Пример проектирования структры ХД
Лабораторная работа №1
Хранилища данных
Цель: ознакомиться с особенностями хранилищ данных и кубов данных, приобрести практику работы в среде Deductor.
Теоретические сведения:
Сегодня, практически в любой организации сложилась хорошо всем знакомая ситуация: информация вроде бы, где-то и есть, её даже слишком много, но она неструктурированна, несогласованна, разрознена, не всегда достоверна, её практически невозможно найти и получить.
Именно на разрешение этого противоречия - отсутствие информации при наличии и даже избытке и нацелена концепция Хранилищ Данных (Data Warehouse). В основе концепции Хранилищ Данных лежат две основополагающие идеи:
· Интеграция ранее разъединенных детализированных данных:
· Разделение наборов данных используемых для операционной обработки и наборов данных используемых для решения задач анализа.
Хранилища данных строятся на базе клиент-серверной архитектуры, реляционной СУБД и утилит поддержки принятия решений.
Существуют два архитектурных направления – нормализованные хранилища данных и размерностные хранилища.
В нормализованных хранилищах, данные находятся в предметно ориентированных таблицах третьей нормальной формы. Нормализованные хранилища характеризуются как простые в создании и управлении, недостатки нормализованных хранилищ – большое количество таблиц как следствие нормализации, из-за чего для получения какой-либо информации нужно делать выборку из многих таблиц одновременно, что приводит к ухудшению производительности системы.
Размерностные хранилища используют схему "звезда" или "снежинка". При этом в центре звезды находятся данные (Таблица фактов), а размерности образуют лучи звезды. Различные таблицы фактов совместно используют таблицы размерностей, что значительно облегчает операции объединения данных из нескольких предметных таблиц фактов (Пример – факты продаж и поставок товара). Таблицы данных и соответствующие размерности образуют архитектуру "ШИНА". Размерности часто создаются в третьей нормальной форме (медленно изменяющиеся размерности), для протоколирования изменения в размерностях. Основным достоинством размерностных хранилищ является простота и понятность для разработчиков и пользователей, также, благодаря более эффективному хранению данных и формализованным размерностям, облегчается и ускоряется доступ к данным, особенно при сложных анализах. Основным недостатком является более сложные процедуры подготовки и загрузки данных, а также управление и изменение размерностей данных.
Процессы работы с данными
Источниками данных могут быть:
· Традиционные системы регистрации операций (БД)
· Отдельные документы
· Наборы данных
Источники данных классифицируются:
· Территориальное и административное размещение.
· Степень достоверности.
· Частота обновляемости.
· Система хранения и управления данными.
Операции с данными:
· Извлечение – перемещение информации от источников данных в отдельную БД, приведение их к единому формату.
· Преобразование – подготовка информации к хранению в оптимальной форме для реализации запроса, необходимого для принятия решений.
· Загрузка – помещение данных в хранилище, производится атомарно, путем добавления новых фактов или корректировкой существующих.
· Анализ – OLAP, Data Mining, Reporting и т. д.
Deductor Warehouse
Deductor Warehouse – многомерное кросс-платформенное хранилище данных, аккумулирующее необходимую для анализа предметной области информацию. Использование единого хранилища позволяет обеспечить удобный доступ, высокую скорость обработки, непротиворечивость информации, централизованное хранение и автоматическую поддержку всего процесса анализа данных.
При работе с хранилищем данных от пользователя не требуется знание структуры хранения данных и языка запросов. Он оперирует привычными бизнес-терминами – отгрузка, товар, клиент. Для импорта из хранилища нужно всего лишь вызвать мастер и выбрать, какого рода информацию хотелось бы получить. Все необходимые для извлечения данных операции будут произведены автоматически.
Вся информация хранится в схемах типа "снежинка", где в центре расположены таблицы фактов, а «лучами» являются измерения. Каждая "снежинка" описывает определенное действие, например, продажи товара, отгрузки, поступления денежных средств и прочее.
Пример проектирования структры ХД
Имеется история продаж различных товаров по дням в нескольких торговых объектах. Товары объединены в группы. Все данные можно представитьв в виде 4 таблиц: Товарные группы, Товары, Отделы, Продажи.
