Объектно- ориентированные модели данных
Иерархические базы данных. В этой модели имеется один главный объект (корень) и остальные - подчиненные - объекты, находящиеся на разных уровнях иерархии. Взаимосвязи объектов образуют иерархическое дерево с одним корневым объектом.
Иерархическая БД состоит из упорядоченного набора нескольких экземпляров одного типа дерева. Автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя
Пример:
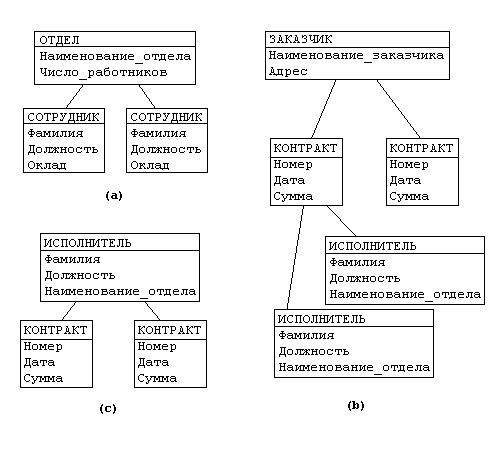
Рассмотрим следующую модель данных предприятия (см. рис. 3.1): предприятие состоит из отделов, в которых работают сотрудники. В каждом отделе может работать несколько сотрудников, но сотрудник не может работать более чем в одном отделе.
Поэтому, для информационной системы управления персоналом необходимо создать групповое отношение, состоящее из родительской записи ОТДЕЛ (НАИМЕНОВАНИЕ_ОТДЕЛА, ЧИСЛО_РАБОТНИКОВ) и дочерней записи СОТРУДНИК (ФАМИЛИЯ, ДОЛЖНОСТЬ, ОКЛАД). Это отношение показано на рис. (а) (Для простоты полагается, что имеются только две дочерние записи).
Для автоматизации учета контрактов с заказчиками необходимо создание еще одной иерархической структуры : заказчик - контракты с ним - сотрудники, задействованные в работе над контрактом. Это дерево будет включать записи ЗАКАЗЧИК(НАИМЕНОВАНИЕ_ЗАКАЗЧИКА, АДРЕС), КОНТРАКТ(НОМЕР, ДАТА,СУММА), ИСПОЛНИТЕЛЬ (ФАМИЛИЯ, ДОЛЖНОСТЬ, НАИМЕНОВАНИЕ_ОТДЕЛА) (рис. (b)).
Операции над данными, определенные в иерархической модели:
- ДОБАВИТЬ в базу данных новую запись. Для корневой записи обязательно формирование значения ключа.
- ИЗМЕНИТЬ значение данных предварительно извлеченной записи. Ключевые данные не должны подвергаться изменениям.
- УДАЛИТЬ некоторую запись и все подчиненные ей записи.
- ИЗВЛЕЧЬ:
- извлечь корневую запись по ключевому значению, допускается также последовательный просмотр корневых записей
- извлечь следующую запись (следующая запись извлекается в порядке левостороннего обхода дерева)
В операции ИЗВЛЕЧЬ допускается задание условий выборки (например, извлечь сотрудников с окладом более 1 тысячи руб.)
«+»
¡ Эффективное использование памяти ЭВМ
¡ Неплохие показатели времени выполнения операций над данными
«-»
¡ Громоздкость для обработки информации с достаточно сложными логическими связями.
Сложность понимания для обычного пользователя
2)Сетевая модель данных. Основные операции. Достоинства и недостатки
Сетевые базы даны. Сетевой подход к организации данных является расширением иерархического. В иерархических структурах запись-потомок должна иметь в точности одного предка; в сетевой структуре данных потомок может иметь любое число предков.
