Запросы на модификацию данных
Лабораторная работа № 2. Язык запросов SQL.
Запросы на выборку.Системные функции.
Прежде всего, рассмотрим использование встроенных функций SQL Server. SQL Server содержит большое количество встроенных функций различного типа. Перечислим некоторые из них:
· Математические
· Статистические
· Строковые
· Даты времени
Полный перечень функций можно посмотреть в любой базе данных в ветке «ПрограммированиеàФункцииàСистемные функции»
Добавим вычисляемый столбец с ФИО сотрудника:
select
TitleOfCourtesy + LastName + ' ' + FirstName as FIO
from Employees
Результатом является новый столбец, составленный из значений нескольких полей. Еще больше возможностей дает использование строковых функций, например, преобразуем предыдущий запрос таким образом, чтобы в ФИО было только начальная буква имени. Для этого используем функцию LEFT(), которая возвращает определенное количество левых символов слова:
select
TitleOfCourtesy + LastName + ' ' + LEFT(FirstName, 1) + '.' as FIO
from Employees
Рассмотрим, например, возможность использовать для выборки всех заказов определенного года встроенную функцию YEAR(). Эта функция возвращает год от определенной даты. С учетом этого запрос можно переписать следующим образом:
select * from Orders
where YEAR(OrderDate) = 1998
Или перепишем этот же запрос с использованием другой функции DATEPART(), возвращающей определенную часть даты (год, месяц, день, день недели и т.п.):
select * from Orders
where DATEPART(yy, OrderDate) = 1998
Первый параметр – часть даты, второй – собственно дата
Таблица 1. Части даты
| Часть даты | Сокращения |
| year | yy, yyyy |
| quarter | qq, q |
| month | mm, m |
| dayofyear | dy, y |
| day | dd, d |
| week | wk, ww |
| weekday | dw |
| hour | hh |
| minute | mi, n |
| second | ss, s |
| millisecond | ms |
Рассмотрим еще несколько полезных функций из разных категорий:
select GETDATE() –- возвращает текущее системное время
select Region, ISNULL(Region, '---') from Employees – если первый параметр является NULL, то возвращается то, что указано вторым параметром
select
BirthDate, LastName + ' родился ' + CONVERT(VARCHAR(15), BirthDate, 104) AS [FB],
'ID = ' + CAST(EmployeeID as VARCHAR(3)) + ' F = ' + LastName AS [IdF]
from Employees
В последнем запросе используются две функции преобразования типов данных: CONVERT и CAST.
Первая функция CONVERT имеет 3 параметра: тип данных, в который производится преобразование; преобразуемое значение; необязательный параметр для преобразования даты в определенный формат.
Функция CAST принимает параметром преобразуемое значение и новый тип данных.
Помимо функций, использующих одиночное значение, в SQL Server есть еще статистические функции, которые используют множество значений для вычисления результата.
Например, получим различные характеристики по столбцам:
select
MIN(UnitPrice) as [Минимальная цена за единицу],
MAX(UnitPrice) as [Максимальная цена за единицу],
COUNT(*) as [Общее количество строк],
SUM(UnitPrice)
from [Order Details]
Группировка.
Запросы на группировку позволяют получать сводные данные по группе значений из столбцов, применяя к набору данных статистические функции.
Например, необходимо получить количество позиций в каждом заказе. Для этого необходимо знать, сколько строк соответствует каждому заказу в таблице [Order Details]. Наиболее очевидным решением является группировка по столбцу “OrderID” и получение количества строк с одинаковым идентификатором OrderID. В этом нам может помочь функция COUNT.
select OrderID, COUNT(*) as [Количество позиций в заказе]
from [Order Details]
GROUP BY OrderID
При группировке обязательно необходимо указывать столбцы, по которым осуществляется группировка с использованием ключевых слов ORDER BY, после которых необходимо перечислить столбцы, по которым осуществляется группировка.
Сгруппируем теперь по количеству товаров и узнаем, сколько товаров каждого вида было отпущено по заказам:
select ProductID, COUNT(*) as [Количество товаров]
from [Order Details]
GROUP BY ProductID
Обратите внимание, что в данном случае для группировки используется столбец ProductID.
select ProductID, MIN(UnitPrice) as [Минимальная цена товара]
from [Order Details]
GROUP BY ProductID
При использовании таких функций, как MIN, MAX, AVG, SUM параметрами для них являются конкретные столбцы или выражения, состоящие из констант, столбцов и т.д.
Можно использовать группировку и фильтр одновременно, например, найдем общую сумму выручки от товаров, на которые не было скидок:
select SUM(Quantity*UnitPrice)
from [Order Details]
WHERE Discount = 0
Или найдем сумму по чекам для товаров без скидок. В результирующий набор данных войдут только те товары, которые удовлетворяют условию WHERE:
select OrderID, SUM(Quantity*UnitPrice)
from [Order Details]
WHERE Discount = 0
GROUP BY OrderID
Обратите внимание на порядок следования ключевых слов и предложений – он имеет значение. Нельзя записывать их в произвольном порядке.
