Поиск в индексно-последовательном файле
Методы поиска данных в физической памяти.
Способы адресации данных.
Адресацией данных называется алгоритм, позволяющий по описанию набора данных, найти физический адрес записи. Описание элемента данных называется ключом поиска. Ключ поиска может быть простым или составным, например, книгу в библиотеке, можно найти по различным ее описания, типа, Ф.И.О. автора, название, издательство, ISBN-номер и т.д. Ключ поиска может быть уникальным, либо описывать группу записей, удовлетворяющих этому описанию (например, номенклатура деталей, относящаяся к шасси автомобиля). Если таблица БД сортирована по ключу поиска, то такой ключ называется первичным. Например, если данные о сотрудниках сортированы по фамилиям, а ищется запись, содержащая данные об Иванове П.И.
Рассмотрим различные способы адресации данных:
1. Последовательное сканирование файла.
Наиболее простым способом поиска является последовательный просмотр всего файла с проверкой ключа каждой записи. Этот способ требует, однако, много времени, и не применим в большинстве случаев.
Блочный поиск.
Если записи упорядочены по ключу, то при сканировании файла нет необходимости просматривать каждую запись. Можно, например, просматривать каждую сотую запись, пока не найдется блок, содержащий требуемую запись. Внутри блока можно применить последовательный просмотр записей. Подсчитаем оптимальный размер блока:
Пусть N количество записей в БД, а x – количество блоков. Тогда, каждый блок должен содержать y=N/x записей. Для локализации нужной записи требуется, в среднем, просмотреть x/2 блоков для нахождения номера блока, затем в ходе последовательно сканирования просмотреть y/2 записей. Поэтому, общее число элементарных операций равно 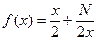 . Вычислив производную этой функции и приравняв ее к нулю, получим, что минимум этой функции достигается при x=N (квадратный корень из N). Таким образом, размер блока при общем количестве записей, равном 10 000, должен быть равен 100.
. Вычислив производную этой функции и приравняв ее к нулю, получим, что минимум этой функции достигается при x=N (квадратный корень из N). Таким образом, размер блока при общем количестве записей, равном 10 000, должен быть равен 100.
Двоичный поиск.
Этот способ применим в упорядоченном файле. Файл делится пополам и выбирается запись из середины. Ее ключ сравнивается с ключом поиска и определяется, в какой половине находится нужная нам запись. Затем та же операция повторятся с половиной файла. Деление пополам производится до тех пор, пока не будет локализована требуемая запись. Легко подсчитать, что среднее число операций при таком способе поиска равно двоичному логарифму от числа записей в БД.
Этот способ неэффективен при поиске в файле, находящемся на диске с прямым доступом, поскольку, тратится много времени на перемещение механизма доступа, поэтому он применим только при поиске в оперативной памяти.
Частным случаем двоичного поиска является поиск в бинарном дереве, когда цепочка указателей управляет направлением поиска. Такой поиск применяется, в основном, при поиске в индексе.
Поиск в индексно-последовательном файле.
При такой организации данные упорядочиваются по основному ключу, однако, вместо поиска по основному файлу применяют поиск в индексном файле. Индексный файл представляет, попросту говоря, таблицу, состоящую из двух столбцов. Первый столбец содержит значения ключа БД, упорядоченные по возрастанию, а второй – физический адрес записи с данным ключом. Иногда вместо физического адреса записи во второй столбец индексного файла помещается номер записи или смещение записи относительно начала файла, т.е. данные которые могут локализовать требуемую запись. Поскольку, записи БД сортированы, то нет необходимости помещать в индексный файл ссылки на каждую запись БД, а можно ограничиться выборочными ссылками, например, на блоки фамилий, начинающихся на буквы А, Б,В.
В случае больших индексных файлов последние можно также индексировать, получая индексы второго уровня, от них можно строить индексы третьего уровня и т.д.
5. Поиск в индексно - произвольном файле.
Произвольный (неупорядоченный) файл можно также индексировать, однако, в этом случае, необходимо делать ссылки на каждую запись БД. Такой индекс может использоваться в индексно-последовательном файле для поиска по вторичным ключам.
При работе с файлами используют два основных вида обработки: последовательная обработка, при которой записи обрабатываются в последовательности их размещения на запоминающем устройстве; произвольная обработка, при которой записи обрабатываются в произвольной последовательности. В зависимости от того, какой режим работы преобладает выбирают способ организации данных. Если записи неупорядочены, то можно добавлять записи, не заботясь о сохранении порядка. Однако, индексные файла в этом случае содержат ссылки на каждую запись данных, и размер индекса существенно больше, чем в случае последовательной организации. При последовательном расположении данных больше времени тратится на операцию включения новых записей. Эта операция становится более эффективной, если файл данных заполняется с пропусками, предназначенными для будущего включения новых записей. Метод, основанный на включении пропусков в файл данных, называется методом распределенной свободной памяти. Хотя применение этого метода позволяет избежать записей переполнения, необходимо время о времени производить операции реорганизации файла с целью восстановления резервных позиций.
Другой способ обработки новых записей основан на выделении специальной области, называемой областью переполнения. Новая запись помещается в эту область, а в основной области помещается ссылка а ее адрес. Если включается группа новых записей, то они упорядочиваются в линейную цепь (кольцо), в которой каждая запись содержит ссылку на последующую, а последняя запись не содержит ссылки, либо содержит ссылку на первый элемент (голову) списка. При поиске записи сначала производится поиск в основной области, а затем поиск в области переполнения по цепочке указателей. Такой метод называется методом выделенной области переполнения.
При одновременном использовании областей переполнения и свободной распределенной памяти встает вопрос: на каком уровне индексного дерева распределять свободную память? Если свободная память распределена на нижнем уровне, то при включении элементов их перестройка происходит на этом уровне. Расход памяти для организации индекса может быть меньше в том случае, когда свободная память распределена на уровне 2. Однако при поиске в наборе указателей увеличиваются скачки между последовательными элементами индекса. Если эти скачки не выходят за пределы цилиндра, т.е. не влекут дополнительного перемещения головок чтения-записи, то они не доставляют много хлопот и размещение на втором уровне в этом случае лучше размещения на первом. Свободную память можно передавать на более высокие уровни индексного дерева или совсем не использовать, заменяя ее областью переполнения. Все зависит от того, какой способ потребует меньше передвижения головок чтения-записи и что важнее экономить – память или время.