В сетевой модели данных любой объект может быть одновременно и главным, и подчиненным, и может участвовать в образовании любого числа взаимосвязей с другими объектами. Сетевая БД состоит из набора записей и набора связей между этими записями, а если говорить более точно - из набора экземпляров каждого типа из заданного в схеме БД набора типов записи и набора экземпляров каждого типа из заданного набора типов связи
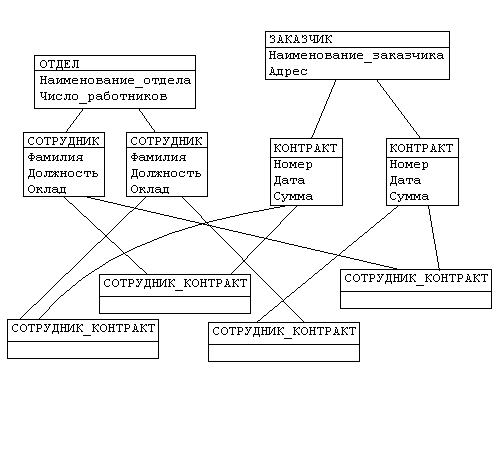
Иерархическая структура из п.3.1. преобразовывается в сетевую следующим образом (см. рис. 3.2):
- древья (a) и (b), показанные на рис. 3.1, заменяются одной сетевой структурой, в которой запись СОТРУДНИК входит в два групповых отношения;
- для отображения типа M:N вводится запись СОТРУДНИК_КОНТРАКТ, которая не имеет полей и служит только для связи записей КОНТРАКТ и СОТРУДНИК, см. рис. 3.2.(Отметим, что в этой записи может храниться и полезная информация, например, доля данного сотрудника в общем вознаграждении по данному контракту.)
Операции над данными.
- ДОБАВИТЬ - внести запись в БД и, в зависимости от режима включения, либо включить ее в групповое отношение, где она объявлена подчиненной, либо не включать ни в какое групповое отношение.
- ВКЛЮЧИТЬ В ГРУППОВОЕ ОТНОШЕНИЕ - связать существующую подчиненную запись с записью-владельцем.
- ПЕРЕКЛЮЧИТЬ - связать существующую подчиненную запись с другой записью-владельцем в том же групповом отношении.
- ОБНОВИТЬ - изменить значение элементов предварительно извлеченной записи.
- ИЗВЛЕЧЬ - извлечь записи последовательно по значению ключа, а также используя групповые отношения - от владельца можно перейти к записям - членам, а от подчиненной записи к владельцу набора.
- УДАЛИТЬ - убрать из БД запись. Если эта запись является владельцем группового отношения, то анализируется класс членства подчиненных записей. Обязательные члены должны быть предварительно исключены из группового отношения, фиксированные удалены вместе с владельцем, необязательные останутся в БД.
- ИСКЛЮЧИТЬ ИЗ ГРУППОВОГО ОТНОШЕНИЯ - разорвать связь между записью-владельцем и записью-членом.
«+»
¡ Возможность эффективной реализации по затратам памяти и оперативности обработки
«-»
¡ Сложность и жесткость БД
¡ Понижен контроль целостности данных
3)Реляционная и постреляционная модели данных. Основные операции. Достоинства и недостатки.
Реляционная модель использует представление данных в виде таблиц (реляций, связей). В ее основе лежит математическое понятие теоретико-множественного отношения: она базируется на реляционной алгебре и теории отношений.
Отношения удобно представлять в виде таблиц. На рис. 4.1 представлена таблица (отношение степени 5), содержащая некоторые сведения о работниках гипотетического предприятия. Строки таблицы соответствуют кортежам. Каждая строка фактически представляет собой описание одного объекта реального мира (в данном случае работника), характеристики которого содержатся в столбцах. Можно провести аналогию между элементами реляционной модели данных и элементами модели "сущность-связь". Реляционные отношения соответствуют наборам сущностей, а кортежи - сущностям. Поэтому, также как и в модели "сущность-связь" столбцы в таблице, представляющей реляционное отношение, называют атрибутами.