Задание.
1. Получить список кодов заказов и суммы по каждому заказу
2. Получить список кодов товаров и суммы по каждому товару
3. Получить список заказов и среднюю сумму заказа
4. Получить 5 самых прибыльных товаров
И последнее, что мы рассмотрим – это возможность фильтровать сгруппированные данные. Например, найдем те заказы, сумма по которым превышает заданную величину. Очевидно, что для этого необходимо воспользоваться уже созданным запросом, возвращающим коды заказов и сумму по заказам, но без заказов, на меньшую сумму. Нельзя фильтровать эти заказы в инструкции WHERE, но для этих целей существует специальная конструкция HAVING:
select OrderID, SUM(Quantity*UnitPrice)
from [Order Details]
GROUP BY OrderID
HAVING SUM(Quantity*UnitPrice) > 1000
Задание.
1. Получить список товаров, и сумму, которых было продано больше, чем на заданную сумму
2. Получить список товаров, которые были проданы со скидкой, которых было продано более чем 250 штук
Соединения.
Одной из особенностей реляционной модели данных является то, что в одной таблице должны храниться сведения об одной сущности, а таблицы связаны на основании общих столбцов: первичного ключа в главной таблице и внешнего ключа в подчиненной. Это накладывает определенные трудности при выборке данных из нескольких таблиц. Например, рассмотрим часть схемы данных для базы данных Northwind: регионы и территории.
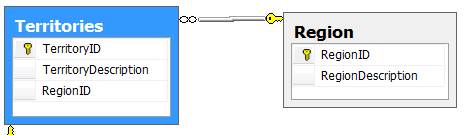
Очевидно, что записи в таблице Territories связаны с таблицей Region по общему столбцу RegionID. В этой схеме таблица Region является главной, а Territories – подчиненной. При этом связь осуществляется по столбцу-первичному ключу RegionID таблицы Region и внешнему ключу – столбцу RegionID таблицы Territories. В реальных приложениях пользователям намного проще иметь дело с символьными данными, чем с кодами, например, при формировании отчетов или при выводе данных. Если мы попробуем сделать запрос к таблице Territories, то вместо названий регионов мы увидим только коды этих регионов:
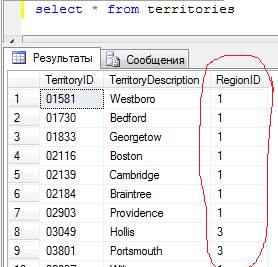
Намного нагляднее было бы видеть вместо кодов названия регионов, тем более, что они есть, просто содержатся в таблице Region. Для этого и используются соединения.
Существует несколько видов соединений:
1. Внутренние соединения INNER JOIN.
2. Внешние соединения: LEFT JOIN, RIGHT JOIN, FULL JOIN.
3. Перекрестные соединения.
Приведем выдержку из справки по MS SQL Server 2005:
· Внутренние соединения (типичные операции соединения, использующие такие операторы сравнения, как = или <>). Они включают эквивалентные соединения и естественные соединения.
Внутренние соединения используют оператор сравнения для установки соответствия строк из двух таблиц на основе значений общих столбцов в каждой таблице. Примером может быть получение всех строк, в которых идентификационный номер студента одинаковый как в таблице students, так и в таблице courses.
· Внешние соединения. Внешние соединения бывают левыми, правыми и полными.
Если внешние соединения задаются в предложении FROM, они указываются с одним из следующих наборов ключевых слов.
· LEFT JOIN или LEFT OUTER JOIN
Результирующий набор левого внешнего соединения включает все строки из левой таблицы, заданной в предложении LEFT OUTER, а не только те, в которых соединяемые столбцы соответствуют друг другу. Если строка в левой таблице не имеет совпадающей строки в правой таблице, результирующий набор строк содержит значения NULL для всех столбцов списка выбора из правой таблицы.
· RIGHT JOIN или RIGHT OUTER JOIN
Правое внешнее соединение является обратным для левого внешнего соединения. Возвращаются все строки правой таблицы. Для левой таблицы возвращаются значения NULL каждый раз, когда строка правой таблицы не имеет совпадающей строки в левой таблице.
· FULL JOIN или FULL OUTER JOIN
Полное внешнее соединение возвращает все строки из правой и левой таблицы. Каждый раз, когда строка не имеет соответствия в другой таблице, столбцы списка выбора другой таблицы содержат значения NULL. Если между таблицами имеется соответствие, вся строка результирующего набора содержит значения данных из базовых таблиц.
· Перекрестные с соединения
Перекрестное соединение возвращает все строки из левой таблицы. Каждая строка из левой таблицы соединяется со всеми строками из правой таблицы. Перекрестные соединения называются также декартовым произведением.
