Топтар мен коммуникаторлар. Ранг. Группа - это некое множество ветвей
Группа - это некое множество ветвей. В распоряжение программиста предоставлен тип MPI_Group и набор функций, работающих с переменными и константами этого типа. Констант, собственно, две: MPI_GROUP_EMPTY может быть возвращена, если группа с запрашиваемыми характеристиками в принципе может быть создана, но пока не содержит ни одной ветви; MPI_GROUP_NULL возвращается, когда запрашиваемые характеристики противоречивы.
Коммуникатор-именно с коммуникаторами программист имеет дело, вызывая функции пересылки данных, а также подавляющую часть вспомогательных функций. Для получения своего ранга процесс может использовать функцию MPI_Comm_rank с двумя параметрами. Первый — коммуникатор, которому принадлежит данный процесс. В терминологии MPI коммуникатором называется группа потоков. Все потоки по умолчанию принадлежат коммуникатору MPI_COMM_WORLD, и нумерация идет с нуля. MPI_Comm_rank— это адрес, по которому будет записан ранг процесса. Для получения общего количества процессов в коммуникаторе используется функция MPI_Comm_size с такими же параметрами. Тут мы предполагаем, что ветвь 0 главная, а остальные управляются ею. Однако можно сделать и совсем по-другому, предоставляется полная свобода. Скелет MPI-программы var p:pointer;
rank,size:integer; begin
p:=nil;
rank:=0;
MPI_Init(@rank,p);
MPI_Comm_rank(MPI_COMM_WORLD,@rank);
MPI_Comm_size(MPI_COMM_WORLD,@size);
if rank=0 then begin
end else begin
end; MPI_Finalize(); end.
3 . 2*cos(x) функциясының интегралын [0,1] аймақта параллельді есептеңіз.
double f(double x)
{return 2*cos(x);}
int main(intargc,char **argv){
intsize,rank;
MPI_Status status; MPI_Init(&argc,&argv);
MPI_Comm_rank(MPI_COMM_WORLD,&rank);
MPI_Comm_size(MPI_COMM_WORLD,&size);
float h=0.05,a=0,b=1,s=0.0;
for(inti=rank; a+h*(i+1)<b+h; i+=size)
{ s+=h*f(a+h*(i+1)); }
if(rank!=0) { MPI_Send(&s,1,MPI_FLOAT,0,1,MPI_COMM_WORLD); }
if(rank==0) { float r;
MPI_Recv(&r,1,MPI_FLOAT,1,1,MPI_COMM_WORLD,&status); s+=r;
printf("s=%f\n ",s); }}
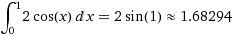
Сурак
1.Амдал заны. Үдеу. Тиімділік.
В общем случае структура информационного графа алгоритма занимает промежуточное положение между крайними случаями полностью последовательного и полностью параллельного алгоритма. В этой структуре имеются фрагменты, которые допускают одновременное выполнение на нескольких функциональных устройствах -- это параллельная часть программы. Есть и фрагменты, которые должны выполняться последовательно и на одном устройстве — это последовательная часть программы.
С помощью информационного графа можно оценить максимальное ускорение, которого можно достичь при распараллеливании алгоритма там, где это возможно. Предположим, что программа выполняется на машине, архитектура которой идеально соответствует структуре информационного графа программы. Пусть время выполнения алгоритма на последовательной машине Т1, причем Тs — время выполнения последовательной части алгоритма, а Тр — параллельной. Очевидно:T1 = TS + Тр.
При выполнении той же программы на идеальной параллельной машине, N независимых ветвей параллельной части распределяются по одной на V процессоров, поэтому время выполнения этой части уменьшается до величины Тр / N, а полное время выполнения программы составит:T2=TS+ Tp/N.