Постреляционная модель данных представляет собой расширенную реляционную модель, в которой отменено требование атомарности атрибутов. Поэтому постреляционную модель называют "не первой нормальной формой" (NF2) или "многомерной базой данных". Она использует трехмерные структуры, позволяя хранить в полях таблицы другие таблицы. Тем самым расширяются возможности по описанию сложных объектов реального мира. В качестве языка запросов используется несколько расширенный SQL, позволяющий извлекать сложные объекты из одной таблицы без операций соединения.
1. на примере информации о накладных и товарах для сравнения приведено представление одних и тех же данных с помощью реляционной (а) и постреляционной (б) моделей. Из рисунка видно, что по сравнению с реляционной моделью в постреляционной модели данные хранятся более эффективно, а при обработке не потребуется выполнять операцию соединения данных из двух таблиц.
2. а)
3. Накладные Накладные-товары
| N накладной | Покупатель | N накладной | Товар | Количество | |
| Сыр | |||||
| Рыба | |||||
| Лимонад | |||||
| Сок | |||||
| Печенье | |||||
| Йогурт |
4. б)
5. Накладные
| N накладной | Покупатель | Товар | Количество |
| Сыр | |||
| Рыба | |||
| Лимонад | |||
| Сок | |||
| Печенье | |||
| Йогурт |
6. Рис. 2.6. Структуры данных реляционной и постреляционной моделей
«+»
¡ простота работы и отражение представлений пользователя
¡ гибкость (соединение, разделение файлов)
¡ простота внедрения плоских файлов
¡ отделение от физической реализации (независимость)
¡ произвольная структура запросов
¡ хорошее теоретическое обоснование
«-»
¡ низкая производительность
¡ возможность логических ошибок и необходимость осторожной работы с моделью
¡ линейность структуры таблиц
4)Многомерная и объектно-ориентированная модели. Достоинства и недостатки.
Многомерные СУБД являются узкоспециализированными СУБД. Многомерные системы позволяют оперативно обрабатывать информацию для проведения анализа и принятия решений. Их называют OLAP – системы (Online Analitical Processing – оперативная аналитическая обработка)
Основные понятия, используемые в этих СУБД: агрегируемость, историчность и прогнозируемость данных. По сравнению с реляционной моделью (OLTP – системы оперативной обработки) многомерная организация данных обладает более высокой наглядностью и информативностью
Пример 3-х мерной модели.
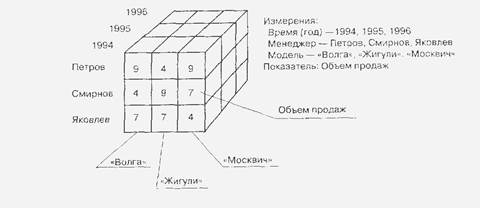
N – мерные модели представляются в виде поликуба или гиперкуба. Примером поликубической схемы данных является Oracle Express Server
Основным достоинством многомерной модели данных является удобство и эффективность аналитической обработки больших объемов данных, связанных со временем. При организации обработки аналогичных данных на основе реляционной модели происходит нелинейный рост трудоемкости операций в зависимости от размерности БД и существенное увеличение затрат оперативной памяти на индексацию.
Недостатком многомерной модели данных является ее громоздкость для простейших задач обычной оперативной обработки информации.
Объектно- ориентированные модели данных
В объектно-ориентированной модели используются понятия класса, объекта, метода.
В этой модели при представлении данных имеется возможность идентифицировать отдельные записи базы. Между записями базы данных и функциями их обработки устанавливаются взаимосвязи с помощью механизмов, подобных соответствующим средствам в объектно-ориентированных языках программирования.
В ООБД любая сущность является объектом и обрабатывается как объект. Табличная, в виде строк и столбцов, организация реляционной базы данных заменяется ее организацией в виде коллекции объектов В общем случае коллекция объектов сама является объектом и обрабатывается также, как и другие объекты.