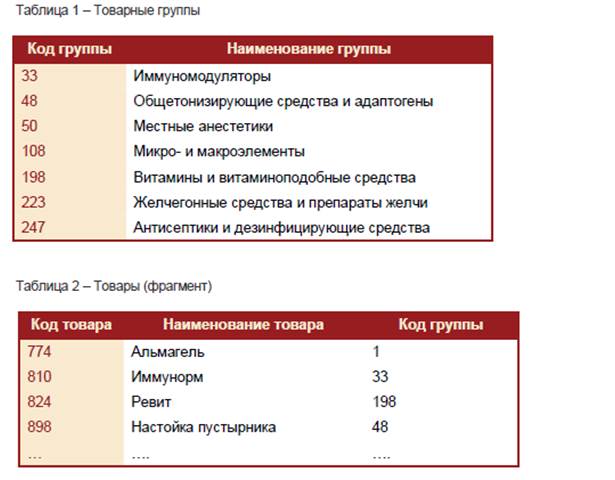
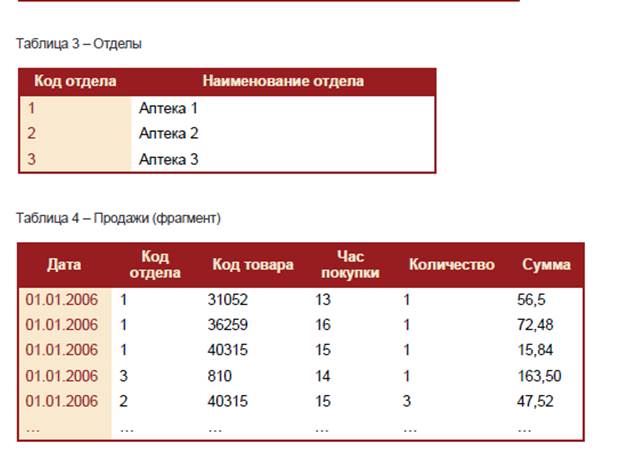
В таблице 1 Код группы – измерение, Наименование группы– его атрибут.В таблице 2 Код товара – измерение, а Наименование товара – его атрибут.В таблице 3 Код отдела – измерение, а Наименование отдела – его атрибут.В таблице 4 Дата, Отдел, Код товара, Код группы, Час покупки – измерения, а Количество и Сумма – факты, т.к. таблица 4 является описанием процесса продаж в трех аптеках.
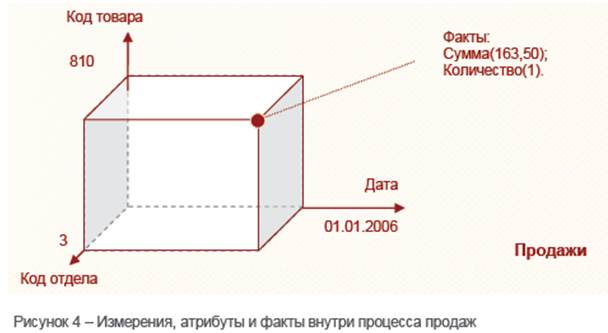
Измерения могут быть как простыми списками, например, дата, так и содержать дополнительные столбцы, называемые атрибутами. Например, измерение Товар может состоять из "Наименование товара" – собственно измерение (первичный ключ), а "Вес", "Объем" и прочее – его атрибуты. Иногда измерения могут быть связаны с другими измерениями.
Загрузка данных в Deductor Warehouse производится при помощи Deductor Studio либо Deductor Server, причем данную операцию можно произвести с любыми данными, импортированными или обработанными программой. Это обеспечивает широкие возможности – до загрузки можно провести весь цикл предобработки и очистки, например, удалить аномальные значения, заполнить пропуски и загрузить в хранилище очищенные и необходимым образом трансформированные данные.
Deductor Warehouse может строиться на базе одной из трех СУБД: Oracle, MS SQL или Firebird. Выбор информации из хранилища производится при помощи Мастера импорта: пользователь просто выбирает, какие данные из имеющейся в хранилище его интересуют, а система самостоятельно формирует специфичный для каждой СУБД SQL запрос. Работа с любой из баз данных происходит совершенно прозрачно для пользователя.

Вне зависимости от используемой СУБД семантический слой остается единым для любого хранилища. Благодаря этому можно с минимальными усилиями строить иерархические хранилища данных, витрины данных, комбинировать их произвольным образом, применяя наиболее пригодную для конкретного случая базу данных. Это дает возможность минимизировать совокупную стоимость системы, не жертвуя производительностью.
Deductor Warehouse оптимизирован для решения именно аналитических задач, что гарантирует высокую скорость доступа. При загрузке данных автоматически производятся все необходимые для получения наилучшего качества операции. Кроме того, процедуру загрузки в хранилище можно запускать автоматически ночью или в любое другое время, когда сервер наименее занят.
Deductor Warehouse является идеальным местом хранения аналитических данных:
· Централизованное хранилище
· Оптимизированный доступ
· Непротиворечивость данных
· Использование бизнес-понятий для доступа к информации
· Автоматическое обновление.
Хранилище данных оптимизировано для решения задач анализа, поэтому при загрузке автоматически выполняются все необходимые действия:
· Данные преобразовываются из плоских таблиц в многомерное представление, наилучшим образом подходящее для анализа данных.
· Исключаются все дублирующиеся данные для уменьшения объемов базы данных.
· Обеспечивается непротиворечивость информации.
· Проводятся все требуемые манипуляции, позволяющие в последствии в 10-100 раз увеличить скорость извлечения данных из хранилища.
Использование хранилища данных не является обязательным при анализе. Все необходимые действия в Deductor Studio можно провести с любыми табличными данными, однако применение Deductor Warehouse позволяет значительно ускорить создание законченного решения, обеспечить более высокую производительность и сделать проще работу с информацией конечным пользователям.