. достигнет точки завершения
процесс восс-ия для всех начатых и завершённых тра-ий:
1) определяется последняя контр. точка в журнале т., время после. физ. сохранения данных на диске
2)для т-й, которые были начаты или завершены перед контр. точкой, не надо выполнять ни каких операция, так как данные уже сохранены.
3) тр-ий которые завершились после конт. точки- СУБД использует записи в ЖТ для её повторного выполнения и обновления в БД на основе значений после.
4) не треб. завершать тран-ию, в которой имеется операция ROLLBACK после послед. контр. точки, или которая оставалась активной перед сбоем.
2. Сквозная запись – БД обновляется каждый раз при выполнении операции в рамках транзакции даже до достижения тран. точке завершения. Если транзакция прерывается перед дост-ем точки завершения, то для восстановления БД исп. операция ROLLBACK
процесс восстановления:
- // -
4) для транзакции с ROLLBACK после конт. точки или оставав. активной перед сбоем СУБД ис. записи в журнале тран-ии для её отмены на основании значений до. ( от новых к старым)
67 Управление параллельным выполнением транзакций
Управление параллельным выполнением транзакций это координирование одновременного исполнения транзакций в распределенных базах данных. Цель - обеспечении сериализации транзакций в многопользовательских базах данных. одновременное выполнение транзакций в распределенных базах данных может стать причиной проблем с целостностью и непротиворечивостью данных.
проблемы:
1. Потеря изменений
когда 2 транзакции выполняются параллельно и 2я транзакция получает доступ к данным, кот. исп. 1я тран-ия до её завершения
2. несвязность данных
когда 2 транзакции выполняются параллельно и 1я транзакция отменяется после того, как 2 ая уже получила доступ к несвязным данным.
3. Неоднозначность поиска
когда 2 транзакции выполняются параллельно и 2я транзакция выполняет агрегатную ф-цию над возможными данными, в то время как 1ая транзакция обновляет данные и ещё не завершилась (2ая может считывать данные до того как они обновились)
планировщик
Планировщик (scheduler) устанавливает порядок, в котором выполняются операции в параллельных транзакциях. Чтобы определить должный порядок, планировщик действует на основе алгоритмов управления параллельным выполнением. Если невозможно спланировать выполнение транзакция - FIFO
68. Определение и свойства транзакции. Определение блокировки. Степени детализации блокировки. 64 вопрос
методом блокировки
Блокировка (lock) гарантирует эксклюзивное использование SQL данных только в данной транзакции. Другими словами, транзакция Т2 не получит доступа к данным, которые в настоящий момент используются в транзакции Т1. Транзакция предварительно блокирует доступ к данным; блокировка снимается после завершения транзакции.
Управлением блокировками на сервере занимается менеджер блокировок, контролирующий их применение и разрешение конфликтов.
Степень детализации.
Размер элементов данных, выбранных в качестве защищаемой единицы для протокола управления параллельным выполнением.