ООБД
Хорошо подходят для приложений со сложными типами данных, напр., программ компьютерного моделирования или программ разработки составных документов, объединяющих текст, графику и электронные таблицы. Такие базы данных естественным образом отражают иерархию разнородных данных. Напр.. весь документ может быть представлен как один объект, состоящий из мелких объектов (глав), которые, в свою очередь, состоят из еще более мелких объектов (тем,параграфов)
«-» ООБДНизкая скорость выполнения запросов, понятийная сложность.
5) Элементы реляционной модели данных
Реляционная база данных является организованной на машинном носителе совокупностью взаимосвязанных данных и содержит сведения о различных сущностях одной предметной области — реальных объектах, процессах, событиях или явлениях. Реляционная база данных представляет собой множество взаимосвязанных двумерных таблиц, в каждой из которых содержатся сведения об одной сущности.
Структура реляционной таблицы определяется составом и последовательностью полей, соответствующих ее столбцам, с указанием типа элементарного данного, размещаемого в поле. Каждое поле отражает определенную характеристику сущности, а соответствующий столбец содержит данные одного типа.
Содержание реляционной таблицы заключено в ее строках. Каждая строка таблицы содержит данные о конкретном экземпляре сущности и называется записью. для однозначного определения каждой записи таблица должна иметь уникальный ключ (первичньгй ключ). Этот ключ может состоять из одного или нескольких полей. По значению ключа отыскивается единственная запись.
Связи между таблицами базы данных дают возможность совместно использовать данные из разных таблиц. В нормализованной реляционной базе данных связи характеризуются отношениями типа один-к-одному (1:1) или один-ко-многим (1 :М). Связь каждой пары таблиц обеспечивается одинаковыми полями в них - ключом связи. Ключом связи всегда является уникальный ключ главной таблицы в связи. В подчиненной таблице он называется внешним ключом.

Основные понятия РБД
Сущность есть объект любой природы, данные о котором хранятся в базе данных. Данные о сущности хранятся в отношении.
Атрибуты представляют собой свойства, характеризующие сущность. В структуре таблицы каждый атрибут именуется и ему соответствует заголовок некоторого столбца таблицы.

Домен представляет собой множество всех возможных значений определенного атрибута отношения.
Каждому кортежу соответствует строка отношения
Схема отношения представляет собой список имен атрибутов
Множество кортежей отношения часто называют содержимым (телом) отношения.
Первичным ключом (ключом отношения, ключевым атрибутом) называется атрибут отношения, однозначно идентифицирующий каждый из его кортежей.
Ключ может быть составным (сложным), то есть состоять из нескольких атрибутов или простым. Простой ключ может быть естественным или искусственным (суррогатным). Суррогатный ключ создается СУБД или пользователем и не содержит никакой информации. Используется для создания уникальных идентификаторов строк. Такой ключ часто используют вместо составного ключа, и он не зависит от предметной области, для которой создается БД, поэтому не возникает необходимости в его изменении при изменчивости предметной области
Ключи обычно используют для достижения следующих целей:
1)исключения дублирования значений в ключевых атрибутах (остальные атрибуты в расчет не принимаются);
2)упорядочения кортежей. Возможно упорядочение по возрастанию или убыванию значений всех ключевых атрибутов, а также смешанное упорядочение (по одним — возрастание, а по другим — убывание);
3)ускорения работы с кортежами отношения
4) организации связывания таблиц
В реляционной модели данные представляются в виде совокупности взаимосвязанных таблиц
6)Контроль целостности баз данных. Условия добавления, изменения и изменения записей для обеспечения целостности базы.
Чтобы информация, хранящаяся в базе данных, была однозначной и непротиворечивой, в реляционной модели устанавливаются некоторые ограничительные условия. Ограничительные условия - это правила, определяющие возможные значения данных. Они обеспечивают логическую основу для поддержания корректных значений данных в базе. Такие ограничения целостности позволяют свести к минимуму ошибки, возникающие при обновлении и обработке данных.
Важнейшими ограничениями целостности данных являются:
¡ категорийная целостность
¡ ссылочная целостность.