Коэффициент ускорения, показывающий, во сколько раз быстрее программа выполняется на параллельной машине, чем на последовательной, определяется формулой:Х= Т}/Т2 = (Ts + Tp) / (Ts + Tp/N) = 1/(S + P/N),
где S= Ts / (Ts + Tp) и P= Tp / (Ts + Tp) — относительные доли последовательной и параллельной частей (S+ Р= 1). Эта зависимость носит название закона Амдала.
2.MPI мәлімет типтері. Олар не үшін керек ? Қолдану мысалдары.
MPI содержит строгое описание типов передаваемых данных, от машинных примитивов до сложных структур, массивов и индексов.Все функции приема/передачи сообщений имеют в качестве одного из своих аргументов тип данных, чье C-определение есть MPI_Datatype. В MPI определены несколько значений MPI_Datatype, которые достаточны для представления типов на большинстве архитектур:
MPI_CHAR-знаковое символьное.MPI_SHORT-знаковое коротк целое.MPI_INT-знаковое целое.MPI_LONG-знаковое длин целое.MPI_UNSIGNED_CHAR-беззнак символьное.MPI_UNSIGNED_SHORT-беззнак коротк целое.MPI_UNSIGNED-беззнак целое.MPI_UNSIGNED_LONG-беззнак длинное целое.MPI_FLOAT-число с плав точкой.MPI_DOUBLE-число двойной точн.MPI_LONG_DOUBLE-число четырехкр точн.MPI_BYTE=битовые данные . Непрерывный- производит новый тип данных из count копий существующего со смещениями, увеличивающимися на протяженность oldtype (исходного типа). Простейший пример - массив элементов какого-то уже определенного типа; · Векторный- Элементы отделяются промежутками кратными протяженности исходного типа данных. Пример - столбцы матрицы, при определении матрицы как двумерного массива; · H-векторный: похож на векторный, но расстояние между элементами задается в байтах;· Индексный: при создании этого типа используется массив смещений исходного типа данных; смещения измеряются в терминах протяженности исходного типа данных; Структурный: обеспечивает самое общее описание. Фактически, если исходные аргументы состоят из базовых типов MPI, задаваемая структура есть в точности карта создаваемого типа.
3.Санды қарапайымдылықа тексеру параллельді программасын жазыңыз.
В данном случае программа должна вывести “Prostoe”.
int main(intargc,char **argv)
{
intsize,rank;
MPI_Status status;
MPI_Init(&argc,&argv);
MPI_Comm_rank(MPI_COMM_WORLD,&rank);
MPI_Comm_size(MPI_COMM_WORLD,&size);
int k=127,p,l=0,x1,l1,l2=0,itog=0,i; // k - issleduemoechislo
p=k/(size-1);
if (rank!=size-1) // schitautvseprocessy, kromeposlednego
// metodpereboradelitelei
{ for (i=rank*p+1; i<=(rank+1)*p; i++) { x1=k/i; if (x1*i==k) {l++;} }
MPI_Send(&l,1,MPI_INT,size-1,1,MPI_COMM_WORLD);}
else
{ for (i=0; i<size-1; i++) // poslednii process vsesobiraet
{ MPI_Recv(&l1,1,MPI_INT,i,1,MPI_COMM_WORLD, &status); itog+=l1; }
for (i=(size-1)*p+1; i<=k; i++) { x1=k/i; if (x1*i==k) {l2++;} } itog+=l2;
if (itog>2) {printf("Ne yavlyaetsyaprostym\n"); } else { printf("Prostoe\n"); } }
MPI_Finalize();}
Сурак
1.Қазіргі параллель архитектуралы компьютерлер. Аппараттық бөлімі.
Архитектуры параллельных компьютеров могут значительно отличаться друг от друга. Рассмотрим некоторые существенные понятия и компоненты параллельных компьютеров. Параллельные компьютеры состоят из трех основных компонент: процессоры, модули памяти, и коммутирующая сеть. Можно рассмотреть и более изощренное разбиение параллельного компьютер на компоненты, однако, данные три компоненты лучше всего отличают один параллельный компьютер от другого. Одним из свойств различающих параллельные компьютеры является число возможных потоков команд. Различают следующие архитектуры:
MIMD (MultipleInstructionMultipleData - множество потоков команд и множество потоков данных). MIMD компьютер имеет Nпроцессоров, N потоков команд и N потоков данных. Каждый процессор функционирует под управлением собственного потока команд.