Напишем запрос, выполняющий нужную задачу, то есть возвращающий территории и названия регионов в одном результирующем наборе данных:
select * from Territories t
LEFT JOIN Region r ON t.RegionID = r.RegionID
В результате мы получим ВСЕ столбцы из таблицы Region и все столбцы из таблицы Territories. В данном случае все виды соединений, кроме перекрестного, вернут одинаковые наборы данных. Обратите внимание на использование псевдонимов для таблиц в рамках запросов. Чтобы не писать полные названия таблиц были использованы более краткие псевдонимы “t” и “r”. После ключевого слова ON необходимо написать условие, по которому осуществляется соединение таблиц: t.RegionID = r.RegionID. Условие соединения пишется вручную и может быть установлено между любыми столбцами с совместимыми типами данных, поэтому можно соединить таблицы в запросе по критерию, совершенно не имеющего физического смысла. Исправим запрос, убрав дублирующиеся столбцы следующим образом:
select t.*, RegionDescription from territories t left join
region r on t.RegionID = r.RegionID
В этом запросе выбираются все столбцы из таблицы t и столбец RegionDescription таблицы r. Необходимо помнить об одном существенном нюансе: если названия столбцов не дублируются в таблицах, то можно опустить название таблицы, но если дублируются, то обязательно указание таблицы, из которой берется значение. Например, следующий запрос вызывает ошибку:
select TerritoryID, TerritoryDescription, RegionID, RegionDescription
from territories t left join
region r on t.RegionID = r.RegionID
Сообщение 209, уровень 16, состояние 1, строка 1
Неоднозначное имя столбца "RegionID".
Ошибка возникает потому что в обеих таблицах существует столбец с названием RegionID и в списке столбцов необходимо явно указать таблицу, из которой он берется. Чтобы исправить ошибку, необходимо указать таблицу для столбца, например, так:
select TerritoryID, TerritoryDescription, t.RegionID, RegionDescription
from territories t left join
region r on t.RegionID = r.RegionID
Разные виды запросов можно соединять в один с помощью соединений, например, используем соединения совместно с группировкой. Построим запрос, возвращающий суммарное количество проданного товара, с указанием его названия:
select d.ProductID, ProductName, SUM(Quantity)
from [Order Details] d left join
[Products] p on p.ProductID = d.ProductID
group by d.ProductID, ProductName
Приведем еще несколько примеров запросов с соединениями:
1.
select * from Territories t
INNER JOIN Region r ON t.RegionID = r.RegionID
where RegionDescription = 'Northern'
2.
select * from Territories t
INNER JOIN Region r ON t.RegionID = r.RegionID
where RegionDescription = 'Northern' and TerritoryDescription LIKE 'P%'
3.
select * from Orders o
left join [Order Details] d on o.OrderID = d.OrderID
left join [Products] p on p.ProductID = d.ProductID
where CategoryID = 4
Задание.
1. Получить список названий товаров, с указанием суммы, на которую этот товар был продан.
2. Получить список заказов, сделанных в марте 1998 года с указанием ФИО продавца, оформившего заказ, в формате «Фамилия Имя».
3. Получить список заказов, оформленных продавцами из Лондона.
4. Получить список заказов, оформленных продавцами из Лондона и Сиэтла в январе 1998 года.
Запросы на модификацию данных.
С помощью языка SQL можно не только создавать запросы на выборку данных, но также и на модификацию: добавление, обновление и удаление. Для этого используются команды INSERT, UPDATE, DELETE.
Команда INSERT предназначена для добавления записей в таблицы. Синтаксис команды следующий: INSERT INTO <Table_Name> (<columns>) VALUES (<values>).
Для примера добавим в таблицу Categories новую категорию товаров:
INSERT INTO Categories (CategoryName, [Description])
VALUES ('Новая категория', 'Описание новой категории')
Убедитесь, что новая запись добавилась. При добавлении с помощью команды INSERT следует помнить о следующих особенностях: в списке столбцов обязательно должны присутствовать все столбцы, которые не допускают значения NULL (если они не содержат определения DEFAULT); идентифицирующие столбцы не могут быть в списке столбцов. В приведенном примере столбец CategoryID является идентифицирующим, поэтому он не может быть вставлен просто с использованием команды INSERT.
Команда UPDATE позволяет модифицировать данные. В предложении WHERE указывается условие обновления. Внимание! Если предложение WHERE отсутствует, то будут обновлены ВСЕ строчки в таблице!
Например, модифицируем добавленную категорию и присвоим ей новое название «Обновленная категория», для значения идентификатора необходимо подставить реальное значение из таблицы:
UPDATE Categories SET CategoryName = 'Обновленная категория'
WHERE CategoryID = 9
Обновлять можно множество столбцов за один раз:
UPDATE Categories SET CategoryName = 'Совсем новая категория',
CategoryDescription = 'Описание для совсем новой категории'
WHERE CategoryID = 9
Удаление производится с помощью команды DELETE. В предложении WHERE указывается условие обновления строк. Удалим для примера вновь созданную категорию:
DELETE FROM Categories WHERE CategoryID = 9