Ограничение категорийной целостности заключается в следующем.
Ни одна строка не может быть занесена в базу данных до тех пор, пока не будут определены все атрибуты ее первичного ключа. Это правило называется правилом категорийной целостности и кратко формулируется следующим образом: никакой атрибут первичного ключа строки не может быть пустым.
Ссылочная целостность:
Если две таблицы связаны между собой, то внешний ключ таблицы должен содержать только значения, уже имеющиеся среди значений ключа, по которому осуществляется связь. Если корректность значений внешних ключей не контролируется СУБД,то может нарушиться ссылочная целостность данных. Например: пусть имеются две связанные таблицы СТУДЕНТ и УСПЕВАЕМОСТЬ, которые связаны по полю номер студента. Если удалить из таблицы СТУДЕНТ строку (например, при отчислении студента), имеющую хотя бы одну связанную-с ней строку в таблице УСПЕВАЕМОСТЬ, то это приведет к тому, что в таблице УСПЕВАЕМОСТЬ останутся записи об успеваемости студента, который уже отчислен. Целостность данных будет нарушена и в случае ошибочного ввода в поле внешнего ключа НС (номер студента) подчиненной таблицы УСПЕВАЕМОСТЬ сведений о студенте, запись о котором отсутствует в главной таблице СТУДЕНТ.
Ограничения категорийной и ссылочной целостности должны поддерживаться СУБД . Для соблюдения целостности таблицы достаточно гарантировать отсутствие в любой таблице полей с одним и тем же значением первичного ключа.
Обеспечить ссылочную целостность БД несколько сложнее. При обновлении ссылающегося отношения (при вводе новых кортежей или модификации значения внешнего ключа в существующих кортежах) достаточно следить за тем, чтобы не появлялись некорректные значения внешнего ключа. А вот при удалении кортежа из отношения, на которое имеется ссылка, можно использовать один из трех подходов, обеспечивающих ссылочную целостность:
¡ запрещается производить удаление кортежа, на который существуют ссылки, нужно сначала либо удалить ссылающиеся кортежи, либо соответствующим образом изменить значения их внешнего ключа;
¡ при удалении кортежа, на который имеются ссылки, во всех ссылающихся кортежах значение внешнего ключа должно автоматически становиться неопределенным;
¡ при удалении кортежа из отношения, на которое ведет ссылка, из ссылающегося отношения должны автоматически удаляться все ссылающиеся кортежи (это называется каскадным удалением).
В реляционных СУБД обычно можно выбрать способ поддержания ссылочной целостности для каждой отдельной ситуации определения внешнего ключа, но для принятия такого решения необходимо анализировать требования конкретной прикладной области.
Критерии целостности:
¡ Каждой записи основной (главной, родительской) таблицы соответствует нуль или более записей дополнительной (подчинённой, дочерней) таблицы.
¡ В дополнительной таблице нет записей, которые не имеют родительских записей в основной таблице.
Каждая запись дополнительной таблицы имеет только одну родительскую запись основной таблицы
7)Операции реляционной алгебры объединение, пересечение, вычитание и произведение
Объединение

Результатом объединения отношений A и B будет отношение с тем же заголовком, что и у совместимых по типу отношений A и B, и телом, состоящим из кортежей, принадлежащих или A, или B, или обоим отношениям.
Пример
Пусть даны следующие соотношения:
Персоны
| Имя | Возраст | Вес |
| Гарри | ||
| Салли | ||
| Джордж | ||
| Елена | ||
| Питер |
Персонажи
| Имя | Возраст | Вес |
| Свихнувшийся | ||
| Дональд | ||
| Скряга |
Результат объединения:
| Имя | Возраст | Вес |
| Гарри | ||
| Салли | ||
| Джордж | ||
| Елена | ||
| Питер | ||
| Свихнувшийся | ||
| Дональд | ||
| Скряга |
Эквивалентный SQL-запрос:
ВЫБОР Имя, Возраст, Вес FROM Персоны UNION SELECT, Имя, Возраст, Вес FROM ПерсонажиПересечение

Результатом пересечения отношений A и B будет отношение с тем же заголовком, что и у отношений A и B, и телом, состоящим из кортежей, принадлежащих одновременно обоим отношениям и B.