SIMD (SingleInstructionMultipleData - единственный поток команд и множество потоков данных). SIMD компьютер имеет Nидентичных синхронно работающих процессоров, N потоков данных и один поток команд. Каждый процессор обладает собственной локальной памятью. Сеть, соединяющая процессоры, обычно имеет регулярную топологию.
Аппаратная часть любого компьютера – это то, что можно увидеть внутри любого системного блока, монитора, сканера, принтера. т.п. К ней можно отнести важнейшую часть любого электронно-вычислительной машины – материнскую плату. Ведь именно на этой плате расположены разъемы для подключения таких составляющих, как оперативна память, графический адаптер, жесткий диск центральный процессор. В корпусе системного блока расположены так же устройства ввода информации: приводы для считывания информации с дисков, картридеры, которые дают возможность считывать информацию с flash-карты. Не стоит забывать и об устройстве, которое снабжает всю эту сложнейшую систему электроэнергией. Это устройство называется блоком питания. Важными элементами так же являются различные шлейфы, благодаря которым происходит соединение всех вышеперечисленных элементов в одно целое.
К аппаратному обеспечению можно отнести и внешние устройства ввода-вывода информации. Главным таким устройством является монитор, на котором в графическом виде отображается информация, благодаря которой пользователь компьютера может следить за состоянием выполнения поставленной задачи и состоянием машины в целом. Следующими устройствами можно считать клавиатуру, оптическая или лазерная мышь.
2.MPI_CART_COORDS()функциясын қолдану мысалы.
Дляопределениядекартовыхкоординатпроцессапоегорангу :intMPI_Card_coords(MPI_Commcomm,intrank,intndims,int *coords), где - comm – коммуникаторстопологиейрешетки, - rank - рангпроцесса, длякоторогоопределяютсядекартовыкоординаты, - ndims - размерностьрешетки, - coords- возвращаемыефункциейдекартовыкоординатыпроцесса.
MPI_Cart_coords(cartcomm, rank, 3, coords);
3.2 өлшемдіЛапластеңдеуін 2-өлшемді декомпозициятәсіліменпрограммалау.
Сурак
1.Есепті декомпозициялау және аймақты декомпозициялау тәсілі. Мысалдар.
Декомпозиция — это процесс разбиения задачи и ее решения на части. Существует три основных варианта декомпозиции: простая декомпозиция (trival), функциональная (functional) и декомпозиция данных. Тривиальная декомпозиция
Применяется она в том случае, когда различные копии линейного кода могут исполняться независимо друг от друга и не зависят от результатов, полученных в процессе счета других копий кода. Функциональная декомпозиция исходная задача разбивается на ряд последовательных действий, которые могут быть выполнены на различных узлах кластера, не зависимо от промежуточных результатов, но строго последовательно.Предположим наша задача сводится к применению некоего функционального оператора к большому массиву данных: S[i]=F(a[i]). Предположим также, что выполнение функции F над одним элементом массива занимает достаточно большое время и нам хотелось бы это время сократить. В этом случае мы можем попытаться представить исходную функцию как композицию нескольких функций: S(a[i])=I(H(R(a[i]).Произведя декомпозицию мы получим систему последовательных задач: x=r(a[i]);
y=h(x); b[i]=i(y); Каждая из этих задач может быть выполнена на отдельном узле кластера.
Декомпозиция данных
В отличие от функциональной декомпозиции, когда между процессорами распределяются различные задачи, декомпозиция данных предполагает выполнение на каждом процессоре одной и той же задачи, но над разными наборами данных. Части данных первоначально распределены между процессорами, которые обрабатывают их, после чего результаты суммируются некоторым образом в одном месте (обычно на консоли кластера).