Пример
Пусть даны следующие соотношения:
Персоны
| Имя | Возраст | Вес |
| Гарри | ||
| Салли | ||
| Джордж | ||
| Елена | ||
| Питер |
Персонажи
| Имя | Возраст | Вес |
| Свихнувшийся | ||
| Джордж | ||
| Дональд | ||
| Скряга | ||
| Салли |
Результат пересечения:
| Имя | Возраст | Вес |
| Джордж | ||
| Салли |
Эквивалентный SQL-запрос:
ВЫБОР Имя, Возраст, Вес FROM Персоны INTERSECT SELECT, Имя, Возраст, Вес FROM Персонажи
Ключевое слово INTERSECT может отсутствовать в некоторых СУБД, однако оно включено в стандарт [ 5 ].
Разность

Результатом разности отношений A и B будет отношение с тем же заголовком, что и у совместимых по типу отношений A и B, и телом, состоящим из кортежей, принадлежащих отношению и не принадлежащих отношению B.
Пример
Пусть даны следующие соотношения:
Персоны
| Имя | Возраст | Вес |
| Гарри | ||
| Салли | ||
| Джордж | ||
| Елена | ||
| Питер |
Персонажи
| Имя | Возраст | Вес |
| Свихнувшийся | ||
| Джордж | ||
| Дональд | ||
| Скряга | ||
| Салли |
Результат разности:
| Имя | Возраст | Вес |
| Гарри | ||
| Елена | ||
| Питер |
Эквивалентный SQL-запрос:
ВЫБОР Имя, Возраст, Вес FROM Персоны КРОМЕ SELECT, Имя, Возраст, Вес FROM ПерсонажиПроизведение
ПРИ выполнении прямого произведения двух отношений производится Отношение, кортежи которого являются конкатенацией (сцеплением) кортежей первого и второго операндов.
Пример
Пусть даны следующие соотношения:
Мульфильмы
| Код_мульта | Название_мульта |
| The Simpsons | |
| Family Guy | |
| Duck Tales |
Каналы
| Код_канала | Название_канала |
| СТС | |
| 2х2 |
Результат произведения:
| Код_мульта | Название_мульта | Код_канала | Название_канала |
| The Simpsons | СТС | ||
| The Simpsons | 2х2 | ||
| Family Guy | СТС | ||
| Family Guy | 2х2 | ||
| Duck Tales | СТС | ||
| Duck Tales | 2х2 |
Эквивалентный SQL-запрос:
ВЫБОР * FROM Мультфильмы, Каналы8)Операции реляционной алгебры выборка, проекция, деление и соединение.
Выборка
Операция выборки - унарный оператор, записываемый как σ aθb (R) или σ aθv (R), где:
- а, б - имена атрибутов
- θ - оператор сравнения из множества {<, ≤, =, ≥,>}
- V - константа
- R - отношение (в оригинале - отношения, однако как видно из примера, подразумевается не столько взаимосвязь таблиц, скольковзаимосвязь / соотношение различных фактов В рядах этих таблиц).
Выборка σ aθb (R) (или σ aθv (R)) выбирает все наборы значений R, для которых функция θ B (или θ V) будет истинна.
Пример
Пусть даны следующие соотношения:
Персоны
| Имя | Возраст | Вес |
| Гарри | ||
| Салли | ||
| Джордж | ||
| Елена | ||
| Питер |
Тогда результаты выборок будут следующими:
а Возраст ≥ 34 (Персоны)
| Имя | Возраст | Вес |
| Гарри | ||
| Елена | ||
| Питер |
Эквивалентный SQL-запрос:
ВЫБОР * FROM Персоны ГДЕ Возраст> = 34а Возраст = Вес (Персоны)
| Имя | Возраст | Вес |
| Елена |
Эквивалентный SQL-запрос:
ВЫБОР * FROM Персоны ГДЕ Возраст Вес =
Проекция
Операция выборки - унарный оператор, записываемый как π a1, ..., (R) где 1 , ..., N - спиоск полей, подлежащих выборке. Результатом такой выборки будет набор последовательностей значений отношения R, в котором будут присутствовать только поля, перечисленные в списке 1 , ..., N с естественным уничтожением потенциально возникающих кортежей-дубликатов [ 4 ].
Пример
Пусть даны следующие соотношения:
Персоны
| Имя | Возраст | Вес |
| Гарри | ||
| Салли | ||
| Джордж | ||
| Елена | ||
| Питер |
Результат проекции:
я Возраст, Вес (Персоны)
| Возраст | Вес |
Эквивалентный SQL-запрос:
ВЫБОР DISTINCT Возраст, Вес FROM Персоны
Деление
Реляционное деление достаточно нетривиально описать, но на примере его смысл нагляден. В целом, из таблицы берутся значения строк, для которых присутствуют все комбинации значений из таблицы B. Понятно? Ну, примерно об этом я и пытался сказать, смотрим пример:
Пример
Пусть даны следующие соотношения:
Мульфильмы
| Код_мульта | Название_мульта | Название_канала |
| The Simpsons | RenTV | |
| The Simpsons | 2х2 | |
| The Simpsons | CTC | |
| Family Guy | RenTV | |
| Family Guy | 2х2 | |
| Duck Tales | СТС | |
| Duck Tales | 2x2 |
Тогда при делении на таблицу каналов:
Каналы
| Название_канала |
| RenTV |
| 2х2 |
Результатом будет:
| Код_мульта | Название_мульта |
| The Simpsons | |
| Family Guy |
Family Guy и The Simpsons - мультфильмы, которые показывались и на RenTV и на 2x2 (условие во второй таблице). При этом Duck Talesне показывалось по RenTV, потому был исключён из результирующей таблицы.
Эквивалентный SQL-запрос привести затрудняюсь
Соединение
Операция соединения есть результат последовательного применения операций декартового произведения и выборки. Если в отношениях и имеются атрибуты с одинаковыми наименованиями, то перед выполнением соединения такие атрибуты необходимо переименовать. [ 4 ]
Пример
Мульфильмы
| Код_мульта | Название_мульта | Название_канала |
| The Simpsons | 2х2 | |
| Family Guy | 2х2 | |
| Duck Tales | RenTV |
Каналы
| Код_канала | Частота |
| RenTV | 3,1415 |
| 2х2 | 783,25 |
Соединим ИХ с выборкой а Название_канала = Код_канала (Произведение)
Первый этап, произведение:
| Код_мульта | Название_мульта | Название_канала | Код_канала | Частота |
| The Simpsons | 2х2 | RenTV | 3,1415 | |
| The Simpsons | 2х2 | 2х2 | 783,25 | |
| Family Guy | 2х2 | RenTV | 3,1415 | |
| Family Guy | 2х2 | 2х2 | 783,25 | |
| Duck Tales | RenTV | RenTV | 3,1415 | |
| Duck Tales | RenTV | 2х2 | 783,25 |
Второй этап, а выборка Название_канала = Код_канала (Произведение):
| Код_мульта | Название_мульта | Название_канала | Код_канала | Частота |
| The Simpsons | 2х2 | 2х2 | 783,25 | |
| Family Guy | 2х2 | 2х2 | 783,25 | |
| Duck Tales | RenTV | RenTV | 3,1415 |
Эквивалентный SQL-запрос:
ВЫБОР * FROM Мультфильмы, Каналы ГДЕ Название _ канала = Код _ канала9)Операторы SQL для создания, модификации и удаления баз данных и таблиц.
Операторы базы данных