2.MPI_Gather, MPI_scatter, MPI_allgather, MPI_alltoall, MPI_allreduce функциялары. Олардың айырмашылығы. Мысалдар.
Функция MPI_Gather производит сборку блоков данных, посылаемых всеми процессами группы, в один массив процесса с номером root. Длина блоков предполагается одинаковой. Объединение происходит в порядке увеличения номеров процессов-отправителей. intMPI_Gather(void* sendbuf, intsendcount, MPI_Datatypesendtype, void* recvbuf, intrecvcount, MPI_Datatyperecvtype,int root, MPI_Commcomm)
MPI_Commcomm;
int array[100];
int root, *rbuf; . . .
MPI_Comm_size(comm, &gsize);
rbuf = (int *) malloc( gsize * 100 * sizeof(int));
MPI_Gather(array, 100, MPI_INT, rbuf, 100, MPI_INT, root, comm);Функция MPI_Allgather выполняется так же, как MPI_Gather, но получателями являются все процессы группы. Данные, посланные процессом i из своего буфера sendbuf, помещаются в i-ю порцию буфера recvbuf каждого процесса. После завершения операции содержимое буферов приема recvbuf у всех процессов одинаково. intMPI_Allgather(void* sendbuf, intsendcount, MPI_Datatypesendtype, void* recvbuf, intrecvcount, MPI_Datatyperecvtype, MPI_Commcomm)Функция MPI_Gatherv позволяет собирать блоки с разным числом элементов от каждого процесса, так как количество элементов, принимаемых от каждого процесса, задается индивидуально с помощью массива recvcounts. intMPI_Gatherv(void* sendbuf, intsendcount, MPI_Datatypesendtype, void* rbuf, int *recvcounts, int *displs, MPI_Datatyperecvtype, int root, MPI_Commcomm) Функция MPI_Alltoall совмещает в себе операции Scatter и Gather и является по сути дела расширением операции Allgather, когда каждый процесс посылает различные данные разным получателям. Процесс i посылает j-ый блок своего буфера sendbuf процессу j, который помещает его в i-ый блок своего буфера recvbuf. intMPI_Alltoall(void* sendbuf, intsendcount, MPI_Datatypesendtype, void* recvbuf, intrecvcount, MPI_Datatyperecvtype, MPI_Commcomm)Функция MPI_Allreduceсохраняет результат редукции в адресном пространстве всех процессов, поэтому в списке параметров функции отсутствует идентификатор корневого процесса root. В остальном, набор параметров такой же, как и в предыдущей функции. intMPI_Allreduce(void* sendbuf, void* recvbuf, int count, MPI_Datatypedatatype, MPI_Op op, MPI_Commcomm)
3.Массивтемаксималсандыесептеупараллельдіпрограммасынжазыңыз.
int main(intargc,char **argv)
{ intsize,rank,i,n=12;
float a[]={10.0,-1.0,2.0,3.0,7.0,6.0,3.0,1.0,-2.0,4.0,-9.0,20.0};
MPI_Status status; MPI_Init(&argc,&argv);
MPI_Comm_rank(MPI_COMM_WORLD,&rank);
MPI_Comm_size(MPI_COMM_WORLD,&size);
float f=0,max=0,maxo=0;
intnachalo,konec,shag; shag=n/(size-1);
if(rank!=size-1) {
nachalo=rank*shag; konec=rank*shag+shag;
max=a[nachalo];
for(i=nachalo;i<konec;i++)
if(a[i]>max) max=a[i];
MPI_Send(&max,1,MPI_FLOAT,size-1,1,MPI_COMM_WORLD); }
if(rank==size-1){
maxo=-32000;
for(i=0;i<size-1;i++) { MPI_Recv(&max,1,MPI_FLOAT,i,1,MPI_COMM_WORLD,&status);
if(maxo<max)
maxo=max; }
printf("%f\n",maxo); } MPI_Finalize();}
